
Log-Management mit Splunk
IT-Betreiber sind mit einer immer größeren Anzahl von IT-Systemen konfrontiert, die Unmengen von Log-Daten produzieren. Leider ist es nicht damit getan, Log-Daten zu erzeugen. Für Fehleranalyse, Überwachung und Performance-Analyse sind die Log-Daten DIE zentrale Informationsquelle.
Eine direkte Analyse der Logs auf den Systemen ist jedoch nicht praktikabel. Hier kommen heute Log-Management-Systeme zum Einsatz, welche die einfache Nutzung der anfallenden Daten ermöglichen. Durch ein Log-Management-System werden protokollierte Daten an einem zentralen Ort gesammelt, gespeichert, normalisiert und analysiert.
Die Vorteile mit dem Einsatz eines Log-Management-Systems sind vielfältig:
- Einfache und schnelle Analyse zur Fehlersuche
- Perfomance-Auswertungen
- Prozessüberwachung
- Erkennen von Anomalien
- der Bereich des SIEM (Security Information and Event Management) in welchem die Beobachtung, Erkennung und Alarmierung von Sicherheitsereignissen betrachtet werden
- revisionssichere Archivierung
- Erfüllung von Compliance-Vorgaben
Splunk Komponenten: Forwarder, Indexer, Search Head
Splunk ist eine der großen kommerziellen Lösungen der Firma „Splunk Inc", welche seit ca. 2007 ein umfangreiches Log-Management und Analyse bietet.
Die grundlegenden Komponenten der Splunk-Architektur sind:
- Forwarder: sammelt die Logs und leitet Sie an den Indexer weiter
- Indexer: analysiert und indiziert die Daten
- Search Head: bietet das Frontend zur Suche, Analyse und Reporting der Daten
Der "Forwarder" ist das Programm, welches auf dem System läuft, auf welchem die Logdaten erzeugt werden. Es werden die zu überwachenden Verzeichnisse und Dateinamensmuster konfiguriert, sodass Änderungen in diesen Dateien ausgelesen und an den Indexer übertragen werden können.
Dabei gibt es den Forwarder in einer "leichten" und einer "schweren" Variante. Die "leichte" Variante benötigt wenig Ressourcen und übermittelt die Daten unverändert, während die "schwere" Variante in der Lage ist, die Daten vor der Übermittlung bereits zu bearbeiten (z. B. filtern).
Search Head – Das Frontend von Splunk
Der "Search Head" ist das Frontend der Anwendung und ermöglicht den Benutzern die Abfrage, Anzeige und Nutzung der Ereignisdaten. Zusätzlich können Berichte, Dashboards und Alarme erstellt werden. Mittels der Splunk eigenen Script-Sprache "SPL" (Search Processing Language) können die Daten gefiltert, berechnet und extrahiert werden. Das Grundkonzept für eine Suche in den Daten ist dabei relativ einfach.
Ungefiltert liefert das System eine nach Zeit sortierte Liste aller Logeinträge, unabhängig davon, von welchem System und aus welchem Logfile diese Einträge stammen.
