
Data Mining in der Praxis (Teil III) Lineare Regression
Was ist lineare Regression?
In untersuchten Daten existiert eine Menge an unabhängigen Variablen, die den Wert einer abhängigen Variablen beeinflussen. Zum Beispiel beeinflussen die unabhängigen Variablen Einnahmen und Ausgaben die von ihnen abhängige Variable Gewinn nach dem Prinzip Gewinn = Einnahmen – Ausgaben. Der Zusammenhang im Beispiel ist trivial. Bei der Analyse von nicht trivialen Zusammenhängen mit potenziell hunderten von unabhängigen Variablen kann die lineare Regression behilflich sein. Von Interesse ist hierbei die konkrete Prognose einer abhängigen Zielvariable in Abhängigkeit der unabhängigen Quellvariablen. Weiterhin erlaubt die Regression die Analyse des Zusammenspiels der Quellvariablen. Nicht alle sind gleich gewichtet und die lineare Regression kann helfen, diejenige Einflussgrößen zu identifizieren, welche die größte Auswirkung auf das untersuchte Ziel haben.
Wie funktioniert lineare Regression?
Im einfachsten Fall wird der Zusammenhang zwischen einer einzelnen unabhängigen Variablen x und einer abhängigen Variablen y untersucht. In diesem Fall ergibt sich der Wert der Zielvariablen aus folgender mathematischen Funktion:
y = β0+β1* x + error
β0 ist hierbei ein von x unabhängiger Wert. β1 bestimmt die Stärke des Einflusses von x auf die Zielvariable y. Die lineare Regression ist ein statistisches Verfahren und wird somit nie 100 % korrekte Vorhersagen liefern. Der Wert error trägt dieser Tatsache Rechnung und repräsentiert einen statistischen Fehler. Komplexere Fälle von linearer Regression betrachten nicht nur eine unabhängige Variabel (einfache lineare Regression) sondern sehr viele unabhängige Variablen (multiple lineare Regression):
y = β0 + β1 * x1 + β2 * x2 + ... + βn * xn+ error
Außerdem kann eine unabhängige Variable nicht nur einfach, sondern zum Beispiel auch quadratisch oder in einer höheren Potenz in die Berechnungsformel der Zielvariablen y eingehen:
y = β0 + β1 * x + β2 *x2 + ... +βn * xn + error
Erstellung eines Modells
ŷ = β0 + β1 * x
erzeugt. Abbildung 1 zeigt die sich ergebende Gerade mit dem Achsenabschnitt β0 und der Steigung β1. β0 und β1 sind Vorhersagewerte die, basierend auf den untersuchten Quelldaten, ermittelt wurden. Da Quelldaten immer einen endlichen Umfang haben, können β0, β1 und daraus resultierend auch ŷ nie perfekt sein. Die Kunst besteht nun darin, die Parameter β0 und β1 so zu bestimmen, dass der über alle zur Verfügung stehenden Quelldaten hinweg summierte Fehler möglichst klein wird. In Abbildung 2 sind die Einzelfehler als rote Linien dargestellt. Es sind die jeweiligen Abweichungen des von der Regression prognostizierten Wertes auf der grünen Gerade vom tatsächlichen Wert eines blauen Punktes. Eines der am häufigsten eingesetzten Verfahren zur Minimierung des Gesamtfehlers ist die Minimierung der Summe der quadratischen Fehler. Durch diesen kleinen Trick wird erreicht, dass größere Abstände vom Zielwert, also größere Fehler, stärker in den Gesamtfehler eingehen als kleine Abstände. Auf die mathematischen Einzelheiten dieser nicht trivialen Aufgabe soll in diesem Artikel nicht näher eingegangen werden. In den Quellen ist ein sehr empfehlenswertes Einstiegswerk in die Materie angeführt [1].
