
Oracle - Analytische Funktionen
Analytische Funktionen sind mit der Oracle Version 8i eingeführt und ständig erweitert worden. Die Fähigkeit, komplexe Fragestellungen bei Datenauswertungen im reinen überschaubaren SQL-Code abzuwickeln, hat analytische Funktionen sehr beliebt gemacht. Die Alternative wäre ein komplexer SQL-Code oder der Umweg über den prozeduralen Code. In diesem Artikel werden die Besonderheiten und Grenzen der analytischen Funktionen in Oracle am Beispiel einiger ausgewählter Funktionen vorgestellt. Abgerundet wird der Artikel mit dem sinnvollen Einsatz und einigen Anwendungsfällen aus der Praxis.
Was sind Analytische Funktionen?
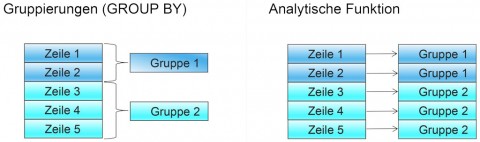
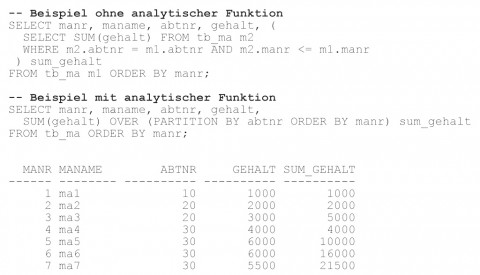
Als analytische Funktionen in einer Oracle Datenbank werden Funktionen bezeichnet, die auf einer Menge der Ergebnisdatenzeilen ausgeführt werden. Anders als bei Gruppenfunktionen mit einer GROUP BY-Klausel, bei denen nur die Aggregatsdatenzeilen ausgegeben werden, werden bei analytischen Funktionen immer alle Datenzeilen ausgegeben inklusive der Ergebnisse der Funktionen, die auf einer Menge der Ergebnisdatenzeilen ausgeführt wurden (siehe Abbildung 1). Die Menge der Datenzeilen, auf denen eine analytische Funktion aufgerufen wird, kann pro Datensatz unterschiedlich sein.
Ein zweites wesentliches Merkmal analytischer Funktionen ist die Fähigkeit, auf benachbarte Datenzeilenwerte zuzugreifen. Ein Zugriff auf benachbarte Datenzeilenwerte ohne analytische Funktionen ist in der Regel nur mit einem zusätzlichen Tabellenzugriff verbunden, was zum einem einen komplizierteren Code und zum anderen einen erhöhten Ressourcenverbrauch sowie eine höhere Laufzeit zur Folge hat.
Anwendungsgebiete und Vorteile
Analytische Funktionen werden vorwiegend im Data-Warehouse-Umfeld eingesetzt. Die Hauptanwendungsfälle sind unter anderem Aufsummierung von Werten in einem Datenzeilenbereich, gleitende Durchschnitte, zeilenübergreifende Datenwertvergleiche oder Rankings.
Der wesentliche Vorteil analytischer Funktionen ist die Vermeidung der mehrfachen Zugriffe auf dieselbe Tabelle innerhalb einer SQL-Anweisung. Die meisten SQL-Anweisungen mit Unterabfragen, Inline-Views oder Self-Joins lassen sich mit Hilfe analytischer Funktionen so umschreiben, dass lediglich ein Tabellenzugriff notwendig ist. Daraus resultieren in der Regel ein reduzierter Ressourcenverbrauch und eine schnellere Laufzeit. Eine Implementierung ohne analytische Funktionen führt darüber hinaus zu einem sehr umständlichen, schlecht wartbaren und teilweise auch prozeduralen Code.
Syntax analytischer Funktionen
Die Abbildung 2 zeigt die Syntax der analytischen Funktionen. Neben einer Gruppenfunktion, die als analytische Funktion ausgeführt werden kann, können optional eine PARTITION BY- und eine ORDER BY-Klausel angegeben werden.
