
Big Data – Informationen neu gelebt (Teil VI): Redis: Key Value einmal anders
Eingruppierung
Bei Redis (Remote Dictionary Server) handelt es sich um eine In-Memory-NoSQL-Datenbank, welche unter der Open-Source-Lizenz BSD entwickelt wird. Grundsätz-lich lässt sich die Datenbank den sogenannten Key ValueStores zuordnen. Dies bedeutet, dass ein Datensatz grundsätzlich auf Basis eines Keys eindeutig identifiziert wird und einen beliebigen Value besitzt.
Im Gegensatz zu klassischen KeyValue Stores zeichnet sich Redis durch die zusätzliche Unterstützung erweiterter Datenstrukturen aus. Aufgrund dieser Besonderheit bezeichnet sich das Projekt auch selbst viel mehr als sogenannter Data Structure Store. Ursprünglich wurde die Datenbank von Salvatore Sanfilippo im Jahre 2009 entwickelt, der seitdem durch Unternehmen wie VMware, Pivotal und Redis Labs aktiv dabei unterstützt wird. Seit jeher liegt der Fokus auf der Durchführung schneller Schreib- bzw. Leseoperationen und der platzsparenden Speicherung einfacher Datenstrukturen. Dies macht Redis vor allem für jene Anwendungsfälle interessant, in denen der Performanz eine übergeordnete Priorität zugeordnet wird. Hierzu zählen beispielhaft die temporäre Speicherung von Warenkorbinformationen eines Webshops, die Realisierung eines Customer Support Chats oder das Caching häufig abgefragter Informationen, wie die einer Benutzerkonfiguration.
Datenmodellierung
Mittels einer Liste kann eine beliebige Menge von Strings zu einem Key gespeichert werden. Bedingt durch die Implementierung, auf Basis einer verketteten Liste, bleibt der Aufwand beim Hinzufügen eines Strings am Anfang oder Ende der Liste konstant. Entsprechend eignet sich eine Liste gerade für Anwendungsszenarien, in denen eine hohe Anzahl an Strings sehr schnell hinzugefügt bzw. entfernt werden muss (zum Beispiel für die Kommentar-funktionalität eines Blogs). Weniger geeignet ist diese Datenstruktur für Anwendungsfälle, in denen ein freier Zugriff auf Elemente innerhalb der Liste erforderlich ist.
Ein Set dient der Speicherung eindeutiger Elemente innerhalb einer Menge von Strings. Gegenüber der Liste verfügt diese Datenstruktur über keine Möglichkeit des Zugriffes mittels eines Positionsindizes. Stattdessen wird über den String selbst zugegriffen. Beim Sorted Set wird jeder String um einen zusätzlichen Fließkommawert ergänzt. Dieser sogenannte Score ermöglicht eine sortierte Speicherung und in der Konsequenz die Durchführung effizienter Bereichsabfragen.
Die Datenstruktur Hash entspricht einer klassischen Hashtabelle und erlaubt die Ablage von separaten Key-Value-Paaren zu einem Key. Bedingt durch das zugrundeliegende Hashing eignet sich diese Datenstruktur vor allem in Anwendungsfällen, in denen Punktabfragen sehr schnell und zudem unabhängig von der darin enthaltenen Datenmenge erfolgen sollen.
Die Bitmap erlaubt einen Bit-weisen Zugriff auf Basis eines Positionsindizes und somit die platzsparende Speicherung von Informationen. Dies kann zum Beispiel dazu verwendet werden, Einstellungen von Nutzerprofilen (Newsletterja/nein, Funktion X ja/nein, ...) effizient zu speichern. Bedingt durch die Implementierung auf Basis des Strings, ergibt die maximale Größe von 512 MB eine Menge von bis zu 232 Bits innerhalb einer Bitmap.
Mit HyperLogLog verfügt Redis zudem über einen Datentypen, der dem effizienten Zählen eindeutiger Strings dient. Das Besondere hierbei ist, dass der Speicherbedarf unabhängig von der Menge zu zählender Strings ist und lediglich 12 KB beträgt. Möglich ist dies aufgrund der Implementierung des gleichnamigen Approximationsalgorithmus, welcher nicht die zu zählenden Strings selbst speichert, sondern auf einer probabilistischen Datenstruktur basiert. Sinnvoll ist die Verwendung von HyperLogLogs, sofern eine Abfrage der gezählten Strings selbst nicht erforderlich ist und eine Abweichung bei der Zählung von bis zu 0,81 % toleriert werden kann. Zu den möglichen Anwendungsszenarien zählt unter anderem das effiziente Zählen von Webseitenaufrufen durch eindeutig identifizierte Besucher.

