
Wenn der Puffer voll ist – was ist eigentlich ein „Buffer Overflow“?
Eine der vielen Facetten der IT-Security ist die Softwaresicherheit. Einen Teilaspekt der Softwaresicherheit wiederum stellen die sogenannten "Buffer Overflows" - zu Deutsch "Pufferüberläufe" dar. In diesem Blogbeitrag werden die technischen Hintergründe von Pufferüberläufen erklärt und grob skizziert, welche Gefahren durch diese entstehen und welche Schutzmaßnahmen getroffen werden sollten, um sich bestmöglich vor selbigen zu schützen.
Ordnung ist das halbe Leben
Um zu verstehen, was ein Buffer Overflow ist und wieso daraus Sicherheitslücken entstehen, müssen wir erst einmal verstehen, wie eine CPU arbeitet und wie sie sich ihren Speicher einteilt. Um den Rahmen hier nicht zu sprengen, beschränken wir uns darauf, dass eine CPU einen servierfertigen und für sie verständlichen (Assembler)-Code bekommt und diesen dann Schritt für Schritt ausführt.
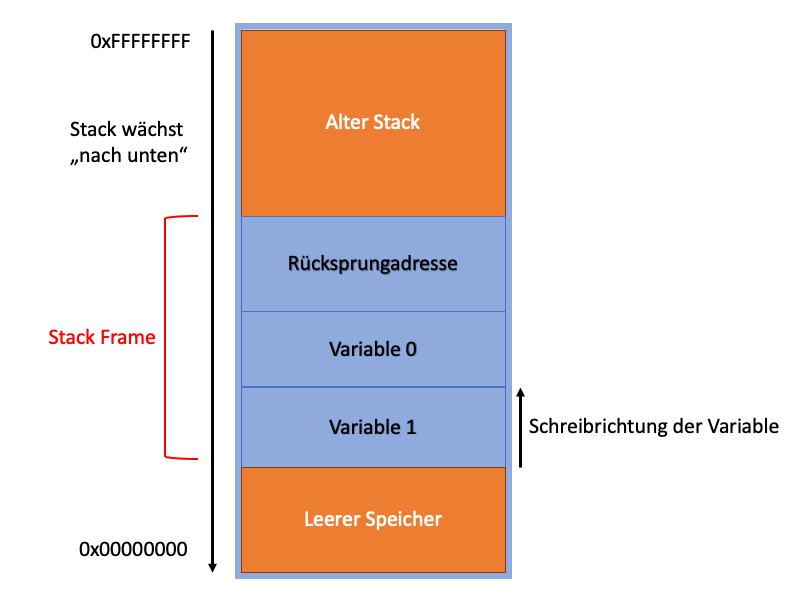
Während der Ausführung des Codes werden im Stack (einem bestimmen Bereichs im RAM) beispielsweise lokale Variablen abgelegt und verwaltet.
Der Stack hat die Besonderheit, dass er im Speicher „nach unten" wächst, also jeder neue Stack-Frame unterhalb des bestehenden (alten) aufgebaut wird. Da Variablen aber im Speicher „nach oben" wachsen – also von niedrigen zu hohen Adressen - muss darauf geachtet werden, dass für die lokalen Variablen beim Aufbau des Stacks ausreichend Platz reserviert wird.
Für jeden Funktionsaufruf legt die CPU einen neuen Stack-Frame an. In diesem werden dann die lokalen Variablen der Funktion und die Rücksprungadresse abgelegt. Die Rücksprungadresse ist die Adresse, an der das Programm weiter fortgeführt werden soll, wenn die Funktion fertig ausgeführt wurde (Sprich: die Adresse des nächsten Befehls im Aufrufenden Code). Ein (sehr vereinfachtes) Abbild eines Stack-Frames im RAM ist im folgenden Schaubild abgebildet.
Von Puffern und Adresse
Um zu verstehen, wie ein Buffer Overflow funktioniert, müssen wir uns einen Spezialfall anschauen: Arrays. Arrays speichern eine Menge von Variablen gleichen Datentyps, von ihrer Natur her ist die Anzahl der gespeicherten Variablen aber begrenzt. Technisch gesehen wird zum Zeitpunkt des Kompilierens folglich auch nur so viel Speicherplatz im Bereich der „lokalen Variablen" für das Array reserviert, wie dieses benötigt.
Im folgenden Source Code ist das Array 5 Zeichen lang, durch einen Fehler ist der Code allerdings anfällig für einen Buffer Overflow:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void overflow(char input[]) {
char zeichen[5];
strcpy(zeichen, input);
printf(zeichen);
}
int main(int argc, char *argv[]) {
overflow(argv[1]);
return 0;
}
Die fehlerhafte Funktion hier ist die „strcpy"-Funktion, da diese keine Längenprüfung des Ziel-Arrays vor dem Kopieren durchführt. Folglich kann nicht sichergestellt werden, dass das Quell-Array auch wirklich in das Ziel-Array passt.
