
Big Data – Informationen neu gelebt (Teil VIII): Hadoop Security
Einleitung
Rechtevergabe im HDFS
Innerhalb des HDFS können auf Verzeichnisse und auch auf einzelne Dateien verschiedenste Zugriffsrechte vergeben werden. Diese verhalten sich ähnlich wie die Zugriffsrechte im Linux-Betriebssystem. So können beispielsweise Read-, Write- und Execute-Rechte vergeben werden. Diese Rechte können dann noch einmal einzeln für den Besitzer der Datei, für eine spezifische User-Gruppe und für alle restlichen Nutzer vergeben werden. Einen Unterschied zu den POSIX-Rechten gibt es jedoch, und zwar das Verhalten des Execute-Rechts. Im HDFS ist es nicht möglich, eine Datei auszuführen. Somit wird diese Berechtigung ignoriert, sobald sie auf eine einzelne Datei gesetzt ist. Bei Ordnern spielt diese Berechtigung jedoch eine sehr wichtige Rolle, da über diese Berechtigung gesteuert werden kann, ob ein Benutzer Zugriff auf die darunterliegenden Ordner und Dateien hat und beispielsweise ein ls ausführen darf. [Q1]
hdfs dfs -ls /user/ordix/testdatei.txt
Found 1 items
-rw-r--r-- 1 ordix hdfs 34 2018-01-29 14:16 /user/ordix/testdatei.txt
hdfs dfs -cat /user/ordix/testdatei.txt
Hallo liebe ORDIX® news-Leser. :-)
Die einzelnen Rechte können dabei über die Kommandos chown und chmod verändert werden (ein Beispiel ist im nächsten Listing dargestellt). Auch an dieser Stelle verhält sich das HDFS wieder äquivalent zum Linux-Betriebssystem. Somit können die Berechtigungen mittels Okatalnotation oder über die Angabe der Berechtigung (z. B. +r für die Leseberechtigung aller User) gesetzt werden. Die Anpassungen können dabei von dem HDFS-Superuser (standardmäßig ist dies der User hdfs) oder dem Besitzer der Datei durchgeführt werden. Dabei gibt es allerdings eine kleine Einschränkung: Der Besitzer einer Datei kann nur von dem HDFS-Superuser geändert werden. Falls die chown-Operation von einem „normalen" User ausgeführt wird, bekommt dieser eine Fehlermeldung. [Q2]
hdfs dfs -cat /user/ordix/testdatei.txt
Hallo liebe ORDIX® news-Leser. :-)
hdfs dfs –chmod 000 /user/ordix/testdatei.txt
hdfs dfs -cat /user/ordix/testdatei.txt
cat: Permission denied: user=ordix, access=READ, inode="/user/ordix/testdatei.txt": maria_dev:hdfs:----------
Rechtevergabe mittels Access Control Lists (ACL)
Da jedoch eine Vergabe von Rechten auf der Ebene Besitzer, User-Gruppe und Rest der Welt gerade in Hinsicht der Nutzung von Hadoop bzw. genauer des HDFS als sogenanntem Data Lake [Q3] oftmals nicht ausreichend ist, gibt es auch im HDFS das Konzept der ACLs. Die ACLs enthalten standardmäßig immer auch die Berechtigungen, die über die POSIX-Berechtigungen im HDFS für den Besitzer der Datei/des Ordners, einer User-Gruppe und den restlichen Usern vergeben wurden. Zusätzlich bieten die ACLs aber auch noch die Möglichkeit, Rechte für weitere User/User-Gruppen zu vergeben. Damit die ACLs überhaupt genutzt werden können, muss in der HDFS-Konfiguration der Wert dfs.namenode.acls.enabled auf true gesetzt werden [Q4]. Ohne diese Änderung werden alle Befehle zum Setzen von ACLs ignoriert (siehe nächstes Listing).
hdfs dfs -setfacl -m user:patrick:rw- /user/ ordix/testdatei.txt
setfacl: The ACL operation has been rejected. Support for ACLs has been disabled by setting dfs. namenode.acls.enabled to false.
