
Von 0 auf Kubernetes - Aufbau einer Kubernetes-CI/CD-Infrastruktur per GitLab-Pipeline - Teil 1 - Grundlagen
Rancher, Ansible, Terraform, GitLab und etwas Magie: Wie ich eine ganze Infrastruktur auf Knopfdruck erstelle.
In dieser Serie möchte ich euch zeigen, wie ihr automatisiert ein Kubernetes-Cluster aufbaut, ein GitLab mit GitLab-Runner installiert und eine eigene Docker-Registry zur Verfügung stellt. Das Ziel wird sein, dass ihr eure Anwendungen direkt aus dem GitLab heraus in eurem Cluster bauen und starten könnt.
Im ersten Teil dieser Serie möchte ich euch die Voraussetzungen aufzeigen und erklären, wie ihr eure Server auf ihre bevorstehenden Aufgaben vorbereitet. Wir werden einige Konfigurationen vornehmen und Docker installieren.
Benötigte Vorkenntnisse
Falls ihr euch in diesen Technologien noch nicht so gut auskennt, sie grundsätzlich neu für euch sind, oder ihr euer Wissen noch einmal auffrischen wollt, so kann ich euch folgende Blog-Artikel des ORDIX-Blogs oder Tutorials empfehlen:
Voraussetzungen
Als Erstes benötigen wir ein GitLab, welches die Ausführung von CI/CD Pipelines über einen GitLab-Runner ermöglicht. In diesem GitLab werden wir unseren Code verwalten und unsere Pipeline starten, die am Ende die gesamte Infrastruktur erstellt.
Dann brauchen wir natürlich noch einige Maschinen, auf denen wir unsere Infrastruktur installieren und betreiben können. Ich würde euch empfehlen hier auf mindestens vier Server oder Virtuelle Maschinen (VMs) zurückzugreifen. Unsere spätere Infrastruktur würde zwar auch auf weniger Maschinen laufen, allerdings möchte ich direkt zeigen, wie sich diese auf mehrere Knoten skalieren lässt. Für die Ausstattung der Maschinen solltet ihr euch an den Angaben dieser Tabelle orientieren. Zusätzlich benötigt ihr noch root-Zugriff per SSH auf die Maschinen. Da diese Zugriffe später automatisiert stattfinden sollen, empfehle ich euch, einen SSH-Key für alle Maschinen einzusetzen.
Ich werde im Folgenden mit vier VMs arbeiten, auf denen Ubuntu 20.04 LTS installiert ist. Falls das für euch keine Option ist, dann findet ihr hier eine Übersicht über alle mit unserer genutzten Software kompatiblen Betriebssysteme und deren Versionen. Eventuell müsst ihr dann Teile dieser Anleitung an euer Betriebssystem anpassen.
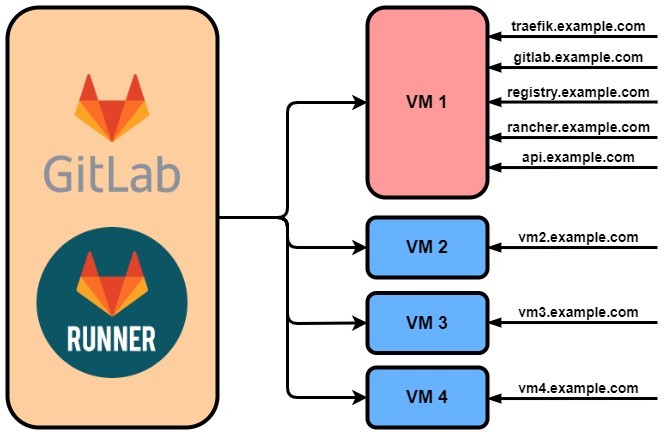
Als Letztes solltet ihr einige Hostnamen bzw. DNS-Einträge nach folgendem Schema festlegen:
Hostname Ziel
gitlab.example.com VM1
registry.example.com VM1
rancher.example.com VM1
api.example.com VM1
traefik.example.com VM1
vm2.example.com VM2
vm3.example.com VM3
vm4.example.com VM4
Zur besseren Übersicht hier eine kleine Visualisierung:
Die Open Telekon Cloud
Konkret arbeite ich mit vier VMs in einem separaten, privaten Labor-Netzwerk innerhalb der Open Telekom Cloud (OTC), was seine ganz eigenen Probleme mit sich brachte. Zum einen war in diesem Labor-Netzwerk keine direkte HTTPS-Kommunikation mit dem Internet möglich, sondern nur über einen Proxy, weshalb es hier auch darum gehen wird, wie ein Corporate Proxy konfiguriert wird. Zum anderen sind die angelegten Hostnamen nicht öffentlich auflösbar und nur dem internen DNS-Server bekannt. Diesen werden wir in unserer Infrastruktur ebenfalls als Nameserver hinterlegen müssen.
