
PostgreSQL trifft Kubernetes – Der ultimative Operator-Vergleich für eure Datenbank-Revolution
Die zunehmende Verlagerung von Workloads in Kubernetes-Umgebungen hat auch bei Datenbanken zu einem Paradigmenwechsel geführt. Insbesondere PostgreSQL, als eine der sehr stark verbreiteten relationalen Datenbanken, wird zunehmend in containerisierten Umgebungen betrieben. Kubernetes-Operatoren spielen hierbei eine entscheidende Rolle, da sie Automatisierung, Verwaltung und Hochverfügbarkeit von PostgreSQL-Clustern erleichtern.
In diesem Artikel analysieren und vergleichen wir fünf Kubernetes-Operatoren für PostgreSQL:
- Crunchy Postgres for Kubernetes
- CloudNativePG
- Zalando Postgres Operator
- StackGres
- KubeDB by AppsCode
Oberflächlich betrachtet bieten alle fünf Operatoren vergleichbare Grundfunktionen, wie Deployment und Konfiguration von Postgres-Clustern, Exportieren von Monitoring-Metriken, automatisierte Failover- und Backup-Mechanismen. Unterschiede zeigen sich allerdings im Detail in der Performance, insbesondere bei Failover-Zeiten. Hier eine detaillierte Betrachtung:
Crunchy Postgres Operator
Der Operator von Crunchy Data ist eine etablierte Lösung, die sowohl für kleine Testumgebungen als auch für komplexe Produktionsumgebungen mit tausenden Pods geeignet ist.
Der Operator nutzt Patroni zum Verwalten der PostgreSQL-Instanzen und greift im Falle eines Ausfalls mit dem integrierten Failover-Mechanismus, der eine Replika-Instanz zu einer Primary befördert, um die Erreichbarkeit des Clusters sicherzustellen. Die Konfiguration einer Single-Instanz ist ebenso möglich. Sonstige Highlights umfassen:
- Ein Integriertes Backup-Management-Tool mit pgBackRest
- Out-of-the-box-Monitoring mit pgMonitor
- Connection Pooling mit PgBouncer
- Eine umfangreiche und detaillierte Dokumentation
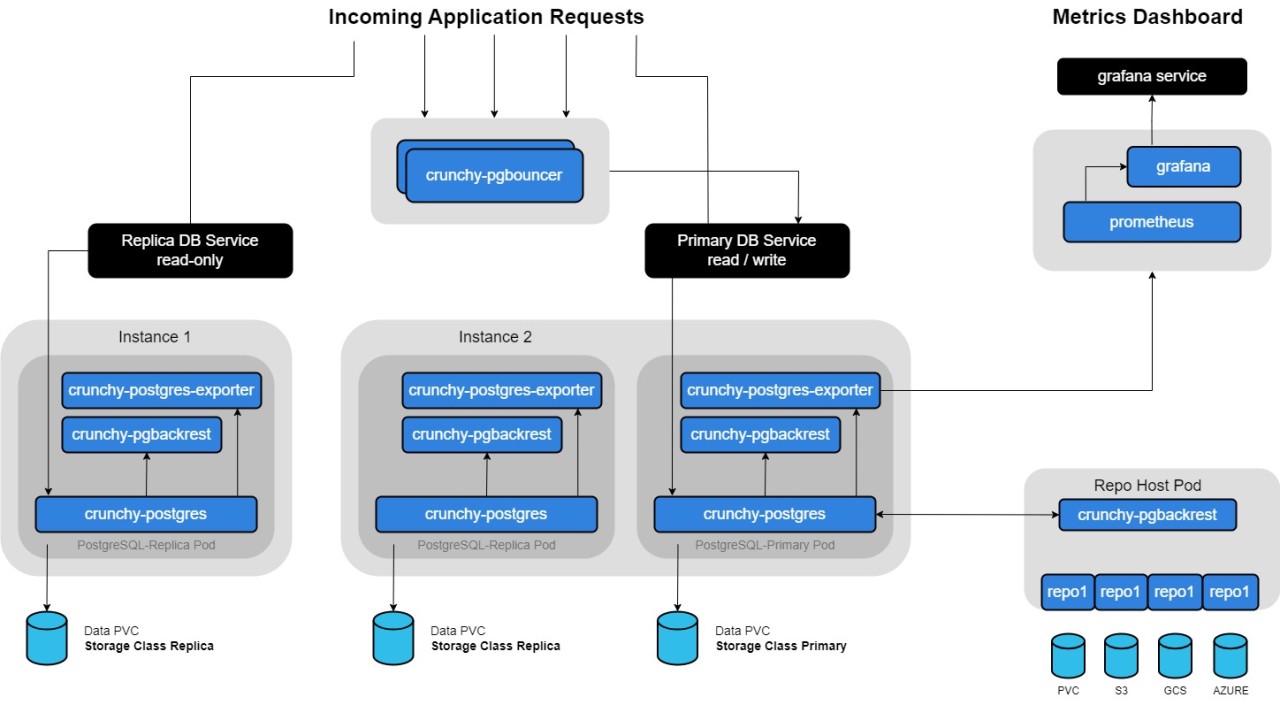
Hier ein Diagramm zum Überblick über die Funktionalitäten und Architektur des Crunchy Postgres Operators:
CloudNativePG
CloudNativePG ist der jüngste der hier betrachteten Kubernetes-Operatoren. Ursprünglich von EnterpriseDB entwickelt, wurde er 2022 als Open-Source-Projekt unter der Apache License 2.0 veröffentlicht und wird seither von der Cloud Native Computing Foundation (CNCF) aktiv unterstützt. Dank dieser breiten Community-Unterstützung hat sich CloudNativePG als der am weitesten verbreitete Operator unter den hier verglichenen etabliert.