Anschließend kann der HDFS-Superuser mittels der ACLs verschiedenste Zugriffsrechte setzen. Dazu muss der Befehl hdfs dfs -setfacl genutzt werden.
hdfs dfs -setfacl -m user:patrick:rw- /user/ ordix/testdatei.txt
Mittels hdfs dfs -getfacl können die aktuell für diese Datei bzw. Ordner gesetzten ACLs angezeigt werden.
hdfs dfs -getfacl /user/ordix/testdatei.txt
# file: /user/ordix/testdatei.txt
# owner: ordix
# group: hdfs
user::r--
user:patrick:rw-
group:: r--
mask::rw-
other:: r--
Zudem wird über ein + in der Ausgabe des ls-Kommandos symbolisiert, dass eine ACL für diese Datei bzw. diesen Ordner gesetzt wurde.
hdfs dfs -ls /user/ordix/testdatei.txt
-r--rw-r--+ 1 ordix hdfs 34 2018-01-29 14:16 / user/ordix/testdatei.txt
Da pro Datei eine eigene ACL erstellt werden kann und pro ACL 32 Einträge [Q5] erlaubt sind, ist durch die Nutzung der ACLs eine deutlich feingranularere Rechtevergabe möglich. Aber auch 32 Einträge können sehr schnell nicht mehr ausreichen, wenn das Hadoop-Cluster beispielweise als Data Lake genutzt wird. Falls der Data Lake in einem großen Unternehmen aufgebaut wird, kann es sehr schnell dazu kommen, dass mehr als 32 Abteilungen bzw. Personengruppen auf die gleichen Daten zugreifen sollen/wollen. In diesem Fall reicht dann die Möglichkeit zur Rechtevergabe mittels ACLs nicht mehr aus, um solche feingranulare Rechtevergabe zu ermöglichen. An dieser Stelle würde dann eine Komponente wie z. B. Apache Ranger ansetzen.
Kerberos
Kerberos wurde ursprünglich am Massachusetts Institute of Technology (MIT) entwickelt und stellt einen Mechanismus zur eindeutigen Identifizierung des Users bereit (weitere Information zu Kerberos sind in [4] zu finden). Die eindeutige Identifizierung eines Users/Systems wird auch als Authentifizierung bezeichnet [Q6]. Neben dem Authentifizierungsmodus simple, bei dem der User- Name im Betriebssystem zur Authentifizierung genutzt wird, bietet Hadoop auch die Möglichkeit zur Nutzung von Kerberos. In diesem Modus ist ein Zugriff auf die, im HDFS gespeicherten, Daten nur noch über ein gültiges Kerberos- Ticket (Kerberos-TGT) möglich. Dieses kann im Linux- Betriebssystem über den Befehl kinit erzeugt werden.
hdfs dfs -cat /user/ordix/testdatei.txt
18/01/30 10:00:21 WARN ipc.Client: Exception encountered while connecting to the server : javax. security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
[Fehlermeldung ist gekürzt]
kinit ordix@INTERNAL.ORDIX.DE
<Eingabe des Passworts>
hdfs dfs -cat /user/ordix/testdatei.txt
Hallo liebe ORDIX® news-Leser. :-)
Die Aktivierung von Kerberos in einem Hadoop-Cluster ist jedoch nicht trivial. So müssen beispielsweise für jeden Server die passenden Kerberos Principals und die dazugehörigen Keytabs angelegt werden. Falls eine Distribution wie z. B. die Hortonworks Data Platform (HDP) oder Cloudera's Distribution Including Apache Hadoop (CDH) genutzt werden, dann kann die Kerberisierung des Clusters auch automatisiert über den Cluster Manager (Apache Ambari/Cloudera Manager) vorgenommen werden (siehe Abbildung 1).