Das Arbeiten mit der OTC bzw. in einem derart abgeschotteten Netzwerk ist selbstverständlich keine Voraussetzung für diese Anleitung. Sollten die gerade genannten Besonderheiten in eurem Fall nicht existieren, so könnt ihr die entsprechenden Schritte der Anleitung einfach überspringen.
Die erste Ansible-Rolle
Wie in diesem ORDIX-Blog-Artikel beschrieben, bietet sich Ansible für die Installation der benötigten Komponenten an. Wie ihr am Ende meiner Artikelserie sehen werdet, wird Ansibles Rollenkonzept uns dabei helfen, eine gut leserliche Struktur in unseren Code zu bringen.
Das Ziel für diesen ersten Teil wird es sein, einige Konfigurationen vorzunehmen und Docker zu installieren. Da wir diese Aufgaben auf jeder VM durchführen wollen, erscheint es sinnvoll, dafür eine Ansible-Rolle namens common zu erstellen.
Zu Beginn generieren wir uns in besagtem GitLab ein neues Repository und erstellen hierin für unsere Ansible-Rolle eine main.yml in folgendem Pfad:
ansible-setup/roles/common/tasks/main.yml
Hier werden wir nun unsere einzelnen Tasks definieren. Diese gehe ich nun schrittweise mit euch durch.
1. apt konfigurieren
Um Docker installieren zu können, ist es notwendig, dass "apt" über unseren Corporate Proxy mit dem Internet kommunizieren kann. Um dies zu erreichen, erstellen wir über das Modul blockinfile für "apt" eine neue Konfigurationsdatei, in der wir unseren Corporate Proxy als HTTP- und HTTPS-Proxy hinterlegen. Wie ihr im Folgenden sehen werdet, wird unser Proxy nur über eine Variable angegeben. Die genaue Belegung dieser Variable wird also später im Playbook, in dem diese Rolle verwendet wird, entschieden.
Da "apt" nun über unseren Proxy auf das Internet zugreifen kann, können wir einige für die Kommunikation über HTTPS benötigte Packages über das Modul apt installieren.
- name: Configure apt to use proxy
blockinfile:
create: true
path: /etc/apt/apt.conf.d/proxy.conf
mode: '0644'
block: |
Acquire::http::Proxy "{{ proxy }}";
Acquire::https::Proxy "{{ proxy }}";
- name: Install packages that allow apt to be used over HTTPS
apt:
name: "{{ packages }}"
state: present
update_cache: true
vars:
packages:
- apt-transport-https
- ca-certificates
- curl
- gnupg-agent
- software-properties-common
2. Docker installieren
Nachdem "apt" korrekt konfiguriert wurde, können wir mit der Docker-Installation beginnen.
Um das Docker Repository zur Installation der Software nutzen zu können, benötigt "apt" erst dessen signierten Schlüssel. Diesen fügen wir per Modul apt_key hinzu. Anschließend registrieren wir das zu unserem Betriebssystem passende Docker Repository per apt_repository. Nun installieren wir, analog zu unserem zweiten Task, Docker über das Modul apt. Weiterhin füge ich per Modul user den auf den VMs aktiven Benutzer (in meinem Fall "ubuntu") zur Benutzergruppe "docker" hinzu, damit dieser alle Docker-Befehle ohne Beschränkungen ausführen darf.
Beim Betrachten des folgenden Codes wird euch vermutlich auffallen, dass wir hier eine feste Docker-Version installieren. Dies ist nötig, da unsere spätere Infrastruktur (konkret die von uns genutzte Kubernetes-Distribution) die aktuellste Version von Docker noch nicht unterstützt. Deshalb greife ich hier auf die neuste noch unterstützte Docker-Version zurück. Da sich dies in der Zukunft natürlich noch ändern kann, solltet ihr euch hier über die kompatiblen Docker-Versionen informieren.
- name: Add an apt signing key for Docker
apt_key:
url: https://download.docker.com/linux/ubuntu/gpg
state: present
- name: Add apt repository for stable version
apt_repository:
repo: deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable
state: present
- name: Install docker and its dependecies
apt:
name: "{{ packages }}"
state: present
update_cache: true
vars:
packages:
- docker-ce=5:19.03.14~3-0~ubuntu-focal
- docker-ce-cli=5:19.03.14~3-0~ubuntu-focal
- containerd.io
- name: Add ubuntu user to docker group
user:
name: ubuntu
group: docker
3. Docker konfigurieren
Nach der Installation ist vor der Konfiguration. Getreu diesem Motto werden wir unsere main.yml jetzt mit Tasks zur Docker-Konfiguration erweitern. Wir müssen erreichen, dass auch Docker über unseren Corporate Proxy kommunizieren kann und den Einsatz einer eigenen Docker-Registry (siehe spätere Artikel) vorbereiten.