Der Operator bietet eine Kubernetes-native Lösung für die Verwaltung und Konfiguration von Clustern und beinhaltet Funktionen für die Konfiguration eigener Services, die deklarative Verwaltung von Rollen, Benutzer:innen, Datenbanken und Tablespaces sowie PostgreSQL-Erweiterungen. Er unterstützt die Verwendung eigener PostgreSQL-Images, aber auch eine Reihe von vordefinierten.
Darüber hinaus bietet CNPG ein Kubernetes-Plugin, welches das Verwalten der PostgreSQL-Cluster vereinfacht. Die für uns interessantesten Features sind hier aufgelistet:
Cluster-Verwaltung
- Statusabfrage: Anzeigen von Details wie Cluster-Instanzen, WAL-Positionen, Replikationsstatus und Sicherungsdetails.
- Neustart: Rollout- oder Einzelinstanz-Neustarts.
- Hibernation: Cluster pausieren und später wiederherstellen, einschließlich PVC-Speicherung.
- Cluster-Logs: Einfache Sammlung und Anzeige von Logs aller Cluster-Pods.
Sicherungen und Wiederherstellung
- Backup: Erstellung von physischen Backups und Volume Snapshots.
- Wiederherstellung: Point-in-Time-Recovery über Backups.
Konfigurationsmanagement
- Deklarative Updates: Anwenden von Änderungen an ConfigMaps und Secrets.
- TLS-Zertifikate: Verwaltung von TLS-Zertifikaten für PostgreSQL.
Logische Replikation
- Publications: Erstellen und Verwalten logischer Replikationspublikationen.
- Subscriptions: Aufbau und Verwaltung logischer Replikationsabonnements.
- Synchronisation von Sequenzen: Unterstützung für fehlende Synchronisation in der logischen Replikation.
Monitoring und Reporting
- Reports: Sammlung von Cluster- und Operator-Informationen für Debugging-Zwecke.
- Integration: Unterstützung für Tools wie pgbench, fio, und pgAdmin.
Schnelle Integration
- PgAdmin4-Installation: Schnelles Deployment von pgAdmin4 für Demos (nicht für Produktion empfohlen).
- Befehlsalias: Unterstützung für kubectl cnpg als Wrapper für PostgreSQL-Befehle wie psql.
Zalando Postgres Operator
Der Zalando Operator wurde ursprünglich für den internen Gebrauch entwickelt und ist heute eine der beliebtesten Open-Source-Lösungen im PostgreSQL-Ökosystem.
Für Replikation und HA verwendet Zalando Spilo, ein von Zalando entwickeltes Docker-Image, das PostgreSQL und Patroni bündelt. Für Backup und Restore verwendet der Operator pg_base_backup und WAL-E. Zusätzlich bietet der Operator ein Web-Interface zum Erstellen und Bearbeiten von Clustern.
