
Präsentationen auf Knopfdruck - Wie hilft Python dem Projektleiter?
Von frustrierten Projektleitern und unkontrollierbaren Exceltabellen
Wer kennt das Problem in der Rolle eines Projektleiters nicht? Heute Nachmittag findet das wöchentliche Projekt-Review statt und schon in den Frühstunden beginnt wieder der Stress, die PowerPoint-Präsentation, die den aktuellen Projektstand zeigen soll, mit Daten zu füllen. Also sucht man sich mal wieder mühsam im Dschungel der verteilten Systeme die notwendigen Informationen zusammen. „Irgendjemand hatte doch die Stundensätze der Projektressourcen in einer Exceldatei geändert und die Bug-Liste aus GitHub müsste auch noch mit auf die Slides". Also heißt es alle Datenquellen der Reihe nach zu lokalisieren und die benötigten Auszüge mit Copy-&-Paste an ihre Stelle in den Folien einzufügen. Das kann mitunter eine frustrierende und bisweilen sehr fehlerträchtige Angelegenheit sein. Auch sollten die Daten, die man vorstellt, zum Zeitpunkt der Präsentation noch halbwegs aktuell sein. Wäre es nicht schön, die lästige Arbeit des Datenkonsolidierens und der Dokumenterstellung eine Maschine machen zu lassen, die einem die fertige Präsentation zur gewünschten Uhrzeit einfach ins Postfach legt?
Das Problem der verteilten Projektdaten
Projektdaten liegen leider oft verstreut in den unterschiedlichsten Systemen und allzu gerne auch mal in Exceldateien. Excel ist zwar sehr komfortabel und aus den Unternehmen nicht mehr wegzudenken, birgt aber die Gefahr der unkontrollierten Verbreitung. Einmal auf die Reise geschickte Dateien machen sich gerne mal selbstständig und finden ihren Weg durch die Postfächer der Projektbeteiligten, die diese dann auch noch mit eigenen Änderungen versehen und an andere Kollegen und Kolleginnen weiterleiten. All das passiert ohne Wissen des ursprünglichen Dateierstellers. Spätestens wenn dann eine neue Version der Datei entsteht, kann man nicht zu einhundert Prozent garantieren, dass auch alle Beteiligten die Änderung mitbekommen und fortan mit den geänderten (und nun aktuellen!) Daten arbeiten. Das führt früher oder später zu Dateninkonsistenzen und Frustration.
Wie erlangt man die Kontrolle?
Hier kann ein eher zentralistischer Ansatz helfen, bei dem die Daten nicht mehr von einem Sender per E-Mail an alle verteilt wird, sondern bei dem sich die Beteiligten die aktuellen Daten aus einer Datenbank holen. Diese Datenbank fungiert als Master und immer aktuelle Quelle, d.h. Änderungen werden auch nur dort vorgenommen. Ein solches Szenario ist in Abbildung 1 dargestellt. Die zentrale Datenbank stellt die notwendigen Tabellenstrukturen zur Bevorratung von Projektdaten bereit. Daten, die aus eventuell existierenden Drittsystemen, wie z.B. dem oben erwähnten GitHub, kommen, erhalten ebenfalls entsprechende Tabellen zur Zwischenspeicherung. Excel wird in diesem Szenario nur noch als Vehikel für den Import und Export benötigt, aber nicht mehr zur persistenten Speicherung und Verteilung der Daten. Aus dem ursprünglichen Daten-Push durch den Ersteller wird nun ein Daten-Pull seitens des Nutzers.
Die Programmiersprache Python, zusammen mit den Modulen Pandas, ExchangeLib, SQLite, PyODBC und PyWin32, bietet hier eine gut bestückte Werkzeugkiste, die bei der Bewältigung dieser Aufgaben gute Dienste leisten kann. In den folgenden Abschnitten wird skizziert, wie Sie sich diese Werkzeuge im Projektalltag zu Nutze machen.
