
Data Mining in der Praxis (Teil II): Klassifikation
Was ist Klassifikation?
Aufgrund der Ausprägung der Attribute eines Datensatzes kann dieser einer bestimmten Kategorie zugeordnet werden. So entscheidet der Inhalt, Betreff und Absender einer E-Mail darüber, ob diese Mail der Kategorie „Spam" oder „kein Spam" angehört. Ein zweites Beispiel sind die Warenkörbe eines Onlinekunden, aus denen sich Rückschlüsse über das Geschlecht, die Altersklasse und Preisaffinität ziehen lassen. Die gewonnenen Informationen können im Fall der E-Mail zur automatischen Verschiebung einer Spam-Mail in einen bestimmten Ordner, oder bei dem Onlinekunden zur gezielten Ansprache mit Werbung genutzt werden.
Wie funktioniert Klassifikation?
Aufgrund der vorhandenen, historischen Daten wird ein Modell erstellt. Dieses Modell wird bei einem neuen Datensatz genutzt, um eine Aussage über die wahrscheinlichste Kategorie zu treffen, der dieser Datensatz angehört. Bei dem Modell handelt es sich um eine mathematische Funktion, die aufgrund statistischer Zusammenhänge ermittelt wird. Die Daten sind Eingabewerte für die Funktion, die Kategorie ist das ermittelte Ergebnis.
Abgrenzung Klassifikation zu Clusteranalyse
Im Einführungsartikel der Reihe Data Mining wurde neben der Klassifikation auch die Clusteranalyse als eine mögliche Aufgabe des Data Mining erwähnt. Bei der Clusteranalyse werden aus Daten einer bestimmten Fragestellung im Vorfeld, nicht bekannte Kategorien ermittelt. Es werden ähnliche Datensätze gruppiert und diese Gruppen bilden die Kategorien. So kann zum Beispiel die geografische Position des Wohnortes eines Kunden genutzt werden, um eine Kategorisierung bezüglich des Wohnortes vorzunehmen. Je nach gewählter Granularität ergeben sich für die deutsche Bevölkerung Kategorien um die großen Städte und Ballungszentren herum. Die Grenzenzwischen zwei Kategorien sind nicht fest gezogen, sondern werden vom Algorithmus bei jedem zusätzlich untersuchten Datensatz neu gesetzt. Wertvoll kann eine solche Analyse zum Beispiel bei der Planung der Filialen eines Unternehmens sein. Wenn zum Beispiel fünf Filialen geplant sind, wird die Clusteranalyse mit dem Ziel von fünf Kategorien durchgeführt. Wenn die neuen Filialen im geografischen Zentrum dieser Kategorien liegen, ist der durchschnittliche Weg der Kunden zu einer Filiale minimiert.
Während bei der Clusteranalyse die Kategorien nicht bekannt sind, sondern gerade die Ermittlung dieser die Aufgabe der Analyse darstellt, sind bei der Klassifikation die Kategorien vorab bekannt. Neue Datensätze werden entsprechend ihrer „Ähnlichkeit" zu vorhandenen Datensätzen einer Kategorie zugeordnet.
Wegen dem engen inhaltlichen Zusammenhang erfolgt in der Praxis häufig auf noch nicht untersuchten Daten zuerst eine Clusteranalyse, um sinnvolle Kategorien zu ermitteln. In einem zweiten Schritt werden diese dann im Rahmen einer Klassifikation auf neue Daten angewendet.
Vorbereitung
Bevor ein Modell zur Klassifikation erstellt werden kann, muss sichergestellt werden, dass die zugrunde liegenden Daten „sauber" sind. Die Modellerstellung ist ein mathematisches Verfahren, das von sich aus nicht in der Lage ist, korrekte von nicht korrekten Daten zu unterscheiden.
In einem Beispiel verkauft ein Onlineshop Hörgeräte. Die aus fachlicher Sicht erwartete Kundschaft ist von eher gesetztem Alter. Bei der Registrierung im Onlineshop setzt die Software das Alter auf 0, wenn keine Angabe durch den Kunden gemacht worden ist. Bei der Kategorisierung wird nun das Alter, neben weiteren Attributen, zur Ermittlung des zu erwartenden Umsatzes je Kunde herangezogen. Als Ergebnis ermittelt das Modell, dass Kunden unter 20 Jahren einen hohen Umsatz erwarten lassen. Tatsächlich sind es aber nicht die 18 und 19 Jahre alten Kunden, die vermehrt Hörgeräte kaufen, sondern die vielen Kunden mit „0 Jahren", die die Daten verfälschen. Wenn das Modell nun auf einen neuen Kunden mit 18 Jahren angewendet wird, wird diesem eine hohe Umsatzkategorie prognostiziert und somit unnötige Werbegelder für eine persönliche Ansprache ausgegeben.