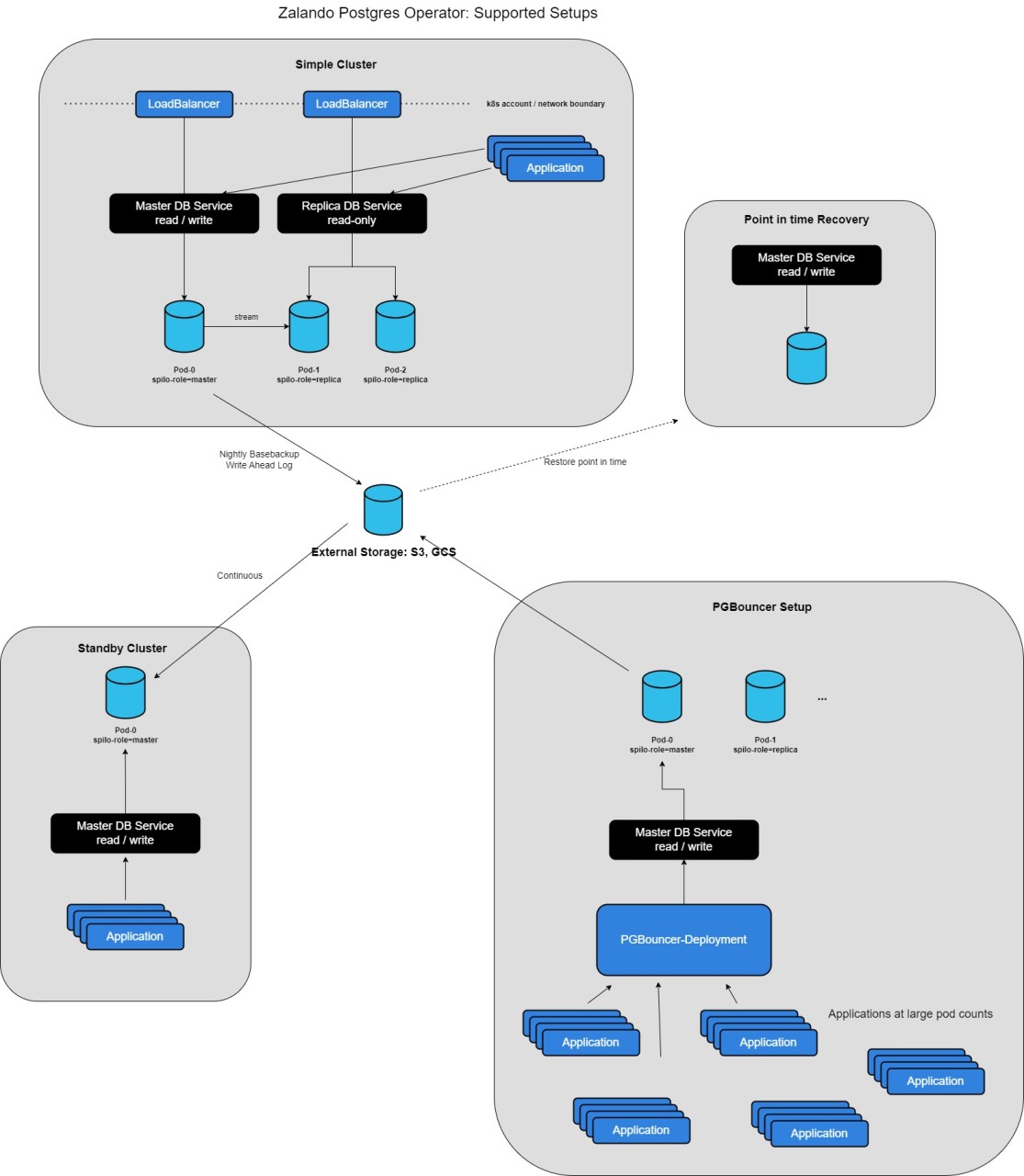
Eine Übersicht über alle unterstützten Konfigurationen:
StackGres
StackGres wird von OnGres entwickelt und bietet Failover und Replikation via Patroni. Der Operator sticht besonders durch seine CLI und das integrierte Web-Interface heraus, in dem Cluster, Backups und Datenbank-Operationen konfiguriert werden können. Außerdem bietet dieser Operator die meisten PostgreSQL-Plugins, die direkt auf das Cluster angewendet werden können.