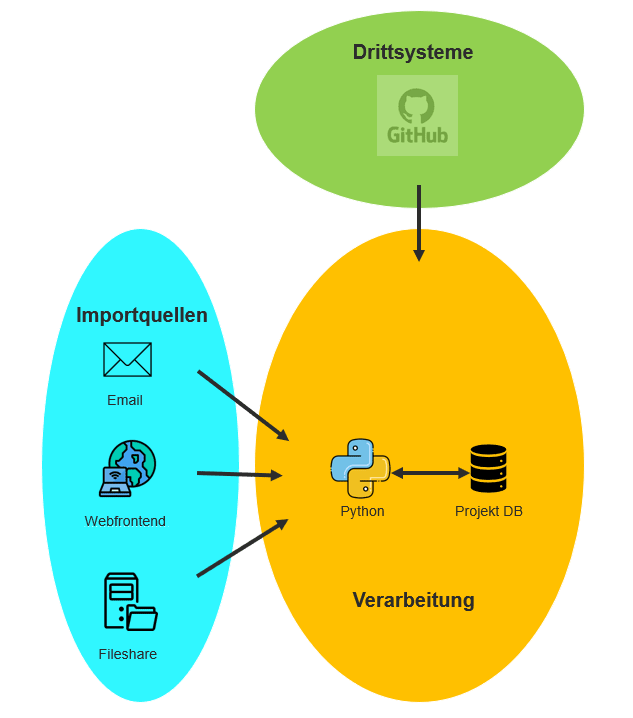
Die Wege der Daten ins System
Als Erstes stellt sich die Frage, wie die von den Projektbeteiligten produzierten Daten ihren Weg ins System finden. Prinzipiell eignen sich drei verschiedene Methoden: Mail-, Web- oder Fileserver, die je nach gegebenem Szenario einzeln oder in Kombination eingesetzt werden können.
Hat man sowieso schon eine Prozessmailbox, kann man mittels Python und der ExchaneLib das zugewiesene Postfach zyklisch nach eingehenden Mails (von vorher definierten Personen) abfragen und angehängte Attachments automatisch prüfen und den Inhalt in die Datenbank schreiben. Gibt es einen gemeinsam genutzten Fileserver, lässt sich ein für den Datei-Upload bestimmtes Verzeichnis ebenfalls durch ein Python-Skript überwachen und dort abgespeicherte Daten verarbeiten. Ein wenig mehr Aufwand hat man sicherlich für die Programmierung eines eigenen Web-Frontends, über das man die Dateien hochladen kann. Bei größeren Projekten oder wenn man sowieso schon einen Webserver für andere Dinge im Einsatz hat, kann sich der Aufwand jedoch rechnen.
Aber nicht nur von Projektbeteiligten gepflegte Daten sind zu verarbeiten; oft gibt es auch noch andere Systeme, von denen bestimmte Informationen für das Projekt-Reporting benötigt werden. Auch hierzu stellt Python wieder eine Reihe von Möglichkeiten bereit: Entweder gibt es für ein bestimmtes Produkt ein eigenes Python Modul, welches man zum Zugriff benutzen kann, oder man nutzt generische Schnittstellen, wie z.B. eine REST-API, um auf verteilte Datenbestände zuzugreifen.
Datenschaufeln mit Pandas, SQLite und PyODBC
Wie im Eingangsbeispiel erwähnt, ist das Laden von (Excel-) Dateien in die zentrale Datenbank ein wesentlicher Baustein des Gesamtsystems. Für diese Aufgabe eignet sich das Python Modul Pandas, insbesondere die Methode „.read_excel", mit deren Hilfe man eine Excel-Datei in einem Arbeitsgang in einen sogenannten „Dataframe" laden kann. Der Dataframe ist ein mächtiges Werkzeug, mit dem sich die dort geladenen Daten komfortabel manipulieren lassen. Zum Beispiel kann man bestimmen, welche Spalten in die Datenbank übernommen werden und welche Datentypen diese bekommen sollen. Mit der Methode „.to_sql" befördert man den Inhalt des erzeugten Dataframes in eine bereitstehende lokale Datenbank. Hierzu eignet sich z.B. die SQLite, die Python in einem eigenen Modul mitbringt. Hiermit lässt sich schnell und ohne viel Aufwand eine lokale Datenbankinstanz (als Datei oder in-Memory) und eine Tabelle erzeugen, die dann durch Pandas mit dem zuvor erzeugten Dataframe befüllt werden kann.