Einem Fachanwender, oder in diesem einfachen Fall jedem Menschen, wird auffallen, dass an dem Modell etwas nicht stimmt. Der Algorithmus selber kann dies nicht feststellen – er arbeitet immer mit den gegebenen Daten, mögen sie sinnvoll sein oder nicht.
Das Beispiel verdeutlicht, wie wichtig die Verwendung valider Daten für die Modellerstellung ist. Im obigen Beispiel hätte man sinnvoll Kunden mit Alter „0 Jahre" aus der Modellbildung herausgelassen. Ein Modell wird mit steigender Anzahl an Trainingsdaten immer besser, wenige falsche Daten kehren diesen Effekt aber schnell ins Gegenteil.
Trainingsdaten und Validierungsdaten
Zur Erstellung eines Modells werden Daten benötigt. Die Daten, die hierfür verwendet werden, bezeichnet man als Trainingsdaten. Um die Qualität eines Modells zu testen, wendet man es nach dem Training auf bekannte Daten an. Für jeden Datensatz aus diesen Validierungsdaten ist die korrekte Kategorie bekannt. Sie kann mit der durch das Modell ermittelten Kategorie verglichen werden. Der prozentuale Anteil korrekt klassifizierter Datensätze ist eine Kennzahl, die die Qualität eines Modells beschreibt.
Je größer die zur Verfügung stehende Menge an historischen Daten ist, desto besser wird ein Modell sich in der Klassifikation bewähren. Auf der anderen Seite benötigt man auch eine nennenswert große Menge an Testdaten, um die Qualität des Modells zu bestimmen. Wenn der Umfang der Validierungsdaten zu gering gewählt ist, können statistische Ausreißer das Ergebnis verfälschen. Als Daumenregel hat es sich bewährt, die zur Verfügung ste-henden Daten zufällig verteilt auf 80% als Trainingsdaten und 20% als Validierungsdaten zu verwenden.
Featureselection und Overfitting
In einem Datensatz sind in der Regel viele Attribute vorhanden. Nicht alle sind für die Ermittlung der ange-strebten Klassifikation relevant. So mag in einem Kundendatensatz der Wohnort, das Alter und Geschlecht sowie der ausgeübte Beruf relevant für die Klassifikation bezüglich des zu erwartenden Umsatzes mit Handys sein. Die Attribute „Augenfarbe" oder „Schuhgröße" sind es wahrscheinlich nicht. Bei diesem einfachen Beispiel ist sofort ersichtlich, dass die beiden genannten Attribute nicht zur Qualität des gesuchten Modells beitragen. In der Praxis existieren aber unter Umständen Hunderte Attribute. Selbst eine Fachabteilung kann oftmals keine fundierte Aussage treffen, welche Attribute für ein Modell relevant sind und welche nicht. Ein einfacher Ansatz wäre es, alle zur Verfügung stehenden Attribute in die Modellerstellung mit einzubeziehen. Es gibt zwei Argumente, die gegen einen solchen Ansatz sprechen:
- Viele Attribute machen ein Modell komplex. Ist zum Beispiel das Alter aus dem Beispiel der Umsätze mit Hörgeräten ein integraler Bestandteil eines Modells, dann können keine guten Vorhersagen für Datensätze getroffen werden, bei denen die Information Alter nicht vorliegt. Je komplexer ein Modell wird, desto größer ist die Gefahr, dass bei der anschließenden Klassifikation neue Datensätze einzelne Attribute nicht enthalten und somit nicht zuverlässig klassifiziert werden können.
- Ein Modell kann einen vermeintlichen Zusammenhang des Umsatzes mit der Augenfarbe „erkennen". Tatsächlich ist dieser ermittelte Zusammenhang aber rein zufällig. Insbesondere wenn die Menge der Validierungs-daten zu gering gewählt wurde, neigen Modelle zu solchen nicht korrekten Klassifikationen. Man spricht davon, dass ein Modell „overfitted" wurde. Es ist also zu sehr an Trainingsdaten angepasst und verallgemeinert zu wenig. Es ist zu stark abhängig von einzelnen, mitunter fachlich irrelevanten Attributen.
Ein gutes Modell verallgemeinert gut und verwendet dazu eine möglichst kleine Anzahl von Attributen. Die Auswahl der tatsächlich eingesetzten Attribute wird mit Featureselection bezeichnet und ist ein wesentlicher Aspekt bei der Modellbildung.
