
Sharding – Das Fruit Ninja der Datenbanken
Datenbanken an steigende Anforderungen anzupassen ist wahrlich keine einfache Aufgabe. Um zu garantieren, dass die Performance der Anwendung der wachsenden Last genügt, sind oftmals weitreichende Maßnahmen zu treffen. Durch Optimierung des Servers mittels besserer Hardware kann dieses Problem meist nur kurzfristig gelöst werden. Steigt die Datenmenge der Datenbank weiter rapide an, so wird die Kapazität des Servers langfristig nicht ausreichen, um mit der steigenden Last mithalten zu können. Eine Lösung, um diesem Problem entgegenzuwirken, ist Sharding.
Was ist Sharding?
Beim Datenbank-Sharding werden Daten auf mehrere Instanzen aufgeteilt. Im Gegensatz zur Datenbank-Replikation, haben die Instanzen nicht die gleichen Datenbestände. Die Datenmenge einer Tabelle ist auf jedem Knoten im Cluster unterschiedlich. Die Tabellendaten werden horizontal über mehrere Knoten "partitioniert". Eine Hochverfügbarkeit wird mittels dieses Konstrukts also nicht garantiert. Es gibt keinen Server, der alle Daten beherbergt. Nur die Struktur der Tabellen ist über die beteiligten Systeme repliziert. Eine Instanz wird in einem solchen Setup auch Shard (engl. Scherbe oder Bruchstück) genannt.
Funktionsweise von Datenbank-Sharding
Um eine Datenbank zu sharden, sind verschiedene Ansätze möglich. Generell ist eine Zwischenschicht nötig, die einkommende Abfragen entgegennimmt und dann an den jeweils korrekten Shard weiterleitet, der über die entsprechenden Datensätze verfügen soll. Dieses "Layer" sorgt damit für die Transparenz für die Applikation, die dementsprechend nicht wissen muss, wo die Daten physikalisch verwaltet werden.
Die Middleware überprüft die Abfragen nach einem bestimmten Schlüssel, der die Verteilung der Daten auf die Knoten bestimmt. Dieser Wert wird auch Sharding-Key genannt und kann (optional) mit dem Primärschlüssel einer Tabelle übereinstimmen. Dieser Sharding Key muss allerdings nicht zwingend der Primary Key sein, auch wenn dies häufig empfehlenswert ist.
Anhand des Sharding-Keys kann nun bestimmt werden, an welchen Shard die Abfrage weitergeleitet werden muss. Sollte der Sharding-Key in der SQL-Abfrage nicht spezifiziert sein, wird der SQL-Befehl an alle Shards weitergeleitet, was der ursprünglichen Idee widerspricht. Die Middleware kann also als Koordinator innerhalb des Sharding-Clusters verstanden werden, mit der sich außerhalb befindliche Clients verbinden.
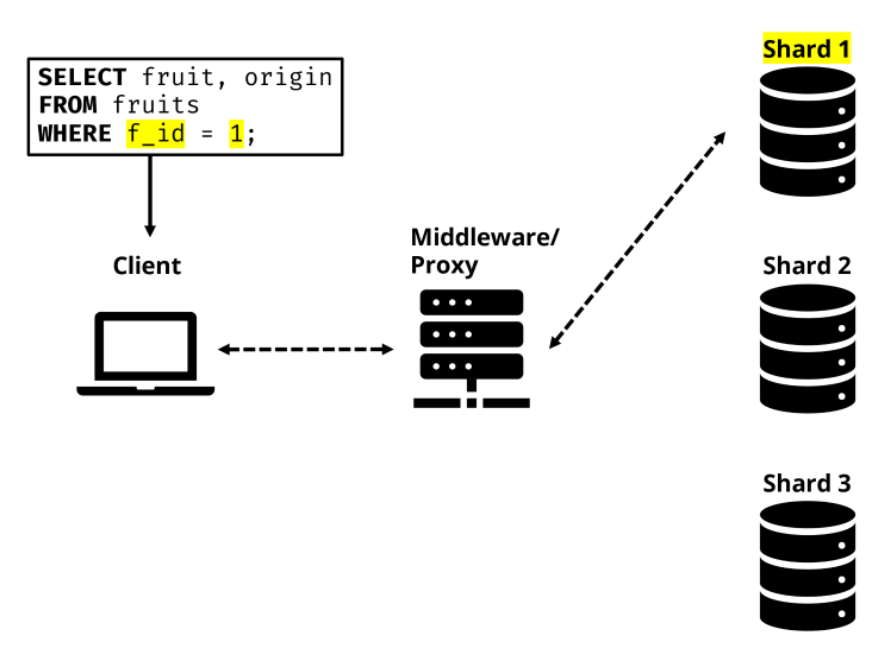
Das Schaubild zeigt, wie ein minimalistisches Sharding-Cluster aufgebaut sein könnte. Es zeigt einen Client, der eine SQL-Abfrage an die Middleware des Clusters sendet. Die Middleware wertet die Abfrage aus und erkennt anhand des Sharding-Schlüssels "f_id" in der WHERE-Klausel, an welche Datenbank-Instanz die Abfrage weitergeleitet werden muss. Die Instanz wertet das Ergebnis der Abfrage aus und sendet es zurück an die Middleware, welche das Ergebnis an den angefragten Client weiterleitet.
