
Man muss auch loslassen können – Anonymisierung im Data Warehouse
Im Data Warehouse Bereich steht das Speichern und Sammeln von Daten im Vordergrund. Jedoch benötigt man auch Strategien, um sich von nicht mehr benötigten Daten wieder zu trennen. Insbesondere wenn es sich um personenbezogene Daten handelt, für die es keine rechtliche Erlaubnis der Speicherung mehr gibt (anlassbezogene Datenhaltung). Es folgt ein Projektbericht über die Anonymisierung in einem Data Warehouse.
Die Anforderungen nach Löschungen oder Anonymisierungen können vielfältig und komplex sein. Je nach Branche und verarbeiteten Daten gibt es gesetzliche Aufbewahrungsfristen, die es zu berücksichtigen gilt. Aber auch der Kundenstatus spielt eine Rolle. Besteht mit dem Kunden ein Vertrag inklusive Datenverarbeitungsgenehmigung oder ist die Kundenbeziehung niemals über den Angebotsstatus hinausgekommen? In unserem Projekt unterscheiden wir drei Anforderungen:
- Ad hoc Löschungen von Interessenten im Auftrag des Betroffenen
- Löschung von Daten nach Wegfall des Zwecks der Verarbeitung (nach 90 Tagen)
- Löschung von Kundendaten nach Wegfall des Zwecks der Verarbeitung + nach gesetzlichen Aufbewahrungsfristen (10 Jahre nach Kontoschließung)
Löschen vs. Anonymisierung
Komplett loslassen wollen wir die Daten dann doch nicht. Die DSGVO fordert die Unkenntlichmachung schutzbedürftiger Daten, um sicherzustellen, dass die Daten nicht mehr auf ihre ursprüngliche Form zurückverfolgt werden können. Dadurch soll eine Identifikation von natürlichen Personen mit angemessenen Mitteln unmöglich gemacht werden. Dazu müssen die Daten nicht zwangsweise tatsächlich gelöscht werden. Eine Anonymisierung kann eine Lösung sein! So bleiben unsere mühselig angesammelten Daten und Datenkorrelationen im Data Warehouse bestehen und wir vermeiden komplexe Löschaktionen über diverse Linksatelliten in unserer Datenbank.
Aufbau des Datawarehouse
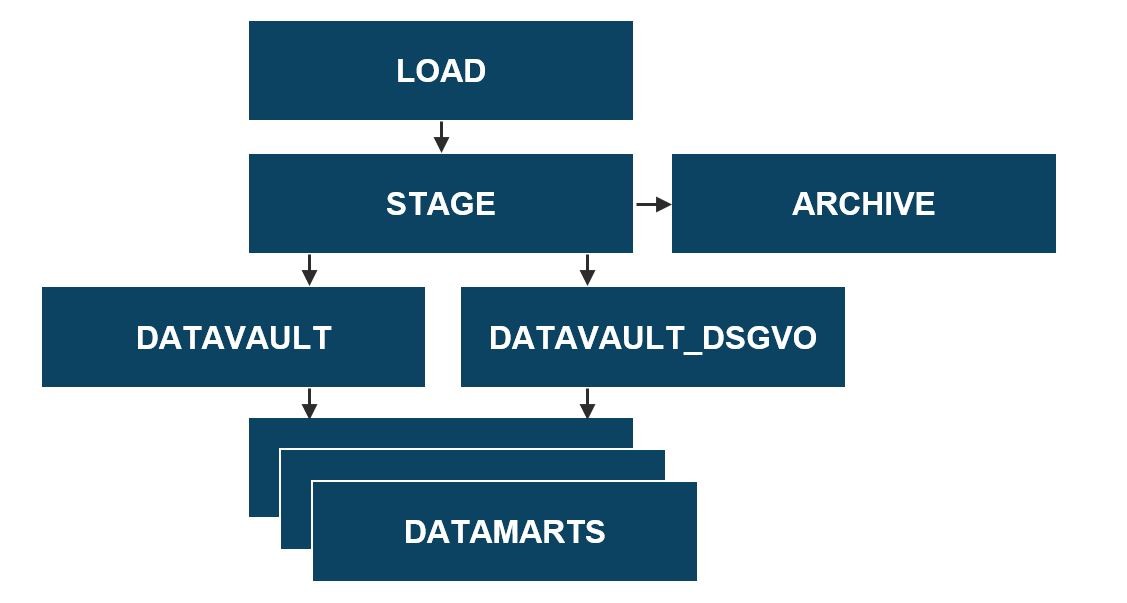
Unser Data Warehouse basiert auf den Grundprinzipien von DataVault und läuft auf einer Exasol-Datenbank. Ein Schichtmodell ist in Abbildung 1 dargestellt. In unserem DataVault betrachten wir die Schemata „DATAVAULT_DSGVO“ und „ARCHIVE“. Unsere LOAD- und STAGE-Schicht wird lediglich für eine temporäre Datenspeicherung der tagesaktuellen Daten im Rahmen der Tagesverarbeitung verwendet. Diese Schichten werden täglich geleert. In unserer CORE-Schicht sind keine DSGVO relevanten Inhalte gespeichert. Diese Informationen werden ausschließlich im Datenbankschema „DATAVAULT_DSGVO“ gespeichert und zusätzlich im Archiv, welches die letzten 100 Beladungen enthält. Unsere DATAMART-Schicht besteht lediglich aus Views und materialisierten Views, die entsprechend regelmäßig neu beladen werden. Da das Data Warehouse ein nachgelagertes System ist, brauchen wir uns nicht um die Quelldaten zu kümmern. Wenn wir Informationen über einen Kunden oder Interessenten erhalten, die anonymisiert werden müssen, ist diese Person bereits im Ursprungssystem anonymisiert und wird uns nur noch in dieser anonymen Form übermittelt. Es bleiben also die historischen Daten in unseren Satelliten und Archivtabellen.