Beispiel Klassifikation
Die folgenden Beispiele sind in der Sprache Python erstellt. Python und R sind die beiden wichtigsten Sprachen im Umfeld von Data Mining. Es handelt sich jeweils um Skriptsprachen, die sich durch eine einfache Syntax und eine Vielzahl existierender Hilfsbibliotheken auszeichnen. Zum Einsatz von Python ist es empfehlenswert, anaconda [1] zur Verwaltung der Bibliotheken und Jupyter Nodebook [2] als interaktiven Editor zu installieren.
Ähnlich dem „Hello World" für einen Programmierer ist der Titanic-Datensatz im Bereich Data Mining ein häufig genutzter Einstieg für die Beschäftigung mit dem Thema Klassifikation. Zu jedem Passagier des untergegangenen Schiffes ist bekannt, ob er in die Kategorie survived oder not survived gehört.
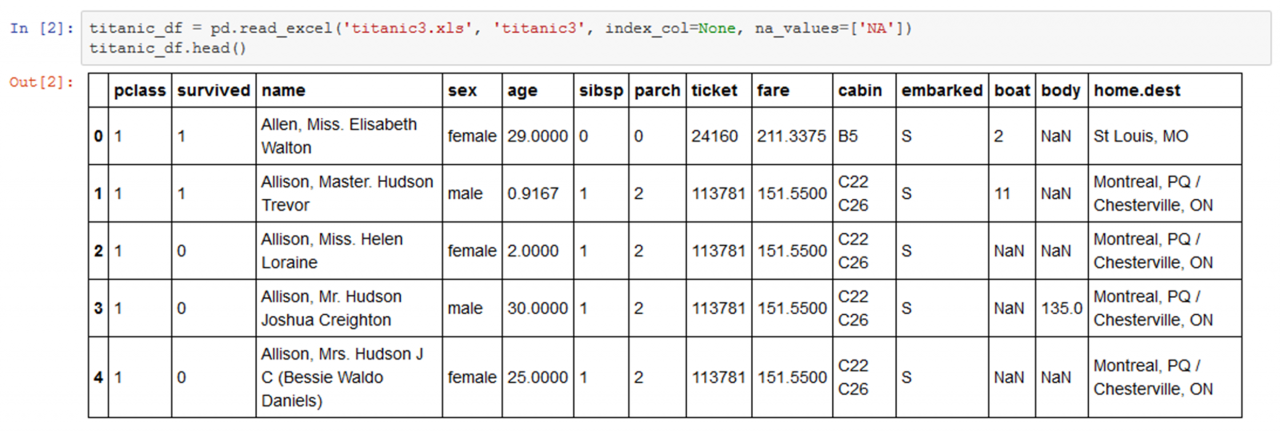
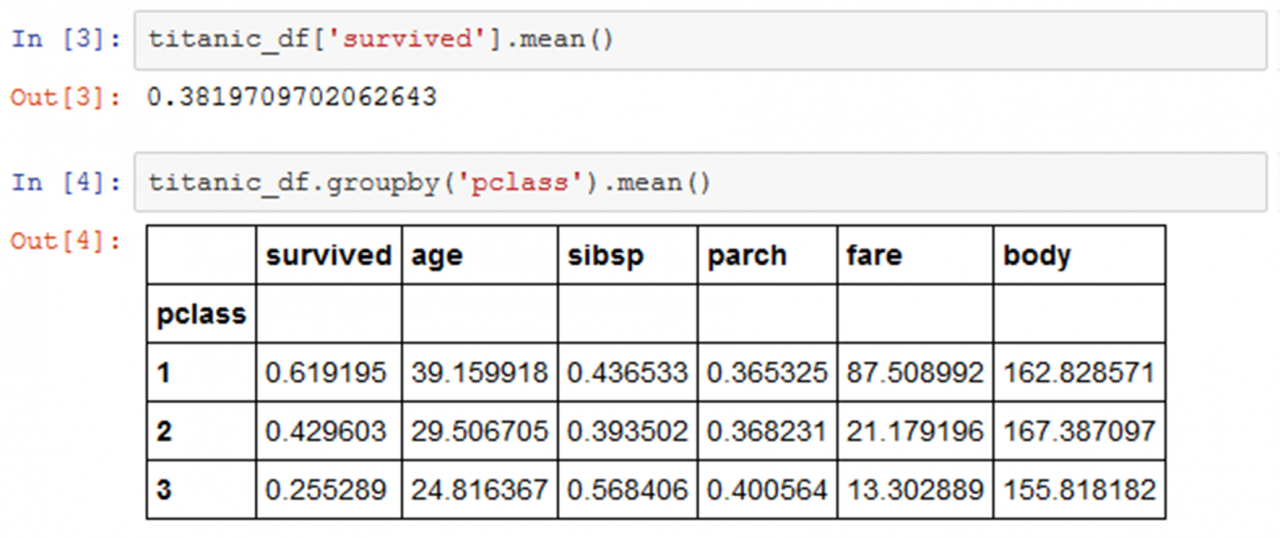
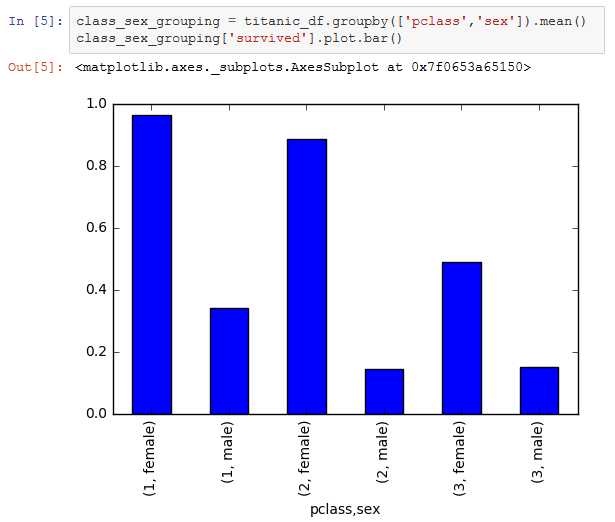
Nachdem die benötigten Bibliotheken importiert worden sind (siehe Abbildung 1), werden die eigentlichen Daten [3] geladen (siehe Abbildung 2). Der Befehl head() gibt die ersten fünf Datensätze aus. Neben dem Alter, Geschlecht und Namen sind auch Informationen zur Passagierklasse, dem Ticketpreis und dem Abfahrtsort vorhanden. Und natürlich mit survived, die Kategorie, wegen der die Klassifikation durchgeführt werden soll. Vor der Modellbildung ist es sinnvoll, sich einen Überblick über die Daten zu verschaffen. In Abbildung 3 wird die durchschnittliche Überlebensrate mithilfe des Befehls mean() errechnet. Angewendet wird der Befehl auf dem Datenobjekt titanic_df auf dem Attribut survived. Sie ist mit 38,2% leider recht gering. Die Vermutung, dass die Chance, den Untergang zu überleben, für