Datenzugriff
Statt einer eigenen Abfragesprache verfügt Redis über eine komplexe API, welche für die unterschiedlichen Datenstrukturen separate Funktionsaufrufe bereitstellt. Die Implementierung spezialisierter Methoden erlaubt dem Entwickler stets jene Methode zu verwenden, welche im jeweiligen Anwendungskontext eine schnellstmöglicheAusführung erlaubt. Für den Zugriff auf die Daten-bank werden Bibliotheken zu mehr als 40 Programmiersprachen angeboten. Abgedeckt werden hierbei klassische Sprachen wie Java, Python, C++, C#, Scala, Perl und PHP, aber auch Exoten wie Matlab oder R.
Der Verzicht auf eine komplexe Abfragesprache wie SQL führt dazu, dass ein Teil der gewohnten Funktionalität (Selektion, Projektion, Gruppierung, Sortierung, analytischeFunktionen, ...) durch den Entwickler auf Anwendungsseiteentweder selbst implementiert werden muss oder durch die geeignete (ggf. redundante) Datenspeicherung in unter-schiedlichen Datenstrukturen erreicht werden kann. Letztlich führt somit der bei Redis gewonnene Gewinn an Performanz auf der anderen Seite häufig zu einem zusätzlichen Implementierungsaufwand und/oder einer erhöhtenAnwendungskomplexität. Um diesem Aspekt teilweise entgegenzuwirken, werden für einen Teil der Datenstrukturen charakteristische Zugriffsmethoden angeboten. So besteht unter anderem die Möglichkeit, Mengenoperationen,über mehrere (Sorted) Sets durchzuführen und somit entsprechende Schnitt-, Vereinigungs- oder Differenzmengen abzufragen. Darüber hinaus wurde zusätzlich ein Publish/Subscribe-Messaging-System integriert, welches bei Bedarf einen performanten Austausch von binary safe Strings zwischen den an der Datenbank angemeldeten Clients erlaubt. Durch diesen erweiterten Funktionsumfang kann zum Beispiel der oben erwähnte Anwendungsfall des Customer Support Chats elegant realisiert werden.
Architektur
Redis bedient sich einer ausgesprochen leichtgewichtigen Architektur und setzt neben einer Single-Thread-Verarbeitung auf eine In-Memory-Datenhaltung. Insbesondere der zweite Aspekt ermöglicht eine größtmögliche Performanz beim Datenzugriff aufgrund fehlender Zugriffe auf vergleichsweise langsame Sekundärspeicher, wie HDDs oder SSDs. Andererseits limitiert diese Designentscheidung die Größe der Datenbank auf den zur Verfügung stehenden Hauptspeicher.
Zur optimalen Ausnutzung des Hauptspeichers wurde bei der Entwicklung darauf geachtet, dass möglichst wenig Speicher durch das Datenbankmanagementsystem selbst benötigt wird. Entsprechend erfordert eine leere Redis- Instanz nur ca. 1 MB des Hauptspeichers.
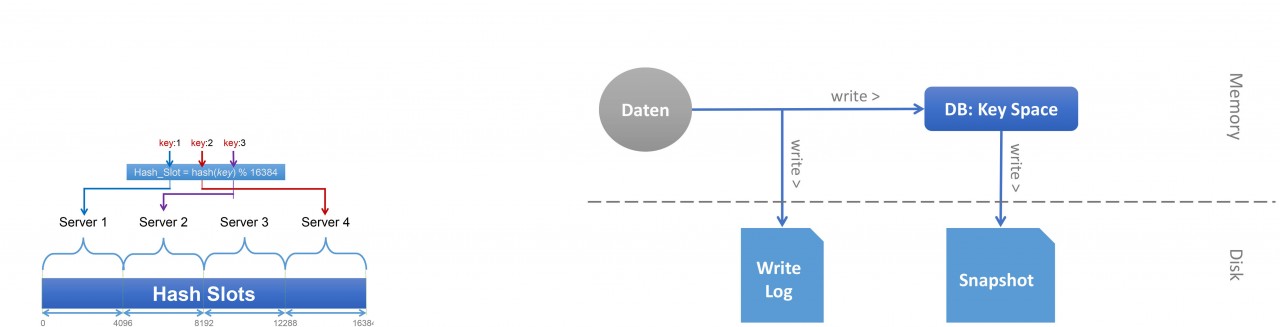
Für den Fall, dass die erforderliche Datenmenge den verfügbaren Hauptspeicher übersteigt, bietet die Redis- Cluster-Funktionalität eine Möglichkeit zur Verteilung der Datensätze auf mehrere Server. Jeder Server hält dabei exklusiv einen Teil der Key-Value-Paare, wobei die Verteilung über sogenannte Hash Slots erfolgt. Insgesamt existieren standardmäßig 16.384 Hash Slots, wobei jeder Server für einen Teil der Hash Slots verantwortlich ist. Um zu ermitteln, welches Key-Value-Paar zu welchem Hash Slot (und somit zu welchem Server) gehört, wird mittels einer Hash-Funktion der jeweilige Key auf einen numerischen Wert abgebildet, und anschließend mittels der Moduloperation auf den zugrundeliegenden Bereich von Hash Slots reduziert (siehe Abbildung 2). In der Folge ermöglicht dieses Verfahren eine effiziente Lastverteilung und kompensiert somit die sequentielle Verarbeitung, welche der Single-Threaded-Architektur geschuldet ist.
