
Testdatengenerierung mit TPC-H
Wie lassen sich mit TPC-H Testdaten für eine beliebig skalierbare Benchmark von SQL-Datenbanken erstellen? In diesem Blogbeitrag möchten wir am Beispiel PostgreSQL zeigen, wie man mit dem TPC-H-Toolkit Daten und Abfragen für eine Performance Benchmark generieren kann.
Was ist TPC-H?
Das TPC-H ist eine Benchmark für OLAP-Datenbanken (Online Analytical Processing), welche durch das Transaction Processing Performance Council (TPC) gepflegt wird. Das TPC ist ein Zusammenschluss von IT-Unternehmen. Mitglieder sind u. a. Microsoft, Oracle und IBM.
TPC-H umfasst dabei die Spezifikation, wie die Benchmark durchzuführen ist und Programme, mit denen Daten und Abfragen für die Benchmark generiert werden können. Dieser Artikel befasst sich primär mit den Programmen zur Datengenerierung und nicht mit der spezifikationsgetreuen Durchführung einer Benchmark.
Voraussetzungen
Die vorgestellten Programme werden in unserem Beispiel unter Windows ausgeführt. Die verwendete Datenbank liegt in einer Ubuntu-Server-VM. Eine Umsetzung unter einem Linux-System ist weitestgehend analog möglich. Für die Durchführung werden folgende Komponenten benötigt:
- TPC-H (tpc-h-tool_vx.y.z.zip)
- ANSI C-Compiler z. B. über Cygwin mit installiertem „gcc-core“-Paket
- Standardinstallation von PostgreSQL
- Datenbankverwaltungssoftware (z. B. DBeaver)
- (Optional) Skripte.zip (Download-Möglichkeit 🠗)
Datenmodell
Das Datenmodell der TPC-H-Benchmark soll ein kleines Data Warehouse simulieren und besteht aus acht Tabellen: NATION, REGION, PART, SUPPLIER, PARTSUPP, CUSTOMER, ORDERS und LINEITEM. Die Beziehungen zwischen den Tabellen sind im folgenden Diagramm dargestellt:
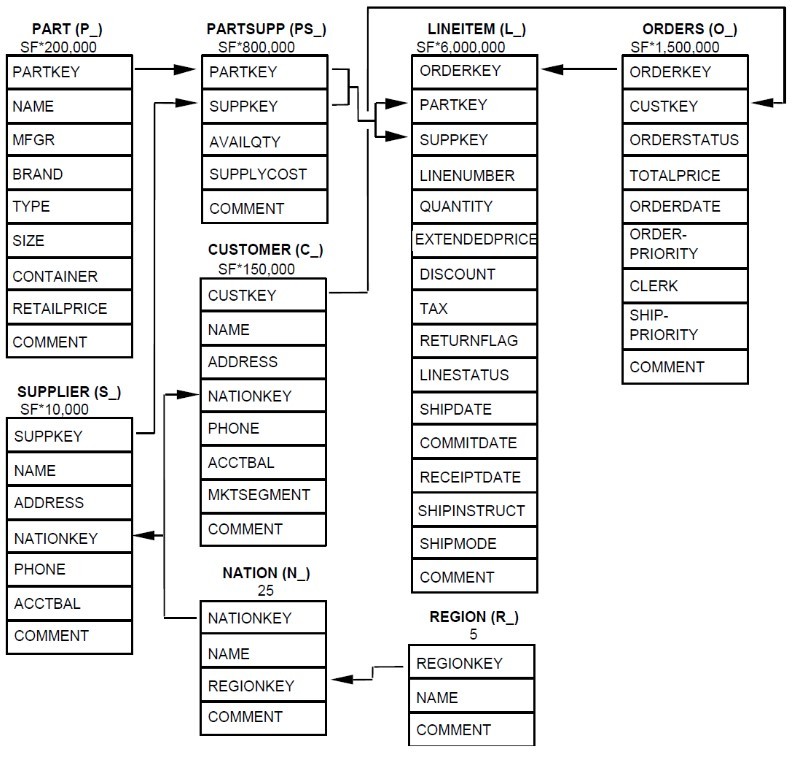
Die Pfeile stellen die 1:n Beziehungen zwischen den Relationen (Tabellen) dar. Die Zahl unterhalb des Tabellen-Namen entspricht der Anzahl an Zeilen des jeweiligen Objektes. Manche werden mit dem sogenannten „Scale Factor" (SF) multipliziert. Über den SF kann also gesteuert werden, wie groß die Datenmengen in der Benchmark sein sollen. Dabei entspricht eine 1 ungefähr 1 GiB (als Flatfiles). Nach der offiziellen Spezifikation sind folgende Werte erlaubt: 1, 10, 30, 100, 300, 1000, 3000, 10000, 30000, 100000. Technisch sind aber beliebige Werte möglich.