Passagiere der ersten Klasse höher lag als für das Fußvolk in der dritten Klasse, wird mit einem groupby auf dem Attribut survived bestätigt. Wer sich also die durchschnittlichen £ 87,51 für ein Ticket der ersten Klasse nicht leisten konnte, hatte in der dritten Klasse nur noch eine Überlebenschance von 25,6%. In Abbildung 4 werden die nach Passagier-klasse und Geschlecht gruppierten Daten in einer neuen Variablen class_sex_grouping gespeichert und dann mithilfe von plot.bar() als Balkengrafik ausgegeben. Man erkennt, dass Frauen über alle Klassen hinweg eine deutlich höhere Überlebenschance hatten als Männer. Da sich dies adäquat auch für Kinder sagen lässt, galt damals in jedem Fall: „Frauen und Kinder zuerst".
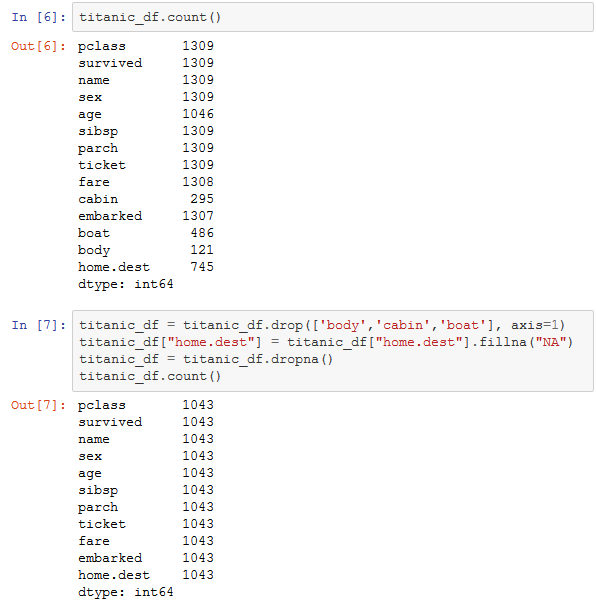
Bereits dieser erste Überblick über die Daten bescheinigt Frauen aus der ersten Klasse die höchste Überlebenschance. Wenn man die Daten genauer untersucht, findet man schnell weitere derartige Abhängigkeiten. Ein Klassifikationsalgorithmus dient dazu, in den Daten befindliche Zusammenhänge automatisiert zu entdecken. Bevor ein solcher Algorithmus allerdings eingesetzt werden kann, müssen die Daten aufbereitet werden. Die Abbildung 5 zeigt, dass einige Spalten nicht vollständig gefüllt sind. Die Attribute body, cabin und boat enthalten wenig Information, deshalb werden sie mit drop() aus den Daten entfernt. Der Zielhafen ist zumindest bei etwa der Hälfte der Personen ausgefüllt. Die restlichen werden mit NA, also „not available" gefüllt. Bei der Modellerstellung ist NA für den Algorithmus ein Hafen, wie jeder andere auch. 1043 Datensätze von insgesamt 1309 bleiben nach dieser Phase der Datenbereinigung noch übrig.