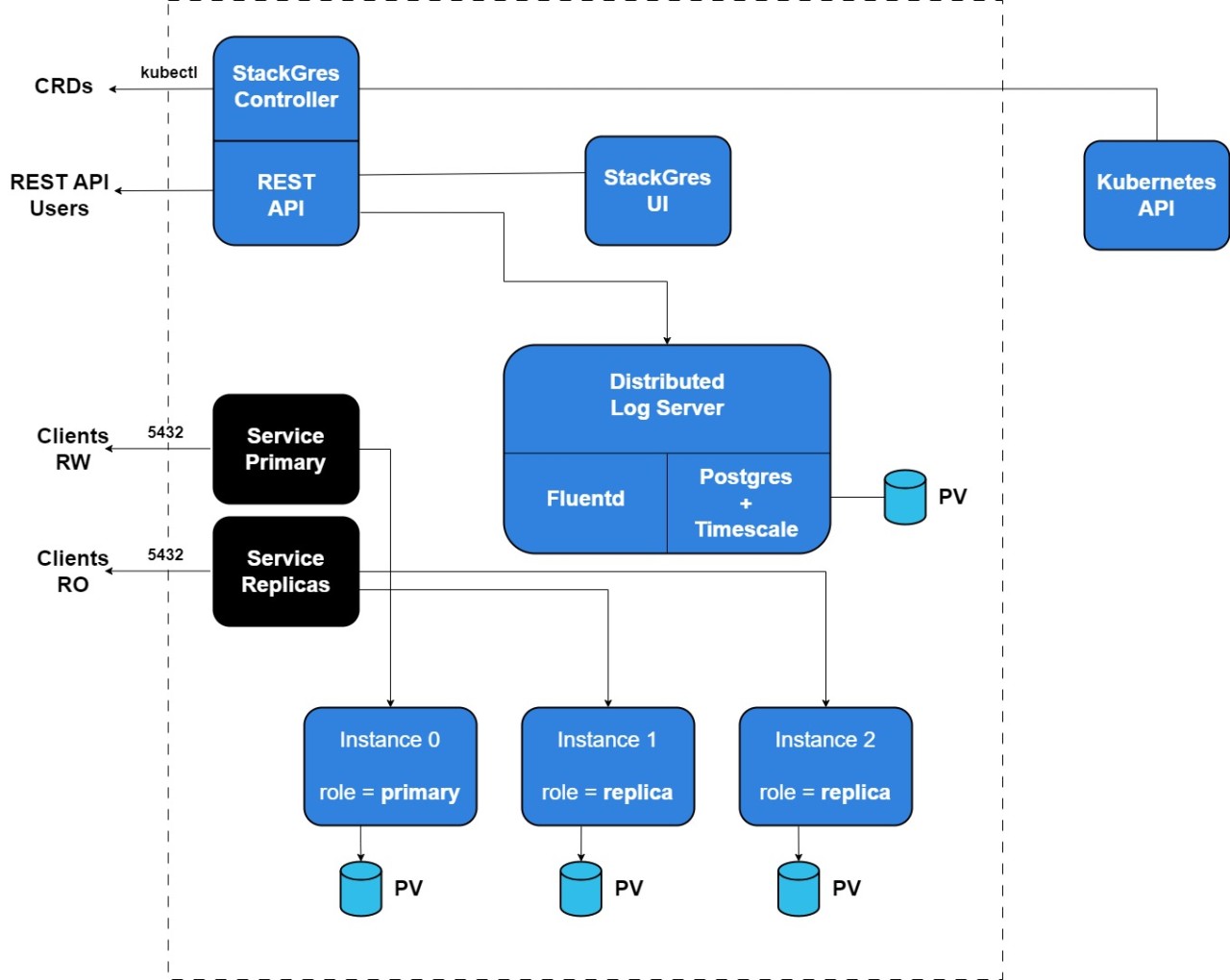
Hier ein Überblick über die Architektur des Operators:
KubeDB by AppsCode
KubeDB von AppsCode ist ein sehr vielseitiges Produkt, das nicht nur PostgreSQL, sondern auch eine Reihe anderer Datenbank-Cluster unterstützt. Dazu gehören MySQL, MariaDB, MongoDB und viele andere (siehe KubeDB).
Der Operator hat, ähnlich wie CNPG, eine mächtige CLI und ist eng mit anderen AppsCode-Produkten wie Stash für Backup und Restore gekoppelt. Die Entscheidung für diesen Operator liegt auf der Hand, wenn man bereits AppsCode-Produkte einsetzt oder einen Operator für verschiedene Datenbanksysteme benötigt.