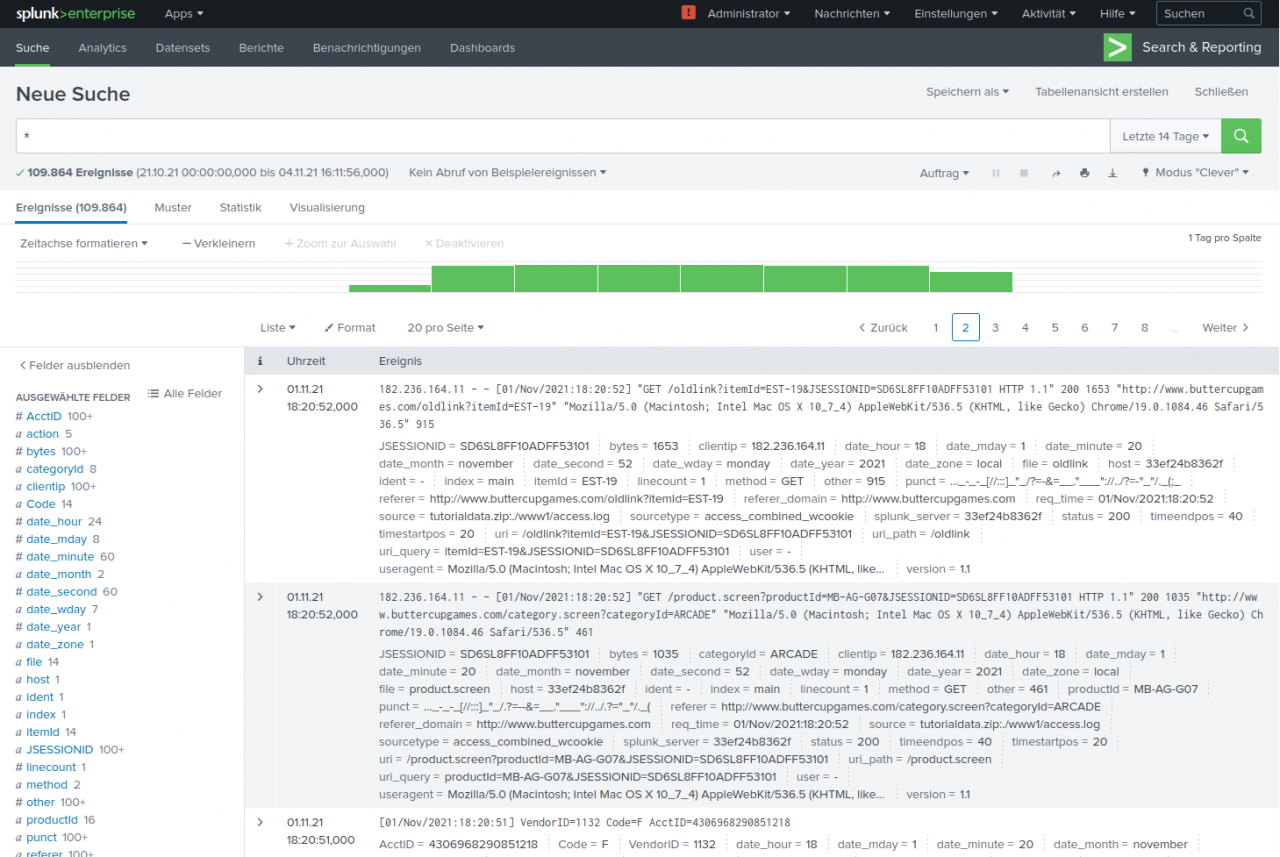
Damit wird eine Suche, welche z. B. nach ein oder mehreren Wörtern filtert, automatisch über alle Logfiles durchgeführt. Wird z. B. eine Session-ID bei einer Anfrage über das Frontend einer Anwendung konsequent an die dahinter liegenden Backend-Systeme durchgereicht, dann werden bei einer Suche nach dieser ID automatisch die Logeinträge aus allen Systemen in ihrer zeitlichen Abfolge ausgegeben.
Allerdings sind nicht für jeden Nutzer automatisch alle Logeinträge sichtbar. Die verschiedenen Typen von Logs werden in unterschiedliche Indizes importiert.
Basierend auf den Indizes können dann den Nutzern Leserechte zugeordnet werden.
Bei der Indizierung der Logeinträge werden diese um zusätzliche Metadaten in Form von Feldern angereichert. Einige grundlegende Felder sind z. B.:
- time: Zeitpunkt des Logeintrags
- host: Hostname von dem das Logfile stammt
- sourceder: Dateiname des Logfiles
- sourcetype: der Typ des Logfiles
- index: der Name des verwendeten Index
Hat das Logfile ein bekanntes Format, werden weitere spezifische Abschnitte aus dem Eintrag extrahiert und als Felder zur Verfügung gestellt.