Es folgt ein technischer Schritt (Abbildung 6), in dem die Daten in ein Format transformiert werden, das der Algorithmus verarbeiten kann. Insbesondere werden die beiden für das Geschlecht auftretenden Strings Male und Female durch 0 und 1 ersetzt. Außerdem werden die Attribute name, ticket und home.dest aus dem Datensatz entfernt, da sie nichtkategoriale Werte beinhalten. Hierunter versteht man Daten mit sehr vielen unterschied-lichen Ausprägungen, bei denen nur selten identische Werte austreten. Solche Attribute eignen sich nicht gut für eine Klassifikation und tragen somit wenig zur Qualität des Modells bei.
Die Daten werden entsprechend Abbildung 7 in zwei Teile gesplittet. Die Variable X enthält alle Daten, bis auf die Information, ob ein Passagier überlebt hat. Hierzu wird mittels drop(['survived'], axis=1) das entsprechende Attribut aus den Daten entfernt. Die Variable y enthält ausschließlich die aus X entfernten Informationen. Mit cross_validation.train_test_split(X,y,test_size=0.2) werden die Daten zu 80% in Trainingsdaten und zu 20% in Validierungsdaten aufgeteilt. Nach doch recht umfangreichen Vorbereitungen erfolgt nun der eigentliche Analyseschritt. In Abbildung 8 wird ein Modell mithilfe des Entscheidungsbaum-Algorithmus erstellt. Es handelt sich um einen sehr leistungsfähigen Klassifikationsalgorithmus aus einer ganzen Reihe verschiedener, in der Literatur beschriebener Ansätze. Detaillierte Informationen zur zugrunde liegenden Mathematik findet sich zum Beispiel im hervorragenden Buch „An Introduction to Statistical Learning" von James/Witten/Hastie/Tibshirani [4]. In diesem Buch werden auch alternative Algorithmen vorgestellt. Die Dokumentation zur, in diesem Beispiel verwendeten, Bibliothek scikit-learn [5] enthält ebenfalls Informationen zu weiteren Algorithmen und insbesondere eine Dokumentation der Syntax, mit der sie eingesetzt werden können.
Im vorliegenden Beispiel erreicht der Algorithmus eine Trefferquote von 78,9%. Für einen ersten Versuch ist dieser Wert schon recht gut. Er lässt sich durch Einsatz von komplexeren Algorithmen und insbesondere durch die gezielte Einbeziehung weiterer Attribute noch deutlich verbessern. Der Befehl clf_dt.predict(data) bietet die Möglichkeit, für einen einzelnen Datensatz data eine Vorhersage für die wahrscheinlichste Kategorie zu erhalten.




Fazit
Links
[1] Anaconda - Verwaltung von Entwicklungsumgebungen für Python https://www.continuum.io/downloads
[2] Jupyter Notebook - interaktive Entwicklungsumgebung für Python http://jupyter.org/
[3] Vanderbilt University USA - Titanic Datensatz http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls
[4] Stanford University USA - The Elements of Statistical Learning von Trevor Hastie, Robert Tibshirani, Jerome Friedman http://www-stat.stanford.edu/~tibs/ElemStatLearn/download.html
[5] Python Bibliothek zum Thema Machine Learning http://scikit-learn.org/stable/
[6] Socialcops - englischsprachiger Blog zu Themen Data Intelligence https://blog.socialcops.com/engineering/machine-learning-python/
Bildnachweis
© wikimedia.org | Carsten Jünger | Titanic at Minimundus
© freepik.com | creativart | Shadow drawing cool cheering...
© freepik.com | d3images | Character playing with a float
Kommentare