
Cloud-Kosten im Blick behalten: Kostencontrolling-Tool für die Open Telekom Cloud
Die nutzungsbasierte Abrechnung von IT-Ressourcen in Public-Cloud-Umgebungen hat für Unternehmen veränderte Kostenstrukturen zur Folge. Statt einmaliger Investitionsausgaben, wie sie im traditionellen IT-Betrieb hauptsächlich entstehen, ergeben sich für die Unternehmen nun laufende, flexible IT-Betriebskosten. Bei einer Vielzahl an Ressourcen kann schnell undurchsichtig werden, wodurch die Kosten verursacht wurden. Dies ist aber wichtig zu wissen, um die Wirtschaftlichkeit einzelner Kostenstellen oder Projekte beurteilen zu können. Die hohe Flexibilität, mit der Ressourcen erweitert und reduziert werden können, birgt auch das Risiko, dass Kosten unerwartet hoch ausfallen. Daher ist es wichtig, laufend zu überprüfen, ob die Kosten im Rahmen vorher definierter Budgets liegen und keine plötzlichen und unerwarteten Anstiege aufweisen. Nicht alle Cloud-Anbieter stellen jedoch entsprechende Funktionen für das Kostencontrolling in ausreichendem Umfang zur Verfügung. Daher war es meine Aufgabe, ein Tool für die Open Telekom Cloud zu entwickeln, welches zwei zentrale Funktionalitäten aufweist:
1. Erstellung monatlicher Reports, in denen die entstandenen Kosten ihren Verursachern zugeordnet werden (Kostenstellen und Projektnummern)
2. Tägliche Überprüfung, ob die Kosten ein dynamisch festgelegtes Limit überschreiten
Im Folgenden wird exemplarisch gezeigt, wie das Python-Tool für die Open Telekom Cloud funktioniert. Für andere Cloud-Umgebungen wäre dies in ähnlicher Weise umsetzbar.
Kostendaten-API aufrufen
Bei der Open Telekom Cloud sind detaillierte Nutzungs- und Kostendaten nur über das kostenpflichtige Enterprise-Dashboard automatisiert abrufbar. Über den Aufruf von REST-Schnittstellen werden diese Daten in die Python-Anwendung integriert. Grundlage für die spätere Auswertung ist die Nutzung des Tag-Management-Services, der es ermöglicht, Ressourcen z. B. mit einer Projektnummer zu markieren.
Um die API mit Python aufzurufen, kann die Requests-Bibliothek verwendet werden. Mit der get-Methode wird die angegebene URL angesprochen. Die Parameter legen den Monat fest und dass die Tags berücksichtigt werden sollen. Als Header wird ein Autorisierungstoken benötigt:
response = requests.get(
"https://api-enterprise-dashboard.otc-service.com/v1/consumption/month",
headers={"Authorization": f"Bearer {authorizationtoken}"},
params={"tagged": True, "month": "2021-10" }
)
Die Antwort enthält JSON-formatierte Nutzungs- und Kostendaten mit der folgenden Struktur:
{
"kind": "Collection",
"total": 261,
"contents":[
{
"amount": 42.048,
"billing_quantity": 24.0,
"business_partner_id": 12345,
"consumption_date": "2021-10-01 00:00:00",
"consumption_type_description": "Usage for PLM Cloud with price",
"contract": 1000021234,
"kind": "Consumption",
"listprice_amount": 52.56,
"product": "OTC_D24XL8_LI",
"product_description": "Disk Intensive d2.4xl.8 Linux",
"project_id": "499378d37f2b4b93a85d81df93fe2d2f",
"project_name": "eu-de",
"quantity_unit": "H",
"region": "EU-DE",
"reseller_id": 12345,
"resource_id": "129dea56-f552-4db9-8caf-13fea3d78cb",
"tags": {
"Projektnummer": "987654321"
},
"unit_price": 2.19
}
]
}
Daten umformen
Der Datentyp der Variable response ist ein requests.models.Response-Objekt. Um dieses weiterzuverarbeiten, wird es zunächst in ein Python-Dictionary umgewandelt:
data = response.json()
Python-Dictionaries eignen sich jedoch nicht, um große Datenmengen auszuwerten, daher soll die pandas-Bibliothek zum Einsatz kommen. Sie bietet einen großen Funktionsumfang zur Verarbeitung tabellarischer Daten. Grundlegende Datenstruktur ist dafür der DataFrame, bestehend aus Reihen, Spalten und Daten. Erzeugen lässt er sich unter anderem mit der Funktion json_normalize(), die ein verschachteltes Dictionary auf eine Ebene reduziert:
df = pd.json_normalize(data, record_path = ['contents'])
Am DataFrame selbst können dann weitere Anpassungen vorgenommen werden. Beispielsweise kann zur zeitbasierten Auswertung der Datentyp der Spalte "consumption_data" in ein Datumsobjekt umgewandelt werden:
df['consumption_date'] = pd.to_datetime(consumption_data['consumption_date'], format="%Y-%m-%d %H:%M:%S")
Daten auswerten