Trotz der reinen In-Memory-Datenhaltung bietet Redis auch zwei Möglichkeiten zur dauerhaften Datenspeicherung (siehe Abbildung 3). Zum einen existiert die Möglichkeit, einen Point-in-Time-Snapshot bei Bedarf oder automatisiert in zyklischen Abständen erstellen zu lassen. Hierbei wird der laufende Redis-Prozess innerhalb des Hauptspeichers kopiert, sodass dieser Prozess im Hintergrund einen konsistenten Snapshot auf den Sekundärspeicher schreiben kann, während der ursprüngliche Server-Prozess weiterhin unbeeinträchtigt (für lesende und schreibende Datenzugriffe) zur Verfügung steht. Bedingt durch das zugrundeliegende Copy-On-Write-Verfahren, werden initial keine Daten beim Kopieren des Redis-Prozesses dupliziert. Dies erfolgt erst, sobald Daten durch eingehende Anfragen geändert werden. In der Konsequenz wird somit sichergestellt, dass der erforderliche Hauptspeicher lediglich auf die doppelte Größe anwachsen kann, sofern während der Snapshot-Erstellung sämtliche Daten im Original verändert werden.
Zusätzlich zu dem Snapshot-Mechanismus verfügt Redis auch über eine dauerhafte Protokollierung von schreibenden Operationen, wodurch sich die Daten im Falle eines Absturzes oder eines geplanten Neustarts, ebenfalls wiederherstellen lassen. Je nach Anforderung kann diese Protokollierung so konfiguriert werden, dass jede Schreiboperation unmittelbar dauerhaft gesichert wird oder die Speicherung zugunsten der Performanz zyklisch erfolgt. Beide Verfahren zur dauerhaften Datenspeicherung sind optional und können bei Bedarf einzeln oder in Kombination verwendet werden. In Anwendungsfällen, in welchen Redis lediglich als temporärer Cache verwendetwird, können beide Varianten auch zugunsten der Performanz vollständig deaktiviert werden.
Um die Verfügbarkeit eines Redis-Clusters zu erhöhen, können die Daten eines Servers zu einem separaten Server repliziert werden. Bedingt durch die zugrunde-liegende Master-Slave-Architektur (siehe Abbildung 4) können schreibende Operationen jedoch nur über die Master Server erfolgen. Slave Server können im Fehler-fall den entsprechenden Master ersetzen und zusätzlich zur Skalierung lesender Abfragen verwendet werden. Bei einer größeren Anzahl von Slave Servern empfiehlt es sich, die Replikation kaskadierend zu organisieren (siehe Abbildung 5). Dies hat den Vorteil, dass ein Master Servernicht mehr zu all seinen Slave Servern die Daten direkt replizieren muss, wodurch dieser in der Folge weniger stark belastet wird. Es gilt jedoch zu beachten, dass die Replika-tion generell asynchron erfolgt und ein konsistenter Zugriff nur über den Master Server garantiert wird.
Security
Vielmehr begnügt es sich mit einer einfachen Passwortabfrage ohne Benutzerkennung und einer möglichen Einschränkung des zulässigen Netzwerk-Interfaces. Letztlich setzt es eine vertrauenswürdige Umgebungslandschaft voraus und überträgt somit die Verantwortung für die Sicherheit an die nutzende Anwendung und an eine restriktive Firewall.

Fazit
Die einfache Architektur und die solide Dokumentation erlauben einen einfachen Einstieg und schnelle erste Erfolge. Herausfordernd wird dagegen im weiteren Projektverlauf die geeignete Datenmodellierung, welche einerseits den Performanz-Anforderungen gerecht wird und andererseits zusätzliche Komplexität und unnötige Redundanzen vermeidet.
Glossar
BSD Lizenz
Bei der „Berkeley Software Distribution Lizenz" handelt es sich um eine Open Source Lizenz, welche es erlaubt, die darunter lizensierte Software frei zu kopieren, zu verändern und zu verbreiten, ohne dass das daraus resultierende Ergebnis selbst einer Open Source Lizenz unterliegen muss.
NoSQL
NoSQL steht für „Not only SQL" und bezeichnet eine Menge nicht relationaler Datenbanken, welche standardmäßig auf alternative Zugriffsmechanismen zu SQL setzen.
SQL
Die „Standard Query Language" ist eine Abfragesprache für relationale Datenbanken.
Links/Quellen
[1] Downloadseite Redis https://github.com/antirez/redis
[Q1] Produktseite der Redis-Datenbank https://redis.io/
Bildnachweise
© istockphoto.com | cybrain | Globale Datenspeicherung
Kommentare