Identifizierung der Daten – Metadatenmanagement ist Gold wert
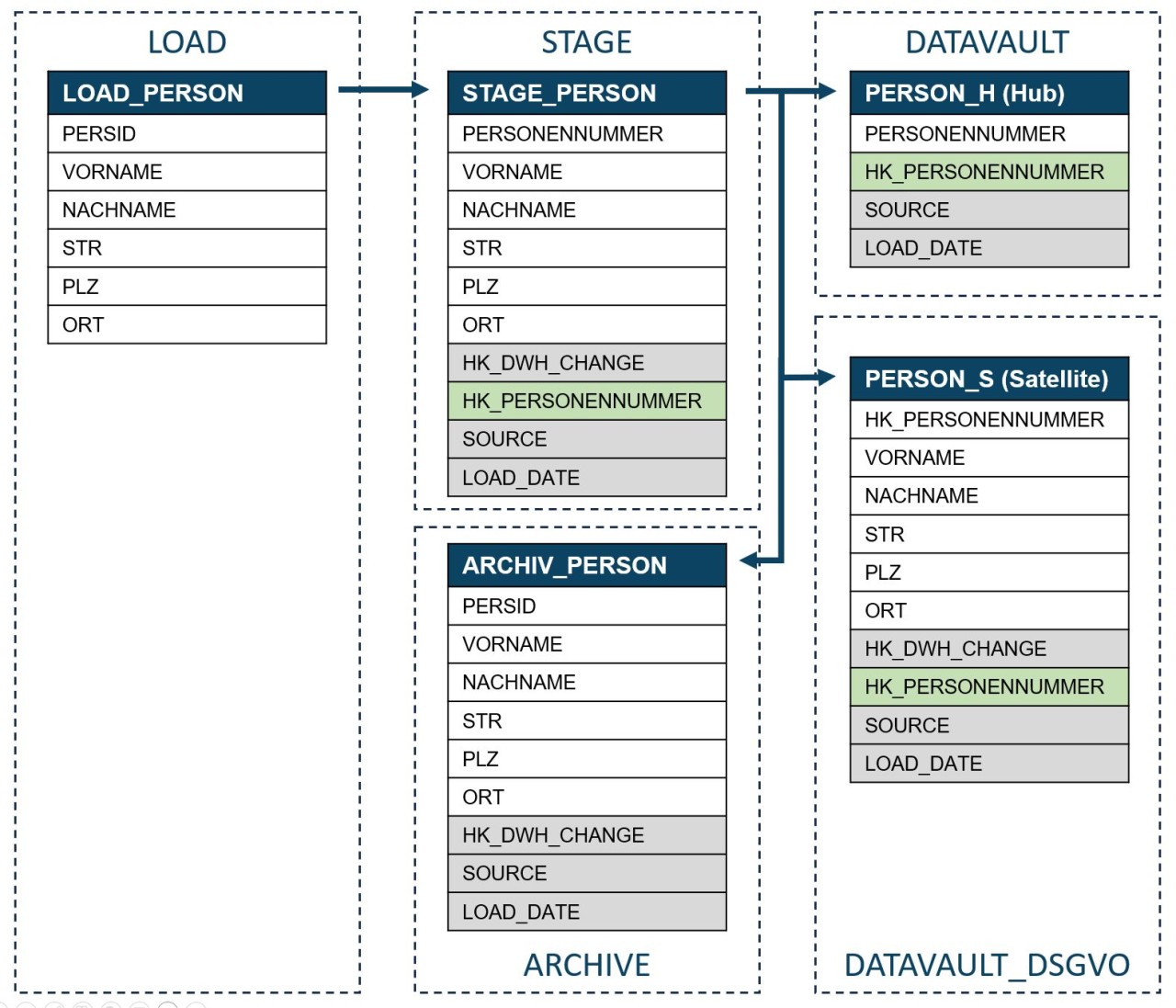
Die Identifizierung der zu anonymisierenden Spalten ist die erste Fleißarbeit. In unserem DataVault betrachten wir die Schemata DATAVAULT_DSGVO und ARCHIVE. Der geübte Data Analyst kennt seine Objekte und kann schnell eine erste Liste erstellen. Freitextfelder erfordern besondere Vorsicht und teilweise intensivere Analysen. Verwendungszwecke und Kommentarfelder neigen dazu, persönliche Daten zu enthalten und müssen daher ebenfalls genau untersucht werden. Hat man seine Metadaten gepflegt, ist der Sprung zwischen einem Objekt im DATAVAULT_DSGVO-Schema und dem korrespondierenden Objekt im ARCHIVE-Schema schnell gemacht. Siehe das entsprechende Beispiel in Abbildung 2.