Nachdem die aus Excel geladenen Daten nun in einer lokalen Datenbank bereitstehen, stellt sich die Frage, wie diese mit der eigentlichen Projektdatenbank abgeglichen werden können. Auch hier stellt Python ein geeignetes Modul namens PyODBC bereit. Über eine ODBC-Verbindung lässt sich sehr schnell Kontakt zu allen gängigen SQL-Datenbanken herstellen und man kann die Zieltabelle, mit der die geladenen Excel-Daten verglichen werden soll, in eine weitere Tabelle in der lokalen SQLite-Instanz laden. Nun bestimmt man durch einen Vergleich die Datensätze, die sich verändert haben, die, die neu hinzugefügt werden müssen und die, welche zu löschen sind. Die resultierenden Veränderungen werden dann in die zentrale Projektdatenbank zurückgeschrieben und stehen sofort wieder allen zur Verfügung. Danach hat die lokale Datenbank ihre Pflicht getan und kann geschlossen werden.
Hat man nun noch externe Datenquellen, wie z.B. die eingangs erwähnte Bug-Liste aus GitHub, kann man dort vorhandene Daten mit ähnlichen Mitteln (z.B. dem Modul PyGitHub) in eine lokale Datenbanktabelle überführen, wieder mit vorhandenen Daten vergleichen und die resultierenden Änderungen in die Projektdatenbank zurückschreiben.
Natürlich bedarf es eines gewissen Grundaufwands, um die zu pflegenden Datenbestände zu definieren und entsprechende Routinen zu programmieren. Aber man erkennt schnell, dass einmal erstellte Routinen mit geringem Aufwand verändert werden können, um in einem neuen Szenario wieder zur Anwendung zu kommen. Viele Routinen lassen sich auch völlig generalisieren; einmal entwickelt, kann man diese universell einsetzen.
PyWin32: Der Weg aus den Daten hin zur fertigen Präsentation
Nachdem man nun alle für das Reporting benötigten Datenquellen identifiziert und entsprechende Update-Routinen realisiert hat, stellt sich die Frage, wie sich das Reporting automatisieren lässt. Grundsätzlich sind für den Alltag zwei Reportvarianten von größerem Interesse: Excel-Reports für diejenigen, die Daten analysieren müssen und PowerPoint-Präsentationen zur Visualisierung des Projektfortschritts.
Um mittels Python nun Excel- oder PowerPoint-Dateien zu generieren, muss man an das mächtige Objektmodell von Microsoft Office herankommen. Hierzu bedient man sich der PyWin32-Bibliothek. Mithilfe dieser Bibliothek lassen sich zunächst einmal entsprechende Excel- oder PowerPoint-Instanzen erzeugen. Über das Objektmodell kann man nun die Elemente der Hierarchie, z.B. eine Zelle in einer Tabelle auf einer Folie in einer Präsentation, adressieren und mit Leben füllen. PyWin32 steht dabei dem in MS Office integrierten VBA in nichts nach. Einmal kreierte Routinen, z.B. zur Erstellung von Pivot-Tabellen, lassen sich beim nächsten Einsatz wiederverwenden. Jeder, der schon mal mittels VBA Office Dateien erzeugt oder manipuliert hat, kann sogar mit relativ wenig Aufwand vorhandenen Code weiterbenutzen. Es sind ggf. nur ein paar syntaktische Änderungen vorzunehmen, um den ursprünglichen VBA-Code Python-konform zu gestalten.
Wie Abbildung 2 zeigt, lassen sich Reports entweder zeitgesteuert erstellen und dann an die Zielpersonen per E-Mail verteilen oder man speichert diese auf einem Fileserver ab, auf den von berechtigten Personen zugegriffen werden kann. Aber auch die On-Demand-Erzeugung von Reports ist möglich. Hier bieten sich wieder die bereits erwähnten Module als probates Mittel an. Reportanforderungen können entweder via E-Mail- oder Web-Frontend gestellt werden.