Es ist jedoch zu beachten, dass AppsCode nur 30-Tage-Testlizenzen vertreibt und für einen konkreten Einsatz eine kostenpflichtige Lizenz erworben werden muss.
Failover-Test
Im Falle eines Ausfalls einer PostgreSQL Primary-Instanz reagiert das Cluster, indem ein Replika die Rolle als Primary einnimmt und die ausgefallene Instanz durch einen neuen Replika ersetzt wird. Dieser Mechanismus führt zu Downtimes, die jeder Operator versucht, minimal zu halten.
Wir haben uns dafür entschieden diese Failover-Zeiten zu messen und zu vergleichen. Hierfür setzen wir mithilfe jedes Operators jeweils ein Cluster mit einer Primary-Instanz und zwei Replikas auf. Daraufhin greifen wir kontinuierlich schreibend auf unser Cluster zu und lassen die Primary-Instanz mehrmals ausfallen. Anhand der durchgekommenen Zugriffe können wir messen, wie lange unser Cluster nicht erreichbar war und somit, wie lang die Failover-Zeit war.
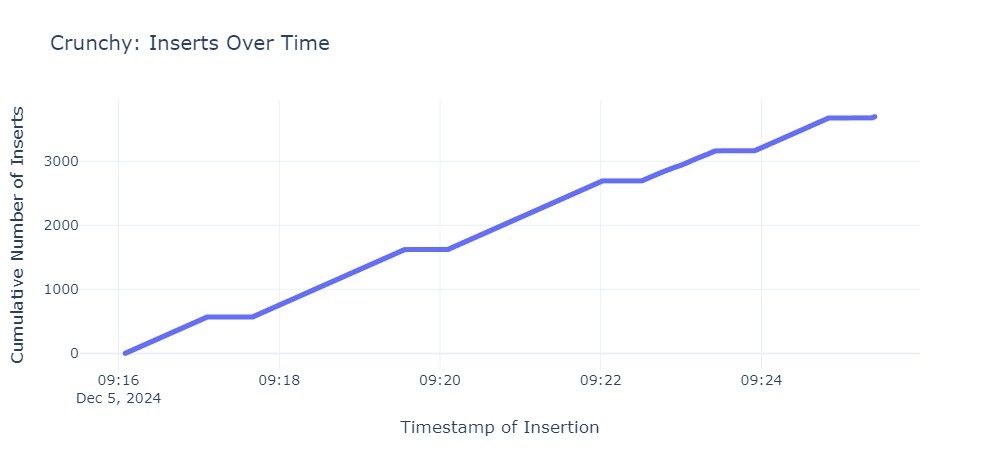
Die gemessenen Ausfallzeiten unterscheiden sich zwischen den Operatoren sehr. Folgende Grafiken zeigen die Ausfallzeit für jeden Operator. Jeder horizontale Abschnitt der Graphen beschreibt den Zeitraum, in dem die primary Instanz nicht erreichbar war:
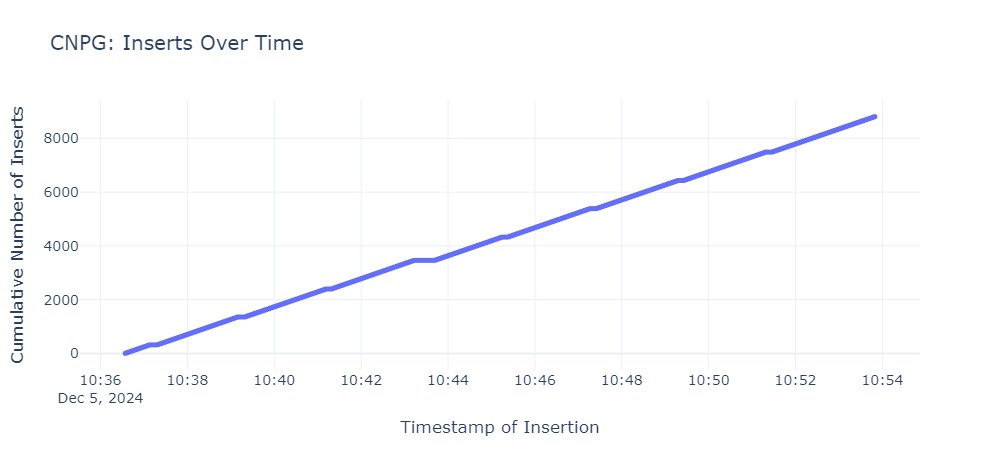
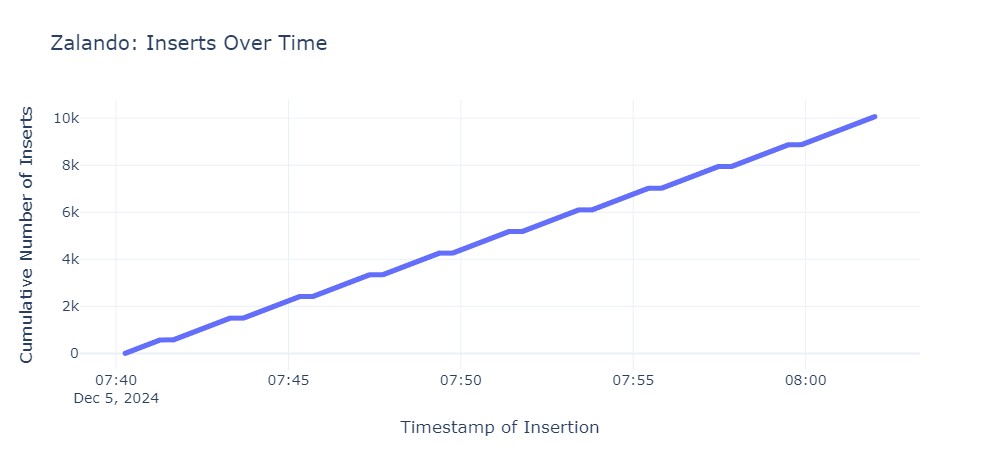
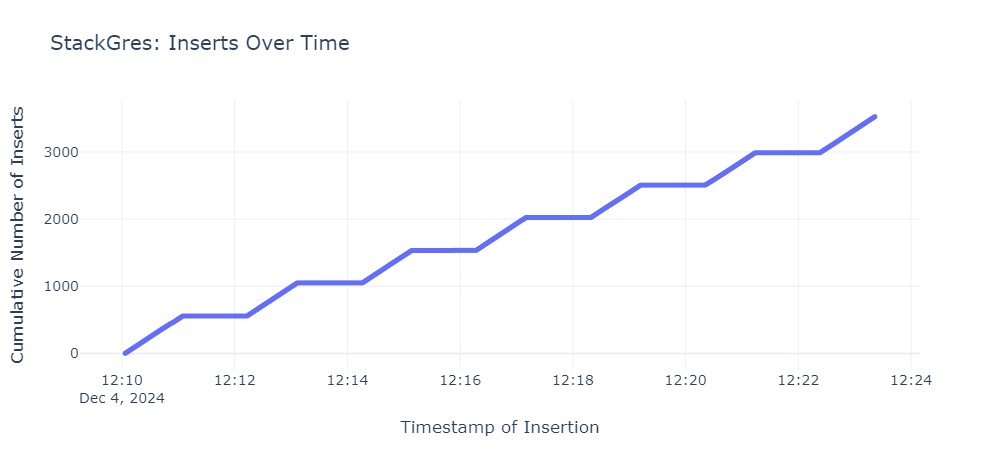
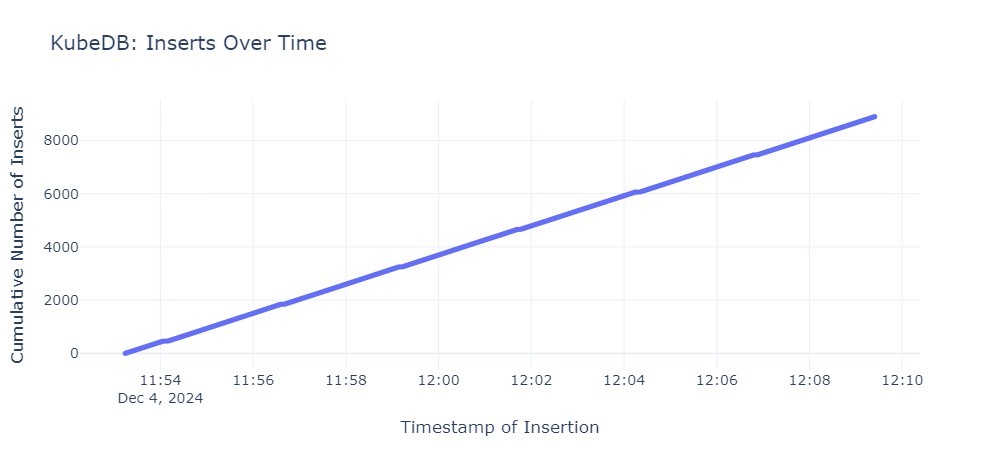
Die durchschnittlichen Failover-Zeiten sind wie folgt:
| Operator | ⌀ Failover-Zeit |
| Crunchy Postgres for Kubernetes | 31s |
| CloudNativePG | 10s |
| Zalando | 22s |
| KubeDB by AppsCode | 5s |
| StackGres | 68s |
Die Ergebnisse des Lasttests zeigen, dass KubeDB und CloudNativePG die besten Ergebnisse liefern. Die Operatoren von Zalando und Crunchy Postgres for Kubernetes liegen im Mittelfeld, während StackGres mit einer Dauer von 68 Sekunden das Schlusslicht bildet.