Aus dem DataFrame können nun die gewünschten Informationen gewonnen werden. Dazu wird im Beispiel der DataFrame nach den Projektnummer-Tags gruppiert und die Spalte "amount", welche die Kosten enthält, aufsummiert. Zusätzlich wird das Ergebnis gerundet, absteigend sortiert und wieder in einen DataFrame umgeformt:
project_costs = (
df.groupby("tags.Projektnummer", dropna=False)["amount"]
.sum()
.round(decimals=2)
.sort_values(ascending=False)
.to_frame()
)
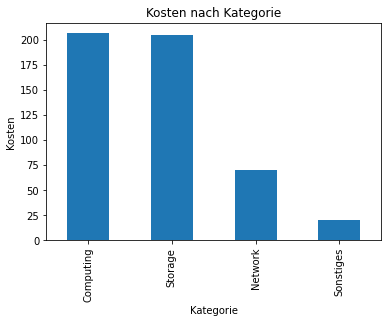
Auch eine schnelle Visualisierung der Ergebnisse ist mit pandas möglich. Hier angewandt auf einen DataFrame, der Kosten nach Produktkategorien enthält:
category_costs.plot(kind="bar", title="Kosten nach Kategorie", xlabel='Kategorie', ylabel='Kosten', legend=False)
Report erstellen
Nachdem die Informationen aus den Daten gewonnen wurden, sollen diese nun in einem HTML-Report dargestellt werden. Dazu wird die Jinja2-Bibliothek verwendet. Sie ermöglicht es, Variablen in Vorlagen einzubinden und anschließend zu rendern. Im Beispiel soll der Report die Kosten nach Projektnummer als Tabelle darstellen. Die Variable project_costs muss in geschweifte Klammern geschrieben werden:
<body>
<h1>Open Telekom Cloud Report</h1>
<p>Kosten nach Projektnummer</p>
{{project_costs}}
</body>
Um die Variable in die Vorlage einzubinden, muss zunächst ein Environment-Objekt erstellt werden. Der Loader legt fest, wie die Vorlage geladen werden soll – in diesem Fall als Datei aus dem aktuellen Arbeitsverzeichnis. Danach wird ein Dictionary für die Variable angelegt. Der Key muss den gleichen Namen haben wie in der Vorlage. Der Value ist im Beispiel ein DataFrame, der mit der pandas-Funktion to_html() in HTML-Elemente umgewandelt wird. Zuletzt wird die Vorlage mit dem übergebenen Dictionary gerendert und in eine neue Datei geschrieben:
# Umgebung einrichten
env = jinja2.Environment(loader=jinja2.FileSystemLoader(searchpath="./"))
template = env.get_template("report_template.html")
#Variable für Vorlage
template_var = {"project_costs": project_costs.to_html()}
# Report rendern und als HTML-Datei speichern
with open ('report.html', 'w') as report:
report.write(template.render(template_var))
Der erstellte Report kann nun beispielsweise jeden Monat automatisch per E-Mail an die Verantwortlichen versendet werden.
Warnfunktion
Zusätzlich zu einer nachträglichen Betrachtung der monatlichen Kosten ist es empfehlenswert, die Kosten in kürzeren Abständen zu überprüfen. So können bei außerplanmäßigen Kostensteigerungen rechtzeitig die Ursachen gefunden und Gegenmaßnahmen ergriffen werden.
Im Beispiel wird auf Basis der Kosten des Vormonats und einem selbstdefinierten Limitfaktor (z. B. 110 %) eine Obergrenze festgelegt, die eingehalten werden soll. Dann werden die täglichen Kosten des aktuellen Monats aus den flexiblen und festen Kosten berechnet. Diese beiden Werte müssen zuvor mithilfe von pandas ausgewertet werden. Daraus kann hochgerechnet werden, wie hoch die Kosten am Ende des Monats bei gleichbleibender Nutzung wären und der Wert mit der Obergrenze verglichen werden:
# aus Kosten für letzten Monat Limit für aktuellen Monat berechnen
dynamic_limit = limit_factor * total_costs_last_month
# für aktuellen Monat Durchschnittskosten pro Tag berechnen
daily_costs_cur_month = (
flexible_costs_cur_month / days_cur_month + fixed_costs_cur_month / 30
)
# hochrechnen, ob Durchschnittskosten pro Tag das monatliche Limit übersteigen würden und ggf. Warnung auslösen
if (daily_costs_cur_month * 30) > dynamic_limit:
pass
Liegen die Kosten über der Obergrenze, können zum Beispiel die Verantwortlichen per E-Mail informiert werden.
Fazit
Den Überblick über Cloud-Kosten zu behalten, ist eine wichtige Aufgabe. Werden Kosten transparenter aufgeschlüsselt, ergeben sich auch Potenziale, um die Kosten zu optimieren. Es kann sich daher lohnen, für diesen Zweck auch eigene Tools zu entwickeln, falls der Cloud Provider keine passenden Funktionen selbst bereitstellt. Anhand der Beispiele konnte gezeigt werden, wie mit wenigen Schritten bereits erste Ergebnisse gewonnen werden können. Darauf aufbauend sind umfangreichere Auswertungen oder weitere Funktionen wie Benachrichtigungen möglich. Python ist mit seinen umfangreichen Bibliotheken hierfür eine sehr geeignete Programmiersprache.
Seminarempfehlungen
CLOUD COMPUTING ESSENTIALS CLOUD-COMP
Zum SeminarPYTHON PROGRAMMIERUNG GRUNDLAGEN P-PYTH-01
Zum SeminarPYTHON PROGRAMMIERUNG FÜR FORTGESCHRITTENE P-PYTH-02
Zum SeminarJunior Consultant bei ORDIX
Kommentare