Doch wie kann die Middleware aus dem Sharding-Key ableiten, an welchen Shard sie die Abfragen weiterleiten muss? Dazu gibt es verschiedene Möglichkeiten, die je nach Sharding-Lösung des Datenbanksystems unterstützt werden.
Strategien zur Umsetzung - Partitionierung ist alles
Viele Datenbanksysteme wie MySQL oder Oracle unterstützen partitionierte Tabellen. Dabei werden die Datensätze, anhand eines festgelegten Schlüssels, mithilfe eines Verfahrens, voneinander getrennt und in Partitionen unterteilt, die physisch getrennt abgespeichert werden. Im Beitrag „Archivier das mal!" wird dies anhand eines Beispiels aufgezeigt. Beim Sharding werden die Datensätze horizontal partitioniert, also auf verschiedenen Servern abgelegt. Die Partitionierungsverfahren ähneln dabei der lokalen Partitionierung.
Hash-based Sharding
Eine Strategie ist das Sharden einer Tabelle, mittels einer hash-basierten Partitionierung. Dabei werden Werte des Sharding-Schlüssels in einer Hash-Funktion abgebildet. Das Ergebnis der Hash-Funktion gibt Auskunft darüber, welchem Shard der Datensatz zugeordnet werden soll.
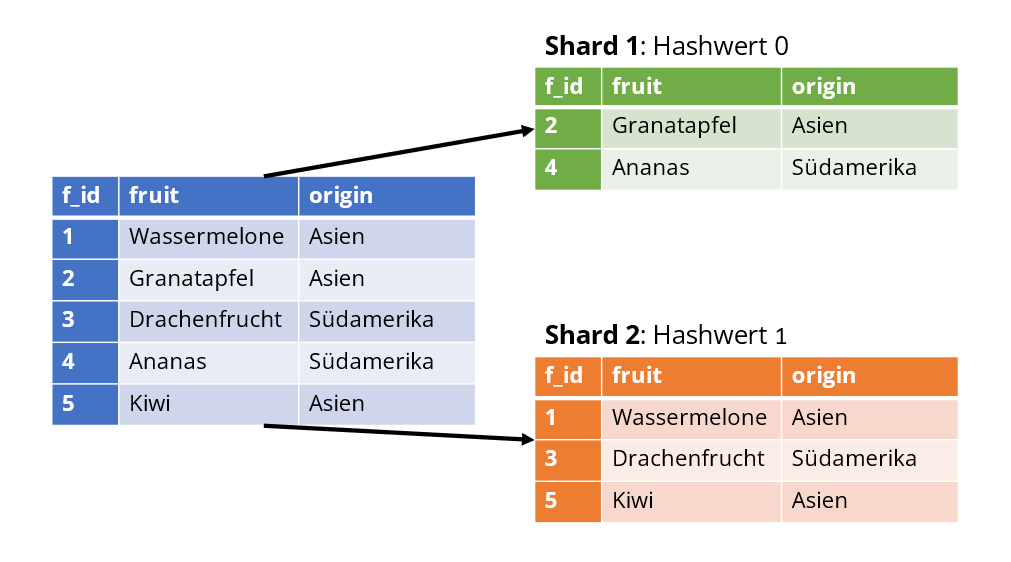
Betrachtet wird ein einfaches Beispiel mit einer Tabelle, die Informationen über tropische Früchte bereitstellt. Der Sharding-Key wird hier durch folgende Hashfunktion: h(key)=key mod 2 berechnet und ist in diesem Fall die f_id. Sobald ein Datensatz in die Tabelle hinzugefügt wird, wird der Wert der f_id auf der Hashfunktion abgebildet und entsprechend auf dem Shard mit dem passenden Hashwert abgespeichert.