Mit Hilfe der PARTITION BY-Klausel kann eine Gruppierung der Ergebnismenge durchgeführt werden, ähnlich einer GROUP BY-Klausel bei einer Gruppierung. Alle Zeilen einer Ergebnismenge, die dem Gruppierungskriterium entsprechen, werden zusammengefasst. Ohne Angabe der PARTITION BY- Klausel werden alle Datenzeilen als eine Partition betrachtet.
Die ORDER BY-Klausel gibt dagegen eine Sortierung innerhalb einer Partition vor. Das Besondere an der ORDER BY-Klausel ist, dass hier eine Teilmengenextraktion aktiviert wird, bei der nicht alle Zeilen zu einer Partition zusammengefasst werden, sondern nur ein bestimmtes "Fenster". Das standardmäßige Fenster besteht aus Zeilen der jeweiligen Partition bis zur aktuellen Zeile.

Teilmengenextraktion mit WINDOWING-Klausel
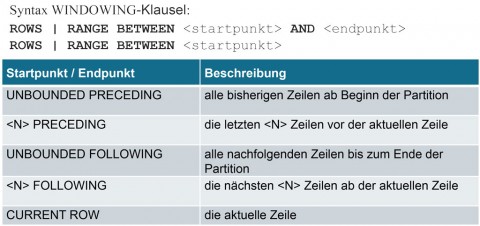
Ein "Fenster" definiert den Bereich von Datensätzen, auf dem eine analytische Funktion ausgeführt werden soll (Teilmengenextraktion). Voraussetzung zur Verwendung der WINDOWING- Klausel ist die
ORDER BY- Klausel (sortierte Ergebnismenge), d. h. mit der ORDER BY-Klausel wird die WINDOWING-Klausel aktiviert.
In der WINDOWING-Klausel werden entweder Start- und Endpunkt oder nur der Startpunkt des Fensters angegeben. Wird lediglich der Startpunkt angegeben, so ist die aktuelle Zeile automatisch der Endpunkt. Mögliche Werte für Start- und Endpunkt und die genaue Syntax der WINDOWING-Klausel stellt die Abbildung 3 dar.
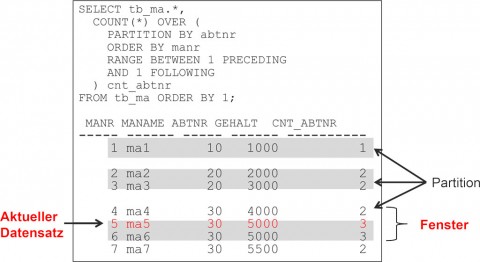
Die Einschränkung des Fensters ist zum einen auf Zeilenebene mit dem Schlüsselwort ROWS und zum anderen auf logischer Ebene mit RANGE möglich. Bei der Einschränkung auf Zeilenebene (ROWS) kann über ein Offset die Anzahl der Zeilen angegeben werden, auf die sich ein Fenster beziehen soll (siehe Abbildung 4).
Über RANGE kann dagegen ein Fenster auf der logischen Werteebene definiert werden. Die Spalten, auf die sich der logische Wertebereich beziehen soll, werden in der ORDER BY-Klausel angegeben und können vom Datentyp NUMBER, DATE oder TIMESTAMP sein.
Ranking
Ranking ist in der Praxis einer der Hauptanwendungsfälle der analytischen Funktionen. Mit einem Ranking lässt sich eine Datenzeilen-Rangfolge ermitteln oder Top-n-Auswertungen durchführen. Dazu stellt Oracle folgende Funktionen zur Verfügung:
- DENSE_RANK
- RANK
- ROW_NUMBER
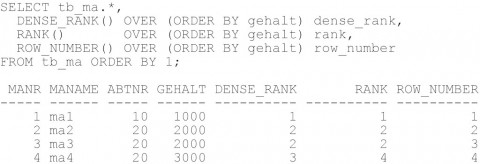
Die Funktionen DENSE_RANK und RANK liefern bei gleichen Werten den gleichen Rang zurück. Die Funktion ROW_NUMBER setzt bei gleichen Werten die Zählung dagegen fort. Die RANK Funktion hinterlässt darüber hinaus im Gegensatz zu DENSE_RANK nach gleichen Werten eine Lücke in der Rangfolge (siehe Abbildung 5).