Anonymisiert wird abhängig vom Spalteninhalt
Für jede betroffene Spalte legen wir eine spezifische Anonymisierungsmethode fest, die bestimmt, wie die Spalte anonymisiert werden soll. Einerseits ist es problematisch, Integer-Werte einfach durch Strings zu ersetzen, andererseits besteht möglicherweise der Wunsch, einige grundlegende Informationen beizubehalten. Die Informationen Tabelle, Spalte und Anonymisierungsart werden in einer Konfigurationstabelle abgelegt. Dabei unterscheiden wir:
- E-Mail-Adressen werden mit ANONYM@dummy.de ersetzt
- Datumswerte mit „01.01.YYYY“ wobei YYYY das Jahr des ursprünglichen Wertes widerspiegelt
- Postleitzahlen mit „10000“
- Bei IBANs wird lediglich die Kontonummer durch ein „X“ ersetzt. So bleibt die Information der zugehörigen Bank noch erhalten.
- Alle restlichen Varchar-Felder mit mehr als 5 Zeichen werden durch „ANONYM“ ersetzt
- Und alle DECIMAL-Felder oder Varchar-Felder mit weniger als 5 Zeichen durch 997.
Erstellen von Update-Prozeduren – Die eigentliche Arbeit
Sind die Spalten und Objekte identifiziert, wird es je nach Komplexität des Datenmodells etwas anstrengender. In unserem Fall haben wir die PERSONENNUMMER der zu anonymisierenden Datensätze. Diese wird von dem Stammdatensystem angeliefert und in eine Workload-View abgelegt. Die Workload-View beinhaltet neu zu anonymisierende Personen, die noch nicht anonymisiert wurden.
Die personenbezogenen Daten erstrecken sich über 24 Satellite-Tabellen in unserem DSGVO-DataVault-Schema sowie über 19 Tabellen in unserem Archive-Schema. Um die entsprechenden Datensätze zu identifizieren, ist eine Zuordnung eines Datensatzes aus jedem betroffenen Objekt zu einer PERSONENNUMMER erforderlich. Dies erfordert den Aufbau von JOIN-Ketten.
Beispiel (Abbildung 2): Um die Adresse einer zu anonymisierenden Person upzudaten, müssen wir über die Hub-Tabelle PERSON_H (hier ist die PERSONENNUMMER hinterlegt) über den Hashkey HK_PERSON_ID auf unseren Satelliten PERSON_S verknüpfen (joinen). Das klingt einfach und nachvollziehbar und das ist es in diesem Fall auch. Jedoch gibt es auch Daten aus anderen Quellsystemen, die erst über mehrere Link-Tabellen auf eine Personennummer verknüpft werden müssen.