Dabei werden durch den Cluster Manager die benötigten Kerberos Principals und die dazugehörigen Keytabs erstellt. Damit dies automatisiert ablaufen kann, muss als Vorbedingung ein Kerberos/AD-Admin-User vorhanden sein. Zudem werden bei der Kerberisierung des Hadoop- Clusters durch den Cluster Manager auch noch die benötigten Einstellungsänderungen bei den einzelnen Hadoop-Komponenten durchgeführt.
Delegation Tokens
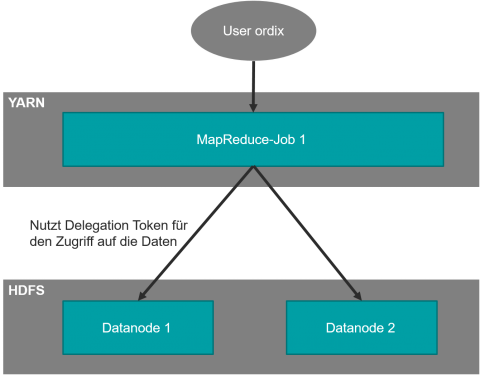
Nach der Aktivierung von Kerberos in einem Hadoop- Cluster kommt ein weiterer Sicherheitsmechanismus von Hadoop zum Tragen. Dies ist die Verwendung von Delegation Tokens. Diese Tokens werden verwendet, um den Zugriff von verteilt ausgeführten Processing-Jobs (wie z. B. MapReduce-Jobs) auf das HDFS abzusichern (siehe Abbildung 2). Um ein Delegation Token nutzen zu können, muss die folgende Abfolge von Operationen ausgeführt werden:
• Der Benutzer authentifiziert sich gegenüber MapReduce/YARN mithilfe von Kerberos.
• Der Benutzer authentifiziert sich gegenüber dem HDFS Namenode und bekommt als Antwort ein Delegation Token.
• Dieses Delegation Token wird anschließend innerhalb des MapReduce-Jobs zum Zugriff auf die HDFS-Daten genutzt.
Delegation Tokens werden eingesetzt, um eine zu hohe Last auf dem Key-Distribution-Center-(KDC)-Server zu verhindern. Die geringere Belastung des KDCs beruht darauf, dass es sich bei den Delegation Tokens nicht um eine Drei-Wege-Authentifizierung (Client, Server, unabhängige Stelle), sondern nur um eine Zwei-Wege- Authentifizierung zwischen dem Client und dem Server handelt. Dadurch wird sichergestellt, dass die Autorisierung des Users/Services immer nur beim Start des MapReduce- Jobs durchgeführt werden muss und nicht bei jedem Zugriff auf die HDFS-Daten bzw. bei der Kommunikation zwischen den beteiligten Komponenten. Gerade bei sehr großen Clustern (> 500 Knoten) würde eine Drei-Wege-Authentifizierung mittels Kerberos zu einer sehr hohen Last auf dem KDC führen. Da das KDC oftmals Bestandteil des unternehmensweiten Active Directorys ist, könnte dies zu einem Ausfall des Active Directorys führen und somit zu einer erheblichen Beeinträchtigung der Unternehmensabläufe.
Des Weiteren ist bei der Nutzung von Delegation Tokens zu beachten, dass diese standardmäßig alle 24 Stunden erneuert werden müssen und nach 7 Tagen auslaufen. Der Ablauf des Delegation Tokens kann gerade bei sehr langlaufenden Jobs zu Problemen führen. Dies muss bei der Entwicklung der Processing-Jobs beachtet werden. Sobald der Processing-Job abgeschlossen ist, wird das Delegation Token automatisch gelöscht und kann dadurch nicht durch einen Angreifer missbraucht werden. Dies ist sowohl nach einem erfolgreichen Abschluss des Jobs der Fall, als auch im Fehlerfall [Q7].
