
GraphQL API zur kontinuierlichen Qualitätsanalyse von Datenverarbeitungsprozessen
WAS IST GRAPHQL?
GraphQL ist eine Abfragesprache für eine API mit einer serverseitigen Laufzeitumgebung zur Ausführung von Abfragen. Es wird das Prinzip verfolgt, dass der Client das Format der Daten und damit den Umfang dynamisch zur Laufzeit bestimmt, und nicht jeweils spezifische Endpunkte entwickelt werden müssen.[1]
In diesem Anwendungsfall kann der Client zum Beispiel entscheiden, welche Infos er zu einem ETL-Job benötigt. Reicht der Name der Verarbeitung, oder ist relevant, wann die letzte Änderung gemacht wurde und vom wem? Mit GraphQL kann derselbe Endpunkt für beide Anwendungsfälle maßgeschneiderte Antworten liefern, ohne Over- oder Underfetching.
VORGEHEN ZUR JOB VALIDIERUNG
Für die Validierung muss zunächst ein Export zur Verfügung stehen, also ein konstantes Abbild der Datenverarbeitungsprozesse, die validiert werden sollen. Dieses wird im ersten Schritt an die API gesendet. Als Response erhält der Client eine UUID zur Identifikation des Validierungsauftrags. Der Server beginnt nun, den ETL-Prozess zu valideren.
Im zweiten Schritt kann der Client den Status bzw. das Ergebnis der Qualitätsanalyse abfragen. Er erhält in jedem Fall die Information, wie viele Jobs im Export enthalten waren, und wie viele von diesen bereits annalysiert sind. Falls die Validierung noch nicht abgeschlossen ist, kann der Client bereits die Ergebnisse von bereits validierten Jobs abrufen. Andernfalls stehen ihm bereits alle Resultate zur Verfügung.
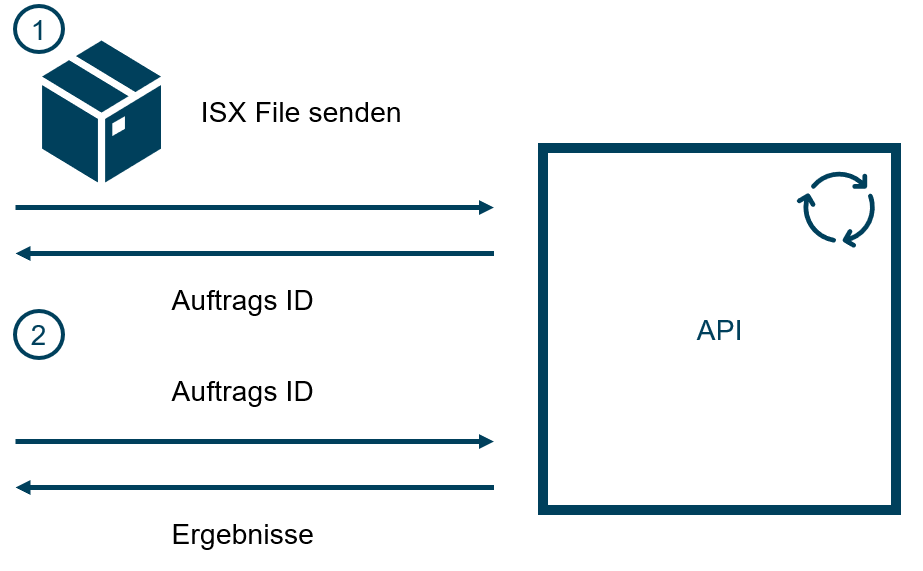
DAS VALIDEREN EINES DATASTAGE EXPORTS

Im Folgenden wird dargestellt, wie die eigentliche Verarbeitung innerhalb des Servers aufgebaut ist.
Hierbei werden folgende Schritte durchlaufen:
- ZIP File entpacken
Bei dem ISX File handelt es sich um ein ZIP Archive, welches die eigentlichen Daten beinhaltet. Diese werden im ersten Schritt extrahiert. -
Enthaltene Objekte lesen
und analysieren
Um die Prüfungen auf die Struktur anwenden zu können, werden zunächst die Daten aufbereitet, sodass die Prüfungen nacheinander auf diese angewendet werden können. Das ermöglicht die Durchführung der Analyse auf einer Abstraktionsebene.- XML-Datei einlesen
- XML-Elemente auf Java Datentransferobjekt (DTO) übertragen
- Alle Prüfungen auf Datentransferobjekt durchführen
Die Konvertierung von XML-Elementen in die korrespondierenden DTOs in Java werden durch ein Mapping von JPA zu XML durchgeführt. Die eigentlichen Prüfungen müssen in einer dafür vorgesehenen Datenstruktur definiert werden. Diese werden in eine Datenbank gemappt, damit die Prüfungen dynamisch spezifiziert und hinzugefügt werden können. Beim Validieren werden hierarchisch die zu validierenden Objekte durchgegangen. Entsprechend werden existierende Prüfungen abhängig von der Objektart und Objekttiefe angewendet.[2]
Es gibt mehrere Arten von Prüfungen, wobei verschiedene Fehlerlevel zurückgegeben werden können. Diese können über die API nach Bedarf hinzugefügt werden.
DIE ERGEBNISSE DER POLICE-ÜBERPRÜFUNG

HINZUFÜGEN VON POLICES
Die Validierungsprüfungen und Policies sind abhängig von Vorgaben des jeweiligen Projektes und internen Guidelines. Daher können Policies zur Laufzeit über die API hinzugefügt werden. Diese werden in einer Datenbank hinterlegt und auf die ETL-Prozesse angewendet
In der folgenden Abbildung wird gezeigt, wie die oben dargestellte Police-Überprüfung hinzugefügt werden kann. In diesem Beispiel handelt es sich um einen Parameter, der überprüft werden soll.

Quellen
[1] The GraphQL Foundation (2020): https://graphql.org/; besucht am 05.08.2020
[2] Cossijns M. (2020): Konzeption und Implementierung einer API zur Qualitätsanalyse und Überprüfung von unternehmensinternen Policies von ETL-Jobs; S. 56
Kommentare