Kompilierung von TPC-H
Zum Zeitpunkt des Schreibens ist v3.0.1 die aktuelle Version der TPC-H-Benchmark. Wir entpacken tpc-h-tool_v3.0.1.zip in ein Verzeichnis. Im Folgenden wird /TPC-H_Tools_v3.0.1/dbgen als das Arbeitsverzeichnis genannt. Im Arbeitsverzeichnis erstellen wir eine Kopie von „makefile.suite“ und speichern diese als „makefile“ ab. Anschließend editieren wir das makefile und setzen folgende Werte:
CC = gcc
DATABASE = ORACLE
MACHINE = LINUX
WORKLOAD = TPCH
Nachfolgend öffnen wir tpcd.h und suchen in den database portability defines nach den Definitionen für Oracle. Diese sind anhand der Zeile „#ifdef ORACLE“ zu identifizieren. Innerhalb des Oracle-Blocks ersetzen wir die folgende Zeile mit SET_ROWCOUNT durch den folgenden Eintrag:
#define SET_ROWCOUNT "FETCH FIRST %d ROWS ONLY\n"
Nun kann im Cygwin-Terminal in das Arbeitsverzeichnis gewechselt werden und mit dem Aufruf des "make"-Befehls TPC-H kompiliert werden.
make
Theoretisch unterstützt TPC-H auch die Dialekte von Informix, DB2, Teradata, SQL-Server, Sybase, Oracle und Vectorwise, jedoch sind die unterstützten Dialekte veraltet. Insbesondere existiert keine Vorlage, in der die Zeilenbegrenzer-Klausel mit PostgreSQL kompatibel ist. Daher haben wir durch das Anpassen des SET_ROWCOUNT-Defines die Oracle-Vorlage geändert: Es wird die Zeilenbegrenzer-Klausel mit „FETCH FIRST n ROWS ONLY“ erzeugt. Dies lässt sich für andere Datenbanken ebenfalls beliebig anpassen, erfordert jedoch ein separates Kompilieren des Codes.
Generieren von Daten
Wir erstellen im Arbeitsverzeichnis einen neuen Ordner „data“ und führen anschließend folgende Befehle über das Cygwin-Terminal aus:
export DSS_PATH=./data
./dbgen.exe -s 1
Mit dem Setzen der Umgebungsvariable DSS_PATH legen wir den Pfad fest, in den dbgen die Daten schreibt. Anschließend rufen wir dbgen mit dem scale factor 1 auf. Im data-Unterverzeichnis sollten nun acht tbl-Dateien liegen, die mit Pipe als Trennzeichen die Daten für die Benchmark je Table enthalten.
Beladen von PostgreSQL
Wir verbinden uns mit unserer PostgreSQL-DB, erstellen ein Schema für die Benchmark und setzen dieses als Standardschema. Beim Erstellen des Schemas ist der Benutzername hinter AUTHORIZATION ggf. anzupassen.
CREATE SCHEMA tpch_1_sf AUTHORIZATION postgres;
SET SEARCH_PATH TO tpch_1_sf;
Im Arbeitsverzeichnis liegt die Datei „dss.dll“. Diese beinhaltet die SQL-Datei mit den DDL-Anweisungen, um die Tables entsprechend dem Datenmodell zu erzeugen. Wir führen dies gegen die Datenbank aus. Anschließend können die tbl-Dateien in die DB importiert werden.
Es sei angemerkt, dass TPC-H beim Generieren der Daten das Delimiter-Symbol (Pipe „|“) auch hinter die jeweils letzte Spalte setzt. Damit kann z. B. der copy-Befehl der psql-CLI nicht umgehen, von daher muss hierfür die letzte Pipe im Vorfeld entfernt werden:
sed -i 's/.$//' *.tbl
Ein Beispielbefehl für die psql-CLI zum Import der Daten ist im Skripte.zip Download (s. o.) in der Datei „psql_copy.sh“ enthalten.
Im Rahmen des offiziellen TPC-H-Benchmarks ist das Anlegen von Indizes nur auf die Primär- und Fremdschlüssel erlaubt. Dazu ist im Skripte.zip Download die Datei „Indizes.sql“ hinterlegt, welche auf alle entsprechenden Felder Indizes legt. Diese können noch nach eigenen Vorstellungen oder für andere Datenbanken angepasst und erweitert werden.