Range-based Sharding
Eine andere Möglichkeit des Shardings ist das Aufteilen der Datensätze in bestimmte Wertebereiche. Dabei wird jedem Shard ein Wertebereich zugeordnet.
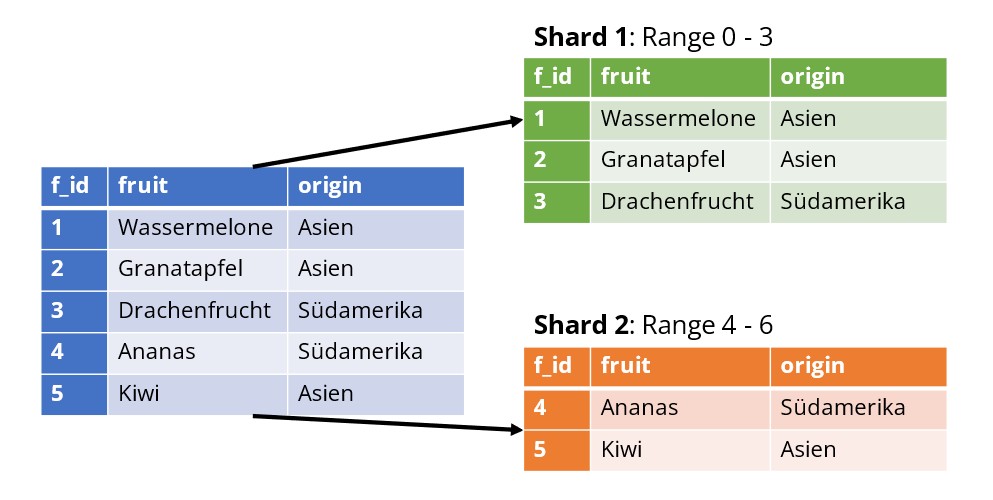
Das vorherige Beispiel wird so angepasst, dass jedem Shard ein bestimmter Wertebereich zugeordnet ist. So erhält der Shard 1 alle Datensätze, dessen f_id die Werte 0 bis 3 nutzt und der Shard 2 alle Zeilen mit der f_id im Bereich von 4 bis 6.
Dictionary-based Sharding
Bei dieser Variante wird eine Spalte als Sharding-Schlüssel betrachtet, dessen Werte einem Shard zugeordnet werden. Jeder Shard nimmt genau nur die Datensätze auf, die den entsprechenden Wert in der Sharding-Spalte enthalten.
