
Block Storage Performance in der Cloud: I/O-Latenzzeiten im Vergleich
Die großen Cloud-Provider ähneln sich im Umfang und bei den Leistungsdaten ihrer Block-Storage-Optionen im Infrastructure-as-a-Service- (IaaS-) Umfeld. Doch der Teufel liegt wie immer im Detail. Neben den auf den ersten Blick wichtigen Performance-Werten IOPS und maximaler Durchsatz (throughput), die von den Cloud-Providern detailliert aufgeschlüsselt und beworben werden, spielt in vielen Szenarien allerdings auch die Latenz eine entscheidende Rolle. Diese wiederum wird von den Providern zwar einheitlich als „niedrig" beworben, aber selten mit konkreten Werten hinterlegt.
Wir haben für einen unserer Kunden die Migration einer auf DB2 basierenden Anwendung von AWS nach Azure geplant und durchgeführt. Bei Performance-Tests in der Zielumgebung hat sich in dem Zuge herausgestellt, dass bei Azure deutlich weniger Datenbank-Transaktionen im gleichen Zeitraum erreicht werden konnten als bei AWS. Nach eingehender Analyse konnten wir aufzeigen, dass dies auf die deutlich höhere Latenz des gewählten Block-Storage-Typs bei Azure zurückzuführen ist. Wie die Mitbewerber wirbt jedoch auch Microsoft mit "konsistent niedrigen Latenzen" (https://docs.microsoft.com/de-de/azure/virtual-machines/premium-storage-performance#latency). Ausgehend von unseren Beobachtungen haben wir daher die Latenzen verschiedener Block-Device-Typen der Provider Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, Open Telekom Cloud (OTC) und Oracle Cloud Infrastructure (OCI) eingehend untersucht und verglichen. Die Ergebnisse waren aufschlussreicher, als wir vorher selbst vermutet hatten.
Was ist Storage-Latenz?
Mit Latenz (auch „response time" genannt) wird im Storage-Umfeld die Zeitdauer bezeichnet, die ein einzelner I/O-Request zur Verarbeitung benötigt. Gemessen wird dabei die Zeitspanne zwischen dem Versand des Requests an das Storage-System bis zum Eintreffen der Bestätigung, dass die Dateien geschrieben wurden (bei Write-Requests), bzw. bis zum Erhalt der angeforderten Daten (bei Read-Requests).
Aber ergibt sich die Latenz nicht aus den IOPS?
Bei all diesen Angaben ist zudem darauf zu achten, dass sich sowohl die Latenz als auch die IOPS immer auf eine bestimmte Art von Request beziehen, d.h. folgende Parameter müssen bei Angabe der Werte eigentlich immer mit genannt werden (auch wenn dies seitens der Anbieter häufig nicht getan wird, sondern stattdessen lieber einfach stillschweigend die Werte für den „best case" publiziert werden):
- Größe der Datenblöcke pro Operation
- Lese- oder Schreiboperation (read vs. write)
- Sequentielle oder zufällige Zugriffe (sequential/linear vs. random)
- Anzahl paralleler Requests (queue depth)
Warum und wann ist Latenz wichtig?
Insbesondere bei synchronen Schreibvorgängen ist die Latenz ein entscheidender Faktor. Dies ist z. B. im Datenbankumfeld beim Schreiben von Transaktionsprotokollen der Fall. In Anwendungsszenarien mit sehr kleinen Transaktionen, die häufig in zeitkritischen Applikationen verwendet werden, stellt dies unter Umständen einen limitierenden Faktor dar. Jeder Commit löst einen synchronen Schreibvorgang aus, der erst erfolgreich an die Applikation zurückgemeldet wird, wenn auch die Bestätigung für den erfolgreichen I/O durch das Storage-System erfolgt ist.
Dies ist auch genau der Anwendungsfall, der bei unserem Kunden aufgetreten ist. Im Vorfeld der Migration haben wir generische Performance-Tests durchgeführt. Dies war im Datenbankumfeld zum Beispiel ein Import, bei dem jeder Datensatz einzeln committet wurde, um die Performance beim Schreiben des DB2-Online-Logs zu testen.