Eine kurze Failoverzeit kann im normalen Datenbankbetrieb je nach Anwendung von entscheidender Bedeutung sein. Sie sollte daher ein wesentliches Kriterium bei der Wahl des Operators sein.
Eckdaten
| Crunchy | CNPG | Zalando | KudeDB | Stackgres | |
| Version | 5.7 | 1.24.1 | 1.13.0 | 2024.11.18 | 1.14 |
| Postgres Version | 17.0, 16.1-4, 15.1-8, 14.0-11, 13.3-4 | 12-17 | 9.5-16 | 10.23, 11, 11.22, 12, 12.17, 13, 13.13, 14, 14.10, 14.13, 15, 15.5, 15.5, 15.8, 16.1, 16.2, 16.4, 16.4 | 17.0, 16.0-4, 15.0-8, 14.0-13, 13.0-16, 12.1-20 |
| pgSQL cluster | ✓ | ✓ | ✓ | ✓ | ✓ |
| Synchrone Replikation | Patroni | Eigene Implementation | Patroni | Eigene Implementation | Patroni |
| Streaming Replikation | Patroni | Eigene Implementation | Patroni | Eigene Implementation | Patroni |
| Automatisches Failover | Patroni | Eigene Implementation | Patroni | Eigene Implementation | Patroni |
| Backup Management (Backup & Restore) | pgBackRest, Support für AWS S3, GCS und Azure Blob Storage | Object Stores und Volume Snapshots (Kubernetes nativ siehe CSI) | pg_base_backup, WAL-E, S3, GCS | Stash (AppsCode Produkt), ähnlich mächtig wie CNPG | S3, GCS, Azure Blob Storage, DigitalOcean Spaces, Self-hosted MinIO |
| Built-in Monitoring-Metriken (Prometheus) | ✓ | ✓ | ✓ | ✓ | ✓ |
| NodeAffinity, Tolerations und pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ |
| Web UI | ✗ | ✗ | ✓ | ✗ | ✓ |
| Rolling updates | ✓ | ✓ | ✓ | ✓ | ✓ |
Fazit
Die Auswahl eines Favoriten ist nicht einfach, da jeder der fünf Operatoren vergleichbare Grundfunktionalitäten bietet. Unser persönlicher Favorit ist der CloudNativePG Operator, da er alle Funktionalitäten bietet, die für den täglichen Datenbankbetrieb notwendig sind. Gleichzeitig steht eine sehr große Community hinter diesem Operator, der ständig weiterentwickelt wird.
Wenn kurze Failover-Zeiten der wichtigste Aspekt sind, können wir ganz klar KubeDB und CloudNativePG empfehlen. Diese Operatoren haben in unseren Tests am besten abgeschnitten und bieten somit sehr robuste Lösungen.
Wenn ihr tiefer in die Welt von Kubernetes und PostgreSQL eintauchen möchtet, laden wireuch herzlich ein, an unseren Seminaren teilzunehmen. Sprecht uns dafür gerne an oder informiert euch auf unserer Seminar-Website.
Seminarempfehlungen
KUBERNETES ESSENTIALS KUB-01
Mehr erfahrenPOSTGRESQL ADMINISTRATION DB-PG-01
Mehr erfahrenWerkstudent
Kommentare