Generieren von Queries
Für die Generierung von fertigen Abfragen wird qgen.exe genutzt. Dieses Programm nutzt wiederum Vorlagen von SELECT-Statements und ergänzt diese in Abhängigkeit vom scale factor und einem Zufallswert (random seed) um bestimmte Parameter. Die mitgelieferten Vorlagen im Verzeichnis „queries“ sind nicht direkt einsatzbereit, deshalb wechseln wir in das entsprechende Verzeichnis und führen folgende Befehle aus:
sed -i '/:n -1/d' *.sql
sed -i 's/\(.*\);/\1 /' *.sql
echo ';' | tee -a *.sql
sed -i 's/day (3)/day/' 1.sql
Durch die oben genannten Befehle wird die Zeilenbegrenzer-Klausel aus allen Statements entfernt, in denen sie ohnehin nicht zum Einsatz kommt. Zusätzlich wird sichergestellt, dass immer ein Semikolon am Ende jeder Datei steht. In der ersten Vorlage wird zudem eine Oracle-spezifische Syntax entfernt.
Wir wechseln zurück in unser Arbeitsverzeichnis und führen den folgenden Befehl aus:
export DSS_QUERY=./queries
Analog zur DSS_PATH-Umgebungsvariable legen wir mit der DSS_QUERY-Umgebungsvariable fest, von wo qgen.exe die Abfrage-Templates lesen soll.
./qgen.exe -s 1 > select_sf_1.sql
Mit diesem Befehl werden nun basierend auf den Vorlagen aus DSS_QUERY Abfragen erzeugt und im Arbeitsverzeichnis in die Datei „select_sf_1.sql“ geschrieben. Mit dem Parameter -s muss der scale factor übergeben werden. Mithilfe des optionalen Parameters -r kann zusätzlich ein Seed übergeben werden, der standardmäßig auf die UNIX-Zeit in Sekunden gesetzt wird. Ein Aufruf von qgen.exe mit demselben scale factor und Seed ergibt immer die gleichen Parameter. Das explizite Angeben eines Seeds kann dann sinnvoll sein, wenn man unterschiedliche Abfragevorlagen nutzen möchte, z. B. mit unterschiedlicher Zeilenbegrenzer-Klausel. Damit die Statements inhaltlich gleich generiert werden, muss der Seed bei beiden Ausführungen von qgen.exe identisch sein. Der von qgen.exe genutzte Seed steht immer im Output in der ersten Zeile.
Durchführung der Benchmark
Die eigentliche Durchführung des Benchmarks gestaltet sich nun recht simpel: Das SQL kann aus der zuvor von qgen.exe generierten Datei kopiert und anschließend gegen die Datenbank abgesetzt werden.
Unsere Ergebnisse* für PostgreSQL in einer Ubuntu Server-VM, beschränkt auf 2560 MB Arbeitsspeicher und einen Prozessorkern (i5-8350U) mit angelegten Indizes, ergab folgende Zeiten:
| Lauf | RND-Seed | SF | Zeit(s) |
| 1 | 1639587483 | 1 | 82 |
| 2 | 1639587917 | 1 | 70 |
| 3 | 1639588213 | 1 | 70 |
*hierbei handelt es sich nicht um eine offizielle TPC-H-Benchmark nach den Spezifikationen der TPC
Fazit
Mit dbgen.exe lassen sich einfach beliebige Mengen an Daten direkt auf einem Zielsystem generieren und mit qgen.exe können automatisch Parameter für mehrere Abfragen erstellt werden. Damit bieten die Programme der TPC-H-Benchmark eine komfortable Möglichkeit, verschiedene Datenbanken auf der eigenen Hardware zu vergleichen und Performance-Tests mit großen Datenmengen durchzuführen. Ganz ohne Anpassungsbedarf funktioniert dies jedoch abhängig vom Zielsystem nicht. Allerdings kann man die Skripte ohne großen Aufwand entsprechend umkonfigurieren.
Weiterführende Links
- TPC-H: Schema and Indexes (Kritischer Blog zur Realitätsnähe von TPC-H)
- Quantifying TPCH Choke Points and Their Optimizations
Seminarempfehlungen
POSTGRESQL ADMINISTRATION DB-PG-01
Zum SeminarDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Zum SeminarConsultant bei ORDIX
Kommentare