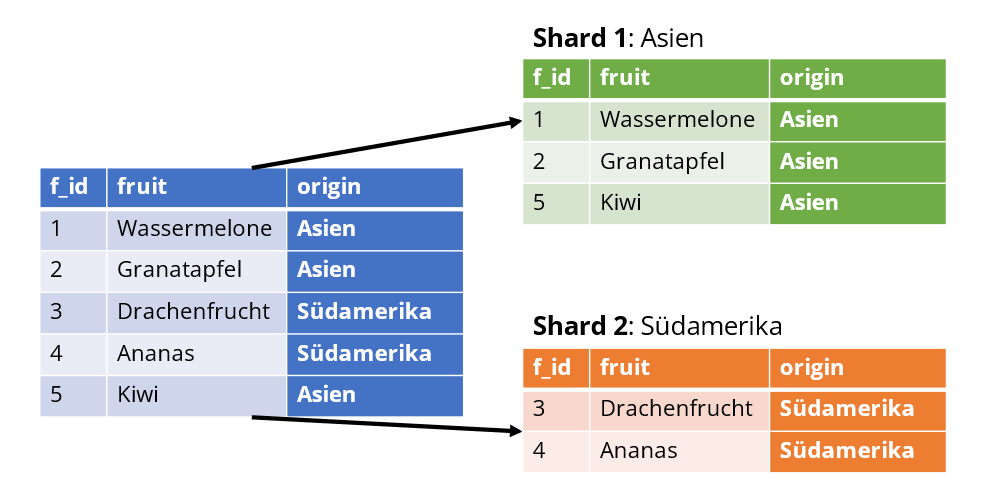
Das Beispiel betrachtet jetzt die Spalte origin als Sharding-Key und ordnet dem Shard 1 den Wert „Asien" zu, während der Shard 2 den Wert „Südamerika" erhält. Diese Variante ist z.B. dann interessant, wenn die Datensätze auf eine bestimmte Region referenzieren und garantiert werden soll, dass sich auch der Server selbst in der betreffenden Region befindet. Natürlich gibt es auch andere sinnvolle Szenarien für diesen Algorithmus.
Überblick von Sharding-Technologien
Lösungen zum Sharden von Daten werden inzwischen für verschiedene Datenbanksysteme angeboten. Hier ein kleiner Überblick:
- Oracle bietet für sein Datenbanksystem das Feature Oracle Sharding an.
- Im Rahmen eines internen YouTube-Projekts entstand die Open-Source-Lösung Vitess, die das horizontale Partitionieren von MySQL Datenbanken ermöglicht.
- Der MySQL-Fork MariaDB stellt eine zusätzliche Storage Engine Spider bereit, mit der Sharding über verschiedene Instanzen implementiert werden kann.
- Bei PostgreSQL Datenbanken können, mithilfe des Foreign Data Wrapper, Fähigkeiten genutzt werden, um Daten auf mehrere PostgreSQL-Server aufzuteilen.
Vorteile und Nachteile des Shardings
Der wesentliche Vorteil des Shardings liegt darin, dass eine hohe Performance ermöglicht wird. Die gesamte Last wird nicht mehr nur von einem Server getragen, sondern kann auf mehrere Instanzen skaliert werden. Die einzelnen Instanzen verbrauchen nun weniger Speicher, da sie nur einen Teil der Daten bereithalten und verwalten müssen.
Die Umsetzung kann eine Herausforderung sein. Je komplexer die Datenstruktur ist, umso aufwendiger und komplizierter ist es, diese aufzuteilen. So sind eventuell Anpassungen am Datenbankschema notwendig, um dieses überhaupt sinnvoll aufspalten zu können. Komplexe Abfragen können eventuell nicht mehr durchgeführt werden. JOINs sind zwar möglich, jedoch werden bei fehlender Filterung alle Shards angesprochen, wodurch die Vorteile des Shardings nicht mehr gegeben sind.
Fazit - Sharding als Möglichkeit die Kapazität zu steigern
Das Sharding ist eine sehr gute Möglichkeit, um die Kapazität der Datenbank zu steigern, wenn diese droht "überzulaufen" und eine Hardware-Optimierung nur schwer umsetzbar ist. Die Realisierung kann jedoch sehr aufwendig sein, insbesondere dann, wenn das Datenmodell komplex ist. Falls das Datenwachstum allerdings so rasant steigt, dass wir Terabyte-große Tabellen betrachten, ist es sicher empfehlenswert, sich genauer mit Sharding-Technologien zu beschäftigen oder gar den Sprung zu anderen Datenhaltungssystemen zu wagen (NoSQL, Big Data).
Quellen
https://devopedia.org/database-sharding
https://mariadb.com/kb/en/spider-storage-engine-overview/#sharding-setup
https://about.gitlab.com/handbook/engineering/development/enablement/database/doc/fdw-sharding.html
Seminarempfehlung
Sie haben Fragen und/oder Probleme mit der Verwaltung von großen Datenmengen? Sprechen Sie uns an, wir beraten Sie gerne.
Zu den SeminarenJunior Consultant bei ORDIX
Kommentare