Zugriff auf benachbarte Datenzeilenwerte
Ein weiteres Anwendungsbeispiel für analytische Funktionen ist der Zugriff auf benachbarte Datenzeilenwerte. Dieser lässt sich mit folgenden Funktionen realisieren:
- LAG
- LEAD
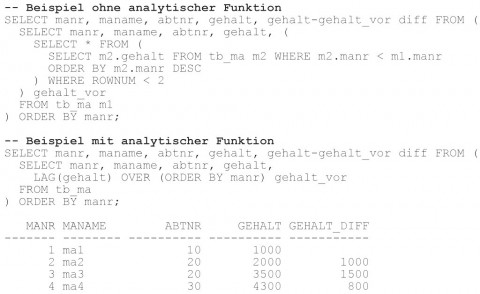
Soll auf die vorhergehenden Datenzeilen zugegriffen werden, so kann die LAG-Funktion verwendet werden. Die LEAD-Funktion kann dagegen auf die darauffolgenden Datenzeilen zugreifen. In der Praxis werden diese beiden Funktionen häufig für zeilenübergreifende Datenfeldvergleiche wie Differenzbildung oder prozentuale Veränderungen eingesetzt. Wie aus der Abbildung 6 ersichtlich, greift die Variante ohne analytische Funktion zweimal auf die Tabelle TB_MA zu und benötigt aufgrund der mehr gelesenen Datenblöcke auch eine längere Laufzeit.
Werteverteilung der Datenzeilenwerte
Auch für die Ermittlung der Werteverteilung der Datenzeilenwerte können analytische Funktionen verwendet werden. Dazu stellt Oracle folgende Funktionen zur Verfügung:
- CUME_DIST
- PERCENT_RANK
- NTILE
- RATIO_TO_REPORT
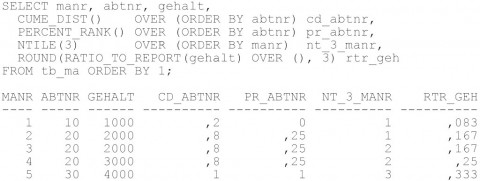
Die beiden Funktionen CUME_DIST und PERCENT_RANK liefern den Anteil der Zeilen an der Gesamtanzahl aller Zeilen, die kleiner oder gleich dem Datenzeilenwert der aktuellen Zeile sind. Der Rückgabewert der Funktionen liegt zwischen 0 und 1, wobei bei der Funktion CUME_DIST die 0 exklusive und bei der Funktion PERCENT_RANK die 0 inklusive ist. Bei der Funktion CUME_DIST werden außerdem gleiche Werte derselben höchsten kumulativen Werteverteilung zugeordnet und bei der Funktion PERCENT_RANK der niedrigsten kumulativen Werteverteilung.
Sollen Datenzeilen in n gleich große Mengen aufgeteilt werden, um z.B. einen sehr großen Datenbestand in mehrere Tabellen aufzuteilen, so kann die NTILE-Funktion verwendet werden. Die Anzahl der Mengen kann mit einem Übergabeparameter bestimmt werden. Dabei muss allerdings berücksichtigt werden, dass gleiche Werte unterschiedlichen Mengen zugeordnet werden können, da die Funktion NTILE nicht sicherstellt, dass gleiche Werte immer nur einer Menge zugeordnet werden.
Mit der RATIO_TO_REPORT-Funktion kann schließlich – anders als bei den Funktionen CUME_DIST und PERCENT_RANK, wo die Werteverteilung anhand der Anzahl der Zeilen durchgeführt wird – eine Werteverteilung bezogen auf die Werte ermittelt werden. Dabei liefert die Funktion RATIO_TO_REPORT den Anteil eines Wertes an der Gesamtsumme aller Werte einer Spalte zurück (siehe Abbildung 7).