Testaufbau
Damit die Ergebnisse vergleichbar sind, haben wir bei allen Cloud-Providern Standard-Instanzen mit 4 CPUs und 16 GB RAM gewählt und einheitlich Ubuntu 20.04 LTS als Linux-Distribution verwendet. Die Instanzen wurden jeweils in einem in Deutschland befindlichen Rechenzentrum bereitgestellt. Auf den Systemen liefen keine weiteren Dienste, mit Ausnahme derer, die standardmäßig mit dem Betriebssystem gestartet werden. Die Größe der zu testenden Volumes wurden so gewählt, dass die laut Service-Beschreibung der Cloud-Provider maximale mögliche Anzahl IOPS und der maximale Durchsatz die Testergebnisse nicht verfälschen – es sollte also sichergestellt sein, dass die Latenz der limitierende Faktor bei den Messungen ist.
Um die Nachvollziehbarkeit der Messungen sicherzustellen wurde das bekannte Tool FIO (Flexible IO Tester - https://fio.readthedocs.io/) genutzt, welches von vielen Cloud-Providern explizit zum Test der I/O-Performance empfohlen wird. Wir haben das folgende Job-File für die Tests verwendet:
[test_latency]
direct=1
iodepth=1
ioengine=sync
refill_buffers
bs=8k
ramp_time=10s
runtime=60s
time_based
rw=randwrite
filename=<PATH_TO_BLOCK_DEVICE>
- Durchschnittliche Latenz
- Standardabweichung der Latenz
- IOPS
- Durchsatz/Throughput
Die Ergebnisse im Detail