Diese Felder können dann direkt in einem Filterausdruck verwendet werden.
JSESSIONID=SD6SL4FF2 productId="MB-AG-T01" OR productId="FS-SG-G03"
Indizierung mit Splunk – anders als bei anderen Produkten
In einigen konkurrierenden Produkten zu Splunk gilt die Voraussetzung, dass alle Felder, so wie hier beschrieben, bereits zum Zeitpunkt der Indizierung definiert sein müssen, damit sie in einer Suche verwendet werden können.
Dies ist bei Splunk jedoch nicht der Fall. Hier wird die vollständige Definition vorab nicht vorausgesetzt, sondern es verwendet ein „Schema on the Fly". D.h. eine Suche kann zu Beginn ad hoc zusätzliche Felder aus den Logeinträgen extrahieren, um diese dann in der Abfrage zu verwenden. Die Muster, um die Felder zu identifizieren, werden mit regulären Ausdrücken definiert.
Dieses Vorgehen hat den Vorteil, dass auch auf bereits importierte Logfiles neue Inhalte ausgewertet werden können. Der Umfang der Abfragesprache ist ähnlich zu SQL und ermöglicht u.a. filtern, gruppieren und aggregieren.
Mit kurzen einfachen Statements lassen sich bereits informative Diagramme erstellen:
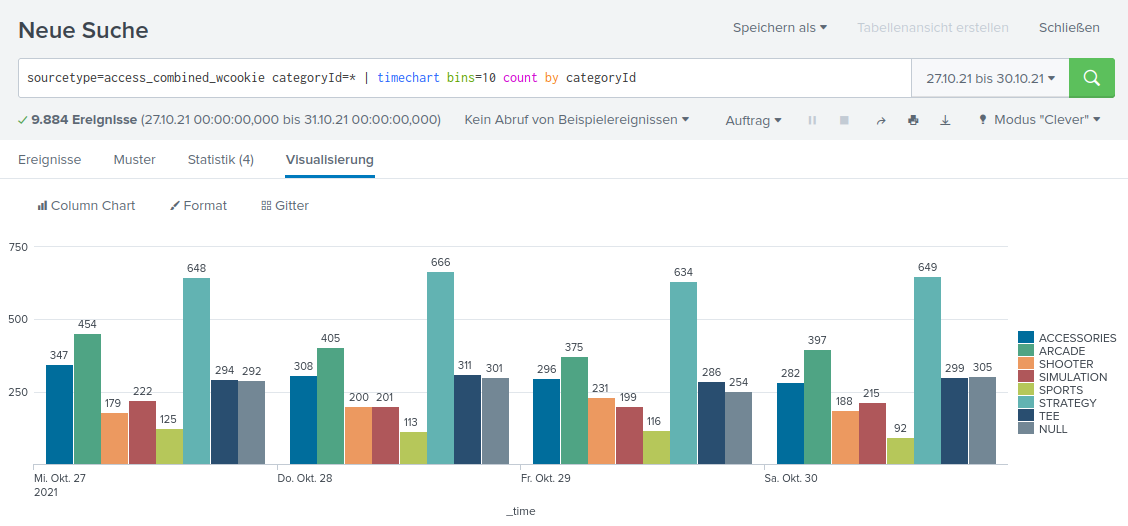
Basierend auf einzelnen Reports und Diagrammen lassen sich diese in interaktiven Dashboards zusammenfassen und bieten so ein mächtiges Mittel um komplexe Zusammenhänge übersichtlich darzustellen.
Splunk stellt alle Werkzeuge einer zentralisierten Logdatenverwaltung bereit, um die umfangreichen Informationen der verschiedenen Logdaten optimal zu nutzen.
Haben Sie weiteres Interesse oder Fragen zum Thema? Um Ihr IT-Projekt zum Erfolg zu führen, könnte unser mehrtätiges Seminar für Sie interessant sein.
IT-Management – Die IT nachhaltig zum Erfolg führen
Principal Consultant bei ORDIX
Kommentare