Das Prinzip der Delegation Tokens wird jedoch in einem kerberisierten Hadoop-Cluster nicht nur beim Zusammenspiel von Processing-Jobs mit dem HDFS eingesetzt. Ein weiteres Einsatzgebiet ist beispielsweise der Zugriff von Processing-Jobs auf verschlüsselte HDFSOrdner. Hierbei kommt das Hadoop KMS Delegation Token ins Spiel. Sobald ein HDFS-Ordner mithilfe des Hadoop KMS verschlüsselt wurde, braucht ein Processing-Job sowohl ein HDFS-Delegation Token als auch ein KMS Delegation Token. Erst dann können die Daten innerhalb des Jobs verarbeitet werden. Weitere Informationen zu den Delegation Tokens sind unter [5] zu finden.
Hive
Apache Hive ist eine oft genutzte Komponente, die sehr eng mit den Hadoop-Kernkomponenten (HDFS, YARN, MapReduce) zusammenarbeitet. Dabei stellt Hive die Möglichkeiten eines Data Warehouse (z. B. die Abfrage von Tabellen mittels SQL-Statements) zur Verfügung. Hive kann zur Speicherung der Daten das HDFS oder andere Technologien wie z. B. HBase nutzen. Oftmals wird jedoch das HDFS genutzt. Durch diese enge Verbindung zwischen Hive und dem HDFS ist eine Rechtevergabe nicht trivial.
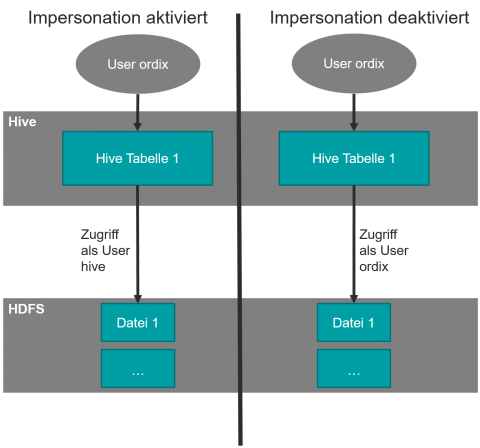
So muss bedacht werden, ob Impersonation über die Variable hive.server2.enable.doAs aktiviert wurde oder nicht. Falls Impersonation aktiviert ist, müssen für den zugreifenden User (in Abbildung 3 ist dies der User ordix) nur die entsprechenden Rechte in Hive gegeben werden. Dies passiert über den GRANT-Befehl. Im Folgenden ist ein Beispiel abgedruckt, das einem User die Möglichkeit gibt, Daten aus einer Tabelle mittels des SELECT-Befehls auszulesen.
USE ordixdb;
GRANT select ON TABLE mitarbeiter TO USER ordix;
SHOW GRANT ON TABLE mitarbeiter;
OK
ordixdb mitarbeiter ordix USER SELECT false 1517327304000 hive
Time taken: 0.089 seconds, Fetched: 1 row(s)
Zusätzlich muss in diesem Modus (Impersonation aktiviert) darauf geachtet werden, dass der User, unter dem der Hive-Prozess läuft (standardmäßig ist dies hive) im HDFS über die Dateisystemberechtigungen oder ACLs so berechtigt wird, dass er die gespeicherten Daten lesen und bearbeiten darf. Dies muss auch dann beachtet werden, wenn die Daten nicht im per hive.metastore.warehouse.dir festgelegten Pfad gespeichert werden. So ist es beispielsweise möglich, beim Anlegen von Schemas individuelle HDFS-Ordner anzugeben (siehe nächstes Listing).
CREATE SCHEMA ordixdb LOCATION '/hivedatenbanken/';
Falls Impersonation deaktiviert wird, wird auch die Rechtevergabe noch einmal etwas komplexer. Ein User, der Daten aus einer Hive-Tabelle lesen möchte, braucht jetzt nicht nur die entsprechende Berechtigung in Hive, sondern auch noch zumindest die Read-Berechtigung im HDFS (siehe Abbildung 3). Falls mehrere User auf eine Tabelle zugreifen möchten, kann dies im HDFS nur noch über ACLs oder über User-Gruppen, die für jede Tabelle einzeln angelegt werden, gelöst werden. Als weitere Komplexität kommt dann auch noch die Möglichkeit zur Nutzung individueller Speicherorte für einzelne Schemas/Tabellen ins Spiel. Auch bei diesen Ordnern müssen dann immer die entsprechenden Berechtigungen gesetzt werden.