Die nachfolgende Tabelle zeigt unsere Messwerte für die einzelnen Cloud-Provider und Storage-Typen. Der Vollständigkeit halber und zum Vergleich haben wir zudem die zum Zeitpunkt der Messung (02/2021) gültigen monatlichen Kosten für die verwendeten Instanzen und Storage-Varianten aufgeführt.
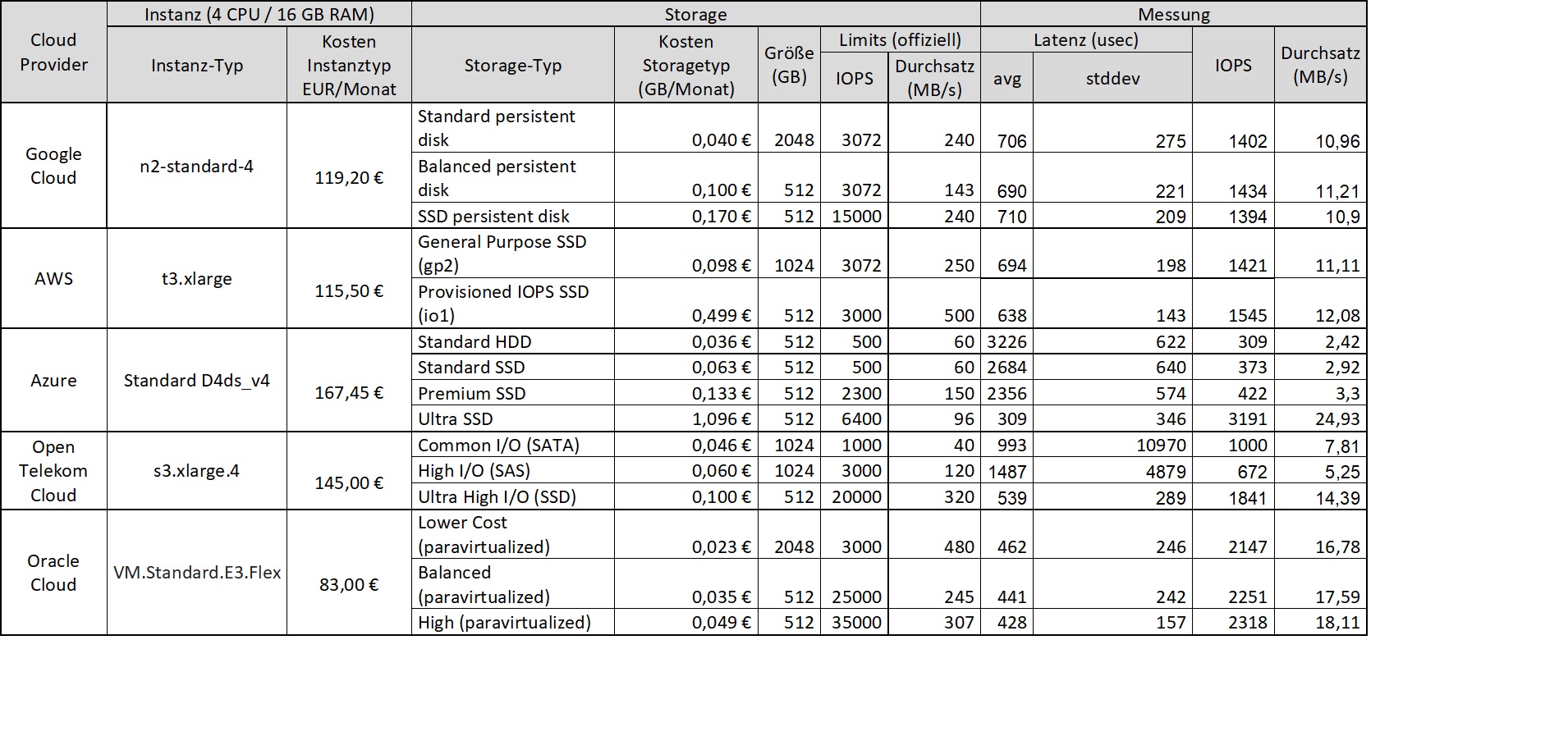
Die gemessenen, durchschnittlichen Latenzen zeigt das folgende Diagramm im Vergleich:
Es sind also deutliche Unterschiede sowohl zwischen den einzelnen Cloud-Providern als auch zwischen deren unterschiedlichen Storage-Typen zu erkennen.
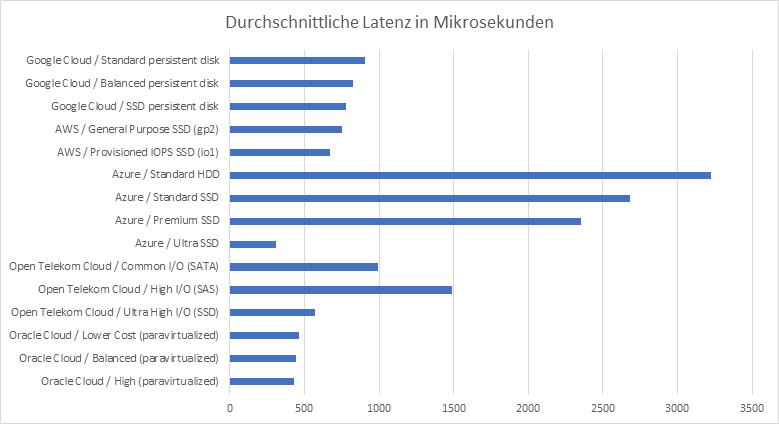
Um die maximale Anzahl an IOPS als limitierenden Faktor für die Messung auszuschließen, haben wir zudem explizit das Verhältnis von gemessenen zu – laut Cloud-Provider – maximal zu erwartenden IOPS überprüft:
Es zeigte sich also, dass beim Storage-Typ „Common I/O" der Open Telekom Cloud bei diesem Vergleich die feste Obergrenze von 1000 IOPS der limitierende Faktor war, denn genau diesen Wert erreichten wir auch bei der Messung. Aus diesem Grund sind die gemessenen Latenzwerte hier also durch die IOPS begrenzt und somit nur bedingt vergleichbar bzw. als Maximalwert zu betrachten. Bei allen anderen Kombinationen war dies jedoch nicht der Fall – hier sollte tatsächlich wie gewünscht die Latenz der limitierende Faktor gewesen sein.