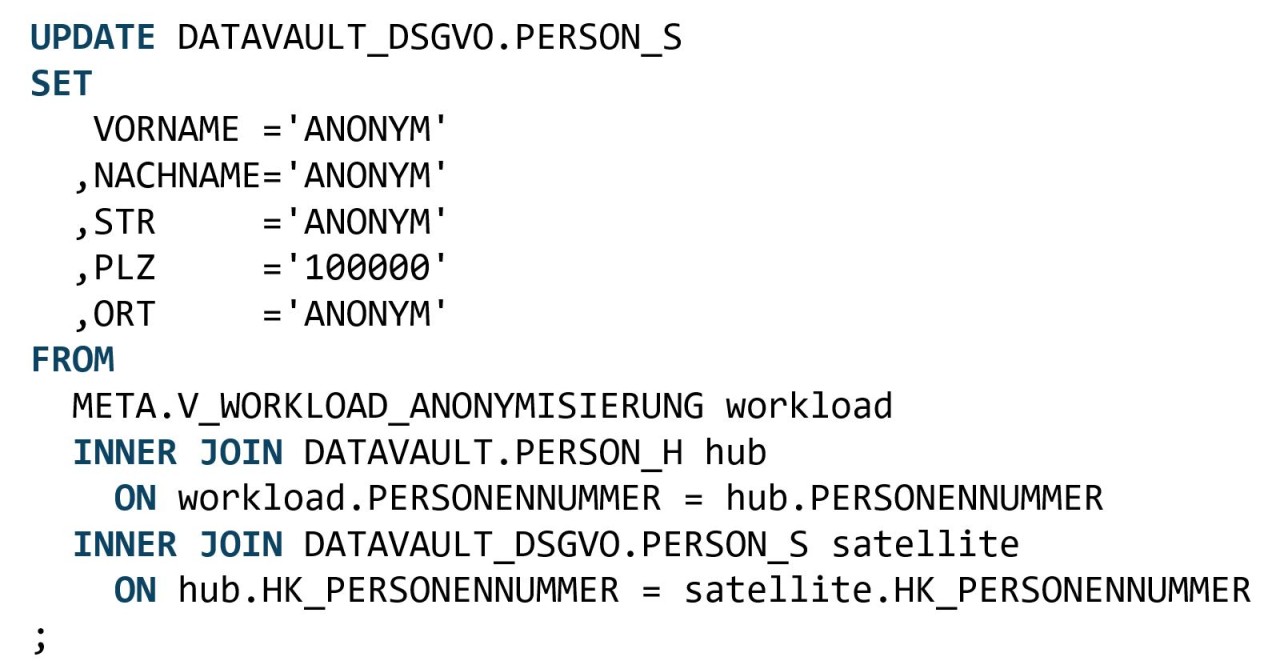
Ist die JOIN-Kette gebaut, kann aus der oben erwähnten Konfigurationstabelle für die Spalten der UPDATE-SET-Teil der Update-Statements dynamisch gebaut werden. Und fertig ist das UPDATE-Statement, bestehend aus dem UPDATE-SET-Teil und der JOIN-Kette. Die Updates für alle Objekte werden in einem SQL-Skript hinterlegt. Abbildung 3 zeigt ein solches Update.
Scheduling und Ablauf
Die Update-Prozedur wird täglich ausgeführt. Durch eine Protokollierung der Personennummern in einer Logging-Tabelle wird eine Auditing-Möglichkeit für den DSGVO-Beauftragten hergestellt. Zudem verrät uns das Log, welche Personennummern bereits anonymisiert wurden. Diese werden in der Workload-View exkludiert. Dadurch wird ein Datensatz nur einmal anonymisiert. Eine Überschreibungsmöglichkeit über eine Konfigurationstabelle bleibt jedoch bestehen: So kann die Anonymisierung für eine bereits anonymisierte Personennummer oder gar eine Vollanonymisierung aller Personennummern durch einen Konfigurationseintrag erneut erfolgen.
Was bleibt?
Kurz angeschnitten wurde das Auditing. Hier kann man tiefer ins Detail gehen. Ein Sneak Peak: Über QS-Views werden beispielsweise Objekte im DATAVAULT_DSGVO-Schema mit den konfigurierten Spalten in der Konfigurationstabelle abgeglichen. Gibt es neue DSGVO-relevante Objekte, für die noch keine Spalten mit REGEL_ID konfiguriert wurden, so wird das Entwicklerteam und der Datenschutzbeauftragte monatlich per Mail benachrichtigt. Ebenfalls gibt es Mailbenachrichtigungen über ausbleibende oder fehlgeschlagene Anonymisierungsläufe und vieles mehr.
Tückisch sind die erwähnten Freitextfelder. Im Rahmen der Umsetzung wurden hier auch noch einige Spalten im DATAVAULT erkannt, die vorab noch umgezogen werden mussten, in das DATAVAULT_DSGVO-Schema.
Auch die Eingliederung der Konfigurationspflege in den Regelprozess bedarf des ein oder anderen Sprints. Aber das bleibt nicht aus.
Inspiriert?
Benötigen Sie Unterstützung bei Ihrem Data Warehouse zum Bewahren der Compliance- und DSGVO-Vorgaben? Kontakten Sie uns und wir helfen Ihnen eine Strategie für ihr Projekt aufzustellen und umzusetzen. Gerne beraten wir Sie direkt.
Seminarempfehlung
DATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenSenior Consultant bei ORDIX
Kommentare