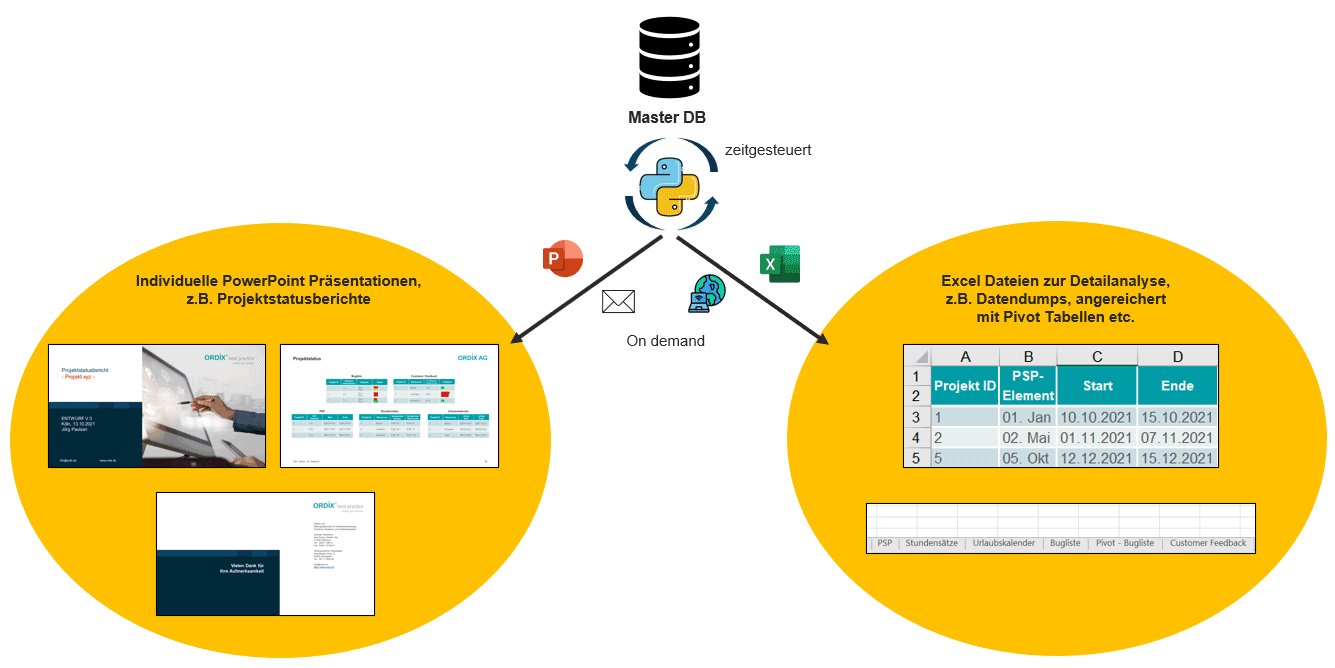
Fazit
Datenkonsistenz ist ein sehr kritisches Thema im Projektalltag und Projektmitarbeiter sollten ihre wertvolle Zeit nicht damit verschwenden, nach aktuellen Daten zu suchen oder wiederkehrende Arbeiten manuell auszuführen. Das kann und sollte automatisiert passieren. Damit die Algorithmen korrekt arbeiten, muss es genau definierte Stellen geben, an denen die relevanten Projektdaten vorgehalten werden. Aber auch ohne Python ist eine zentrale Datenhaltung im Projektgeschäft erstrebenswert.
Python stellt für diesen Anwendungsfall gut geeignete Hilfsmittel zur Verfügung, die das Projektteam unterstützen, wiederkehrende Aufgaben zu automatisieren und Ordnung ins Chaos zu bringen. Mit ein wenig Programmierarbeit lassen sich so auf den konkreten Anwendungsfall angepasste Workflows gestalten, welche die Mitarbeiter entlasten und ihnen damit wieder mehr Zeit für andere Aufgaben im Projektalltag freiräumen.
Wer die Zeit einmal investiert, kann den Traum der „PowerPoint-Präsentation auf Knopfdruck" realisieren!
Interesse geweckt?
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren SeminarenPrincipal Consultant bei ORDIX
Kommentare