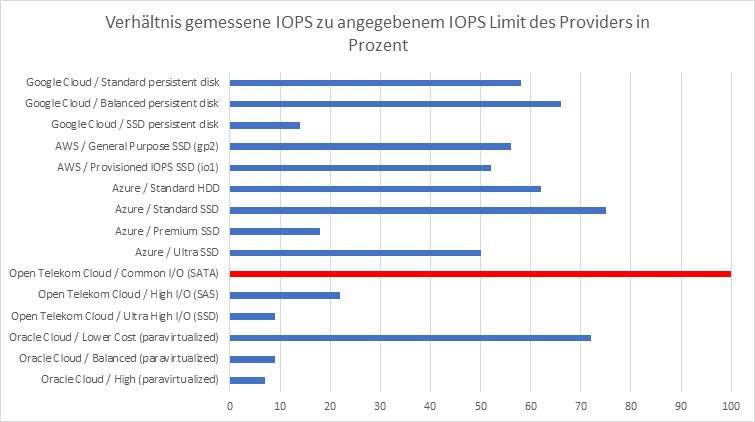
Neben der durchschnittlichen Latenz ist auch interessant, wie groß die Abweichungen von diesem Durchschnittswert sind, d.h. mit welcher „Streuung" bei der Laufzeit der Requests zu rechnen ist. Auch hier ergeben sich teilweise signifikante Unterschiede zwischen den Cloud-Providern und deren Storage-Optionen, wie in der folgenden Abbildung ersichtlich.
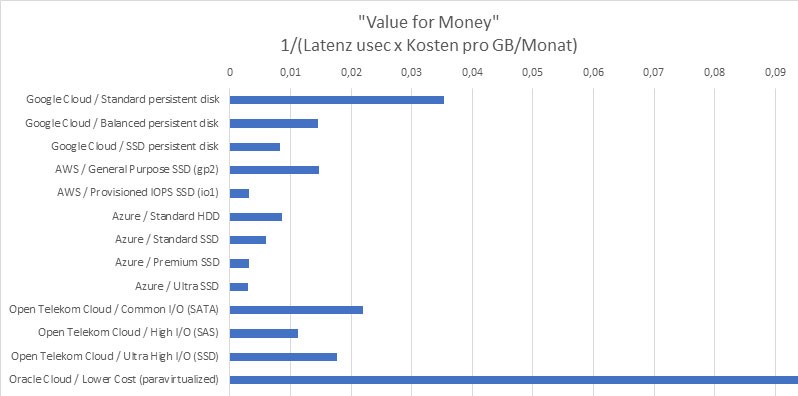
Am Ende der Betrachtung haben wir uns den „Value for Money" Faktor (Preis-Leistungsverhältnis) bezogen auf die Latenz angesehen, d.h. die Kosten der unterschiedlichen Storage-Varianten im Verhältnis zur gemessenen Latenz. Die folgende Abbildung zeigt das Ergebnis dieser Betrachtung und verdeutlicht auch hier die teils erheblichen Unterschiede.
Diskussion der Ergebnisse und Fazit
Von außen betrachtet ähneln sich die Block-Storage-Services der Cloud-Provider in vielen Punkten. Jedoch gibt es schon bei den beworbenen oder zumindest ausgewiesenen Leistungsdaten wie der maximalen Anzahl an I/O-Operationen oder dem maximalen Durchsatz pro Sekunde erhebliche Unterschiede. Dies ist in einem noch größeren Umfang für die in diesem Artikel untersuchte Latenz der Fall. Über alle Anbieter hinweg lässt sich jedoch sagen, dass die teureren Volume-Typen in der Regel tatsächlich auch die geringere Latenz bieten, und dass jeder Anbieter Storage-Typen im Angebot hat, die befriedigend niedrige Latenzen aufweisen. Die Kosten für Block Storage unterscheiden sich allerdings bei den einzelnen Providern erheblich, insbesondere wenn die Anwendungen auf niedrige Latenzen angewiesen sind. Bei der Auswahl des Cloud-Providers und des Storage-Typs sollte daher immer auch die Art der I/O-Operationen betrachtet werden, welche für die zu betreibenden Anwendungen besonders relevant sind. Der Kunde, dessen Migrationsprojekt Ausgangspunkt für diesen Artikel war, hat die Migration zu Azure letztendlich trotz der höheren Latenzen bei den Standard- und Premium-Volumes durchgeführt, da die erreichte Anzahl an Transaktionen pro Sekunde für die zu migrierende Anwendung zwar deutlich geringer ausfiel als vorher bei AWS, aber letztendlich dennoch als ausreichend beurteilt wurde.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Cloud? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Cloud Seminaren
Principal Consultant bei ORDIX
Kommentare