Anwendungsbeispiele aus der Praxis
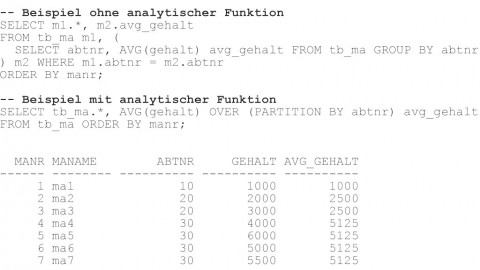
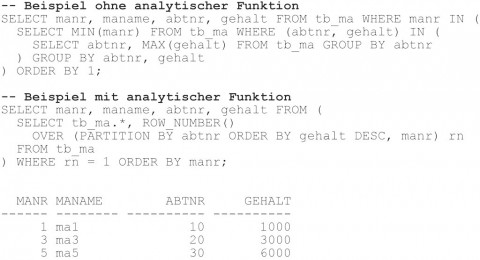
Die typischen Kandidaten für den Einsatz von analytischen Funktionen sind SQL-Anweisungen mit mehrfachen Zugriffen auf dieselben Tabellen, wie es häufig bei Unterabfragen, Inline-Views oder Self-Joins der Fall ist. Die Abbildungen 8, 9 und 10 stellen weitere typische Anwendungsfälle für den Einsatz von analytischen Funktionen dar. Alle diese Beispiele haben gemeinsam, dass bei der Variante mit analytischer Funktion im Gegensatz zu der Variante ohne analytischer Funktion lediglich nur ein Tabellenzugriff notwendig ist.
Besonderheiten und Grenzen analytischer Funktionen
Analytische Funktionen sind in der WHERE-Klausel nicht zulässig und können nur in der SELECT-Liste und ORDER BY-Klausel verwendet werden. Der Grund der Einschränkung liegt in der Reihenfolge der SQL-Verarbeitung, da die analytischen Funktionen erst vor der ORDER BY-Klausel und nach der Join-Verknüpfung, WHERE-, GROUP BY- und HAVING-Klauseln ausgewertet werden. Soll das Ergebnis einer analytischen Funktion in einer WHERE-Klausel eingeschränkt werden, so kann dies z.B. mit Hilfe einer Inline-View vorgenommen werden.
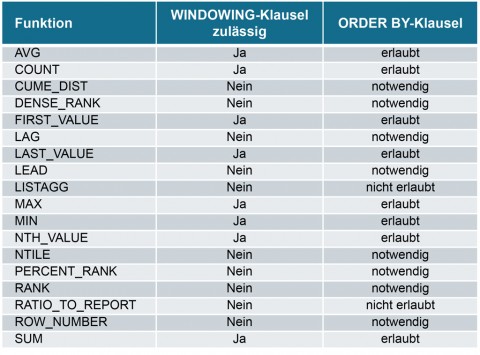
Außerdem ist die ORDER BY- und WINDOWING-Klausel nicht bei allen analytischen Funktionen erlaubt, bei einigen Funktionen aber sogar zwingend erforderlich (siehe Abbildung 11).
Fazit
Zusammenfassend kann gesagt werden, dass die analytischen Funktionen die Komplexität der SQL-Anweisungen deutlich vereinfachen und gleichzeitig auch häufig die Performance verbessern. Aus diesem Grund werden diese Funktionen in der Praxis vor allem im Data-Warehouse-Umfeld eingesetzt. Die vielen Vorteile können auch den Einsatz z.B. in OLTP-Systemen interessanter gestalten.
Seminarempfehlung
[1] Oracle SQL-Workshop für Experten (DB-ORA-01A)
https://seminare.ordix.de/seminare/oracle/entwicklung/oracle-sql-workshop-für-experten.html
Principal Consultant bei ORDIX
Kommentare