Analog zur Konfiguration von "apt" hinterlegen wir unseren Corporate Proxy in einer Konfigurationsdatei für Docker. Neu an dieser Stelle ist allerdings, dass wir Docker dazu anweisen, keinen Proxy für alle privaten IP-Adressräume und all unsere selbst definierten Hosts (siehe Voraussetzungen) zu verwenden. Diese Zielsysteme sind in meinem Fall direkt erreichbar und entsprechende Anfragen müssen nicht über den Proxy geleitet werden. Auch dies kann sich stark zu eurem benutzten Umfeld unterscheiden.
Danach erstellen wir eine daemon.json, in der wir unsere eigene Docker-Registry (siehe spätere Artikel) als unsichere Registry (ohne Authentifizierung und über HTTP) angeben. Euch wird auffallen, dass wir die daemon.json vorher noch explizit löschen, falls diese bereits existiert. Dies ist aufgrund einer Besonderheit des Moduls blockinfile nötig. Ansible bzw. das Modul benutzt in Dateien gewisse Marker bzw. Zeichenketten, um bereits eingefügte Blöcke zu erkennen. Hier ein Beispiel:
# BEGIN ANSIBLE MANAGED BLOCK
Dies ist ein Text
# END ANSIBLE MANAGED BLOCK
Solch ein Marker würde der Syntax einer JSON-Datei widersprechen. Aus diesem Grund müssen wir beim Schreiben in die daemon.json das blockinfile Modul permarker: "" so einstellen, dass es keine Marker benutzt. Ohne Marker erkennt Ansible bzw. das Modul aber auch nicht mehr, ob es den entsprechenden Text bereits in die Datei geschrieben hat und würde bei nochmaligem Ausführen des Tasks den gesamten Blockinhalt erneut in die Datei schreiben, was ebenfalls die Syntax der JSON-Datei zerstören würde. So wäre folgendes keine gültige JSON-Datei:
{
"insecure-registries" : ["registry.example.com"]
}
{
"insecure-registries" : ["registry.example.com"]
}
Aus diesem Grund löschen wir die daemon.json, bevor wir sie erneut mit unserem gewünschten Inhalt erstellen. Da diese Datei standardmäßig nicht existiert und nur für besondere Nutzereinstellungen benötigt wird, ist dies eine valide Lösung für unseren Anwendungsfall.
Um den Inhalt der daemon.json von Docker einlesen zu lassen, müssen wir anschließend Docker per systemd Modul neustarten.
- name: Configure docker to use proxy
vars:
no_proxy: "127.0.0.0/8,\
10.0.0.0/8,\
172.16.0.0/12,\
192.168.0.0/16,\
traefik.example.com,\
gitlab.example.com,\
registry.example.com,\
vm2.example.com,\
vm3.example.com,\
vm4.example.com,\
rancher.example.com,\
api.example.com"
blockinfile:
create: true
path: /etc/systemd/system/docker.service.d/http-proxy.conf
mode: '0644'
block: |
[Service]
Environment="HTTP_PROXY={{ proxy }}"
Environment="HTTPS_PROXY={{ proxy }}"
Environment="NO_PROXY={{ no_proxy }}"
- name: Delete docker daemon.json
file:
path: /etc/docker/daemon.json
state: absent
- name: Configure docker to use insecure registry
blockinfile:
create: true
path: /etc/docker/daemon.json
mode: '0644'
marker: ""
block: |
{
"insecure-registries" : ["registry.example.com"]
}
- name: Restart docker to apply config
systemd:
name: docker
daemon_reload: true
state: restarted
Zusammenfassung
Wir haben hier unsere erste Ansible-Rolle namens common erstellt, die wir im späteren Verlauf in all unseren Playbooks nutzen werden und die das Grund-Setup unserer VMs erledigen kann. Docker wird installiert und "apt" und Docker werden so konfiguriert, dass sie unseren Corporate Proxy verwenden können. Wir bereiten Docker auf unsere eigene Docker-Registry vor und legen so eine Grundvoraussetzung für das noch kommende Kubernetes-Cluster.
Wer den bisherigen Fortschritt kurz validieren und testen möchte, der ist natürlich herzlich dazu eingeladen, ein kleines Ansible-Playbook zu schreiben. In dieser Anleitung werden wir allerdings erst später zu den eigentlichen Playbooks und der GitLab-Pipeline kommen, in der wir diese ausführen werden.
Im zweiten Teil erstellen wir uns eine docker-compose.yml, die uns ein neues GitLab (nicht mit dem GitLab zu verwechseln, in dem wir unseren Code verwalten und unsere Pipeline starten werden) mit zugehöriger Datenbank, eine eigene Docker-Registry und einen Traefik Reverse Proxy erstellen kann.

Consultant bei ORDIX.
Kommentare