Technisch gesehen passiert nun folgendes:
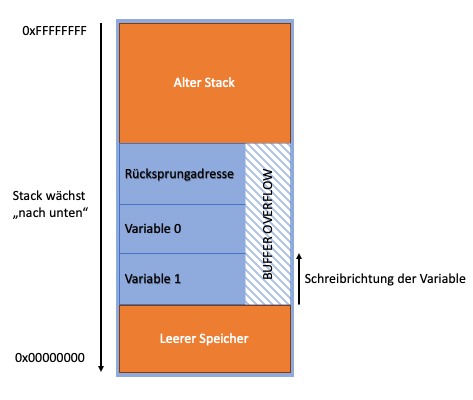
Gibt ein:e Benutzer:in einen String ein, der länger ist als 5 Zeichen, kopiert die Funktion alle Zeichen in das Ziel-Array, beginnend bei Position 0. Nach 5 Zeichen ist das Array „voll" – alle weiteren Zeichen landen im Speicher an den Positionen über dem Bereich, der für das Array reserviert ist - an denen sie aber eigentlich nicht stehen dürfen. Das führt unter anderem dazu, dass andere Variablen überschrieben werden und nun falsche Werte beinhalten. Allein dieser Sachverhalt kann einem Angreifer schon nützen, um den Programmablauf zu manipulieren.
Wenn dieser Fehler innerhalb einer aufgerufenen Funktion geschieht und der Inhalt großgenug ist, um den Speicher bis zur Rücksprungadresse zu überschreiben, kann der Fehler eine ernsthafte Sicherheitslücke hervorrufen. Im untenstehenden Bild ist die Auswirkung des Bufferoverflows grafisch dargestellt.
Tu, was ich dir sage!
Doch mal ganz langsam – was passiert denn wenn der Inhalt des Puffers die Rücksprungadresse überschreibt? Die CPU versucht die Prozessausführung an der (überschriebenen) Rücksprungadresse fortzusetzen, doch dass wir aus Versehen etwas Ausführbares treffen ist ziemlich unwahrscheinlich und die CPU würde versuchen, den Inhalt einer Speicheradresse auszuführen, der keinen realen Befehl enthält. Folglich quittiert das Programm mit dem Fehler „Segmentation Fault" den Dienst. Das alleine kann schon einen validen und belastbaren Angriff darstellen, doch es geht noch besser.
Denn dass wir aus Versehen etwas Ausführbares treffen, ist zwar unwahrscheinlich, aber wir können durch eine geschickte Eingabe die Adresse so manipulieren, dass genau dieses passiert. Der Angreifer kann zum Einen versuchen, bereits im Speicher liegende Code-Fragmente zu missbrauchen, um das Programm zu manipulieren, oder er kann seinen eigenen Code in Form von so genanntem Shellcode einbringen. In beiden Fällen dient das fehlerhafte Programm als Mittel zum Zweck, um es dem Angreifer zu ermöglichen, den Rechner, der dieses Programm ausführt, zu nahezu jeder Schandtat zu überreden.
Zu Risiken und Gegenmaßnahmen fragen Sie Ihren Sicherheitsexperten
Dass ein Angreifer auf einem PC oder in einem lokalen Netzwerk großen Schaden verursachen kann, wenn der angegriffene Computer Code ausführt, welchen der Angreifer kontrollieren kann, sollte hier niemanden überraschen.
Doch was kann man nun dagegen tun? Wenn man lediglich Nutzer der Software ist, helfen die altbekannten Hausmittel schon ganz hervorragend: Regelmäßige Softwareupdates, zeitnahes Einspielen von Security-Patches und Limitierung der Rechte auf das nötige Minimum. Sollten Sie die:der Entwickler:in sein, können Sie durch ein Source-Code-Review, Fuzzing-Analysen und statische/dynamische Code-Analysen möglichst umfangreich sicherstellen, dass keine Funktionen verwendet werden, die schon als „unsicher" bekannt sind und Sie auch in Ihrem eigenen Code keine Überprüfungen von Puffergrößen vergessen haben.
Zusammenfassung
Sicherheitsaspekte von ausgeführten Programmen und compilierter Software sind teilweise sehr technisch und sehr hardwarenah, das schreckt auf den ersten Blick sicherlich viele Einsteiger:innen ab, aber der Blick lohnt sich! Denn auch die Hacker:innen lassen sich von reiner Komplexität nicht abhalten. Und auch wenn die Suche nach Schwachstellen hier sehr mühselig ist, lohnen sich bereits einfache Maßnahmen wie automatisierte Scans und Source-Code-Reviews schon, um die Sicherheit der erstellten Software maßgeblich zu steigern. Aus Kundenperspektive sind Softwareupdates und Security Patches immer noch die zuverlässigste Methode, um Schwachstellen aus dem Weg zu gehen.
Wenn Sie noch weitere Fragen haben oder sich über weitere Angriffsmethoden informieren möchten, dann sprechen Sie uns an oder schauen Sie auf unserer Webseite vorbei.
Zu unseren Seminaren
Senior Consultant bei ORDIX
Kommentare