Eine weitere Möglichkeit, auf die mittels Hive im HDFS gespeicherten Daten zuzugreifen, besteht über das Auslesen der im Hive Metastore gespeicherten Metadaten. Weitere Information zu dem Hive Metastore sind unter [6] zu finden.
Ausblick
Wie das Beispiel Apache Hive schon gezeigt hat, macht die Nutzung von weiteren Komponenten aus dem Hadoop Ökosystem und vielen verschiedenen Usern (technische und persönliche) die Rechtevergabe noch komplexer. Dies ist ab einer bestimmten Anzahl an Benutzern irgendwann nicht mehr über die standardmäßigen Mechanismen (z. B. Dateisystemberechtigungen im HDFS) verwaltbar. Aus dieser Problematik haben sich zwei verschiedene Apache- Projekte entwickelt, die den Hadoop-Administrator bei der Rechtevergabe unterstützen. Dies sind Apache Sentry und Apache Ranger.
Ein weiterer Punkt, der nicht durch die Vergabe von Rechten mittels ACLs und der Aktivierung von Kerberos gelöst werden kann, ist der Zugriff des HDFS-Superusers auf alle im HDFS gespeicherten Daten [Q4]. Dies kann erst durch den zusätzlichen Einsatz des Hadoop KMS/Ranger KMS, zur Verschlüsselung des HDFS, verhindert werden.
Links/Quellen
[1] ORDIX Seminar-Empfehlung: Big Data Seminare https://seminare.ordix.de/seminare/big-data-und-data-warehouse.html
[2] ORDIX® news 3/2015 - „Big Data: Informationen neu gelebt (Teil III): Apache Hadoop" https://www.ordix.de/ordix-news-archiv/3-2015.html
[3] Enabling Kerberos Authentication for Hadoop Using the Command Line https://www.cloudera.com/documentation/enterprise/5-6-x/topics/cdh_sg_ cdh5_hadoop_security.html
[4] ORDIX® news 4/2012 - Kerberos (Teil I): Mit dem Höllenhund im Urlaub https://www.ordix.de/ordix-news-archiv/4-2012.html
[5] Hadoop Delegation Tokens Explained http://blog.cloudera.com/blog/2017/12/hadoop-delegation-tokens-explained/
[6] Apache Hive Homepage https://hive.apache.org/
[7] Spark SQL, DataFrames and Datasets Guide - Hive Tables https://spark.apache.org/docs/latest/sql-programming-guide.html#hivetables
[8] ORDIX® news 4/2012 - NoSQL vs. SQL - Hype oder echte Alternative? (Teil IV): HBase - Spaltenorientiert https://www.ordix.de/ordix-news-archiv/2-2013.html
[Q1] White, Tom: „Hadoop: The Definitive Guide"; 2nd Edition; Sebastopol: O'Reilly Media, 2010
[Q2] FileSystem Shell http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/FileSystemShell.html
[Q3] Enterprise Hadoop and the Journey to a Data Lake https://de.hortonworks.com/blog/enterprise-hadoop-journey-data-lake/
[Q4] HDFS Permissions Guide http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
[Q5] Offizielles HDFS-JIRA-Ticket https://issues.apache.org/jira/browse/HDFS-7447
[Q6] Authorization and Authentication In Hadoop http://blog.cloudera.com/blog/2012/03/authorization-and-authentication-in-hadoop/
[Q7] The Role of Delegation Tokens in Apache Hadoop Security https://de.hortonworks.com/blog/the-role-of-delegation-tokens-in-apache-hadoop-security/
Bereichsleiter & Senior Chief Consultant bei ORDIX