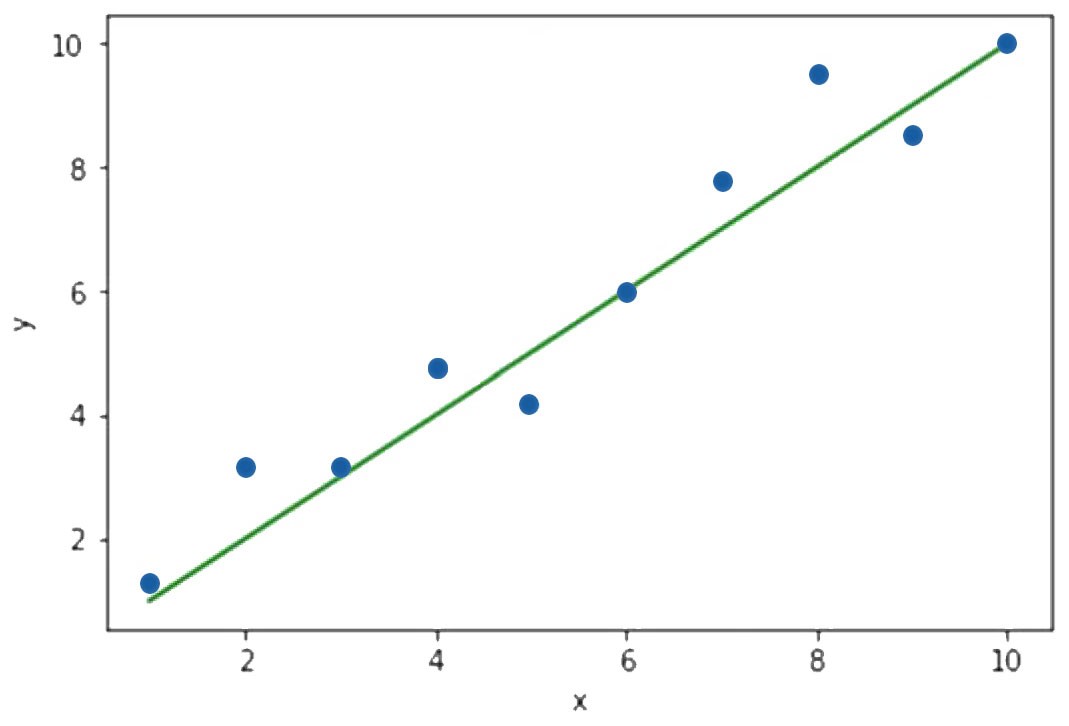
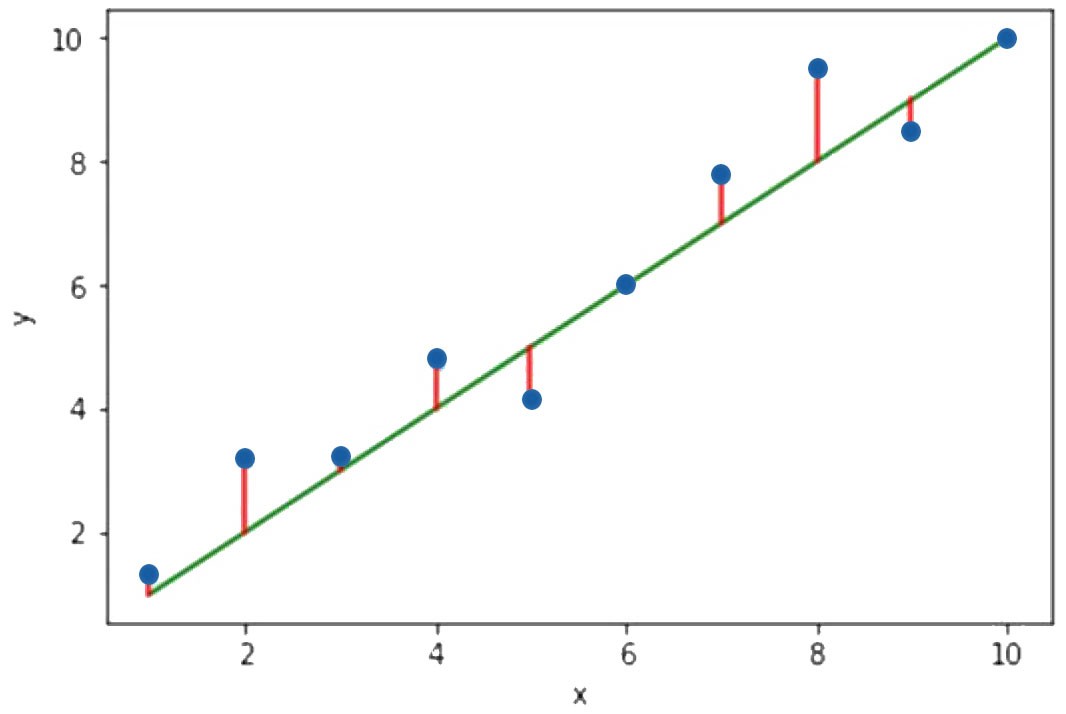
Daten für ein einfaches Beispiel zur einfachen linearen Regression
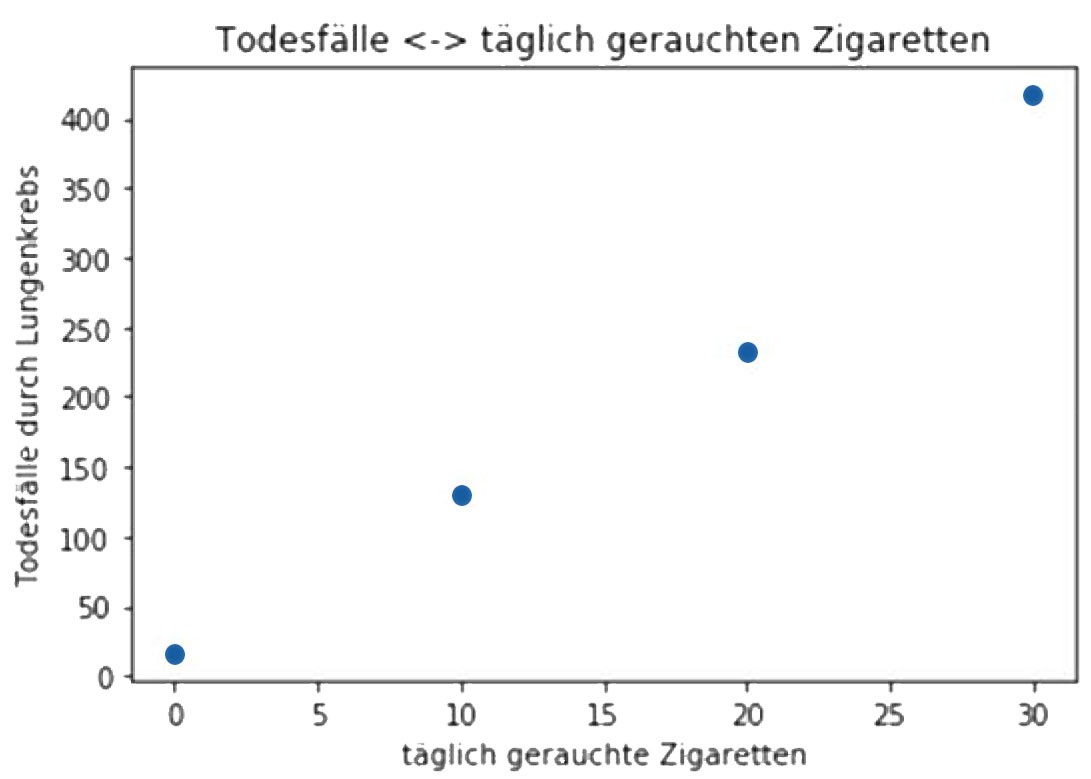
Die British Doctors Study [2] hat über 50 Jahre hinweg unter anderem die Sterblichkeit von Rauchern untersucht. Einige der Ergebnisse sollen im Folgenden in einem Beispiel analysiert werden. Hierzu dienen die Daten aus Tabelle 1. Angaben wie „über 25" lassen sich nicht mit einem analytischen Verfahren verwenden, dass Zahlen als Eingabeparameter erwartet. Daher wird im Folgenden mit einem vereinfachten Wert gearbeitet, der den tatsächlichen Wert ersetzt.
| Zigrattenkonsum (pro Tag) | Zigarettenkonsum (vereinfachter Wert) |
Todesfälle durch Lungenkrebs (100 TSD Männer/Jahr) |
| 0 | 0 | 17 |
| 1-14 | 10 | 131 |
| 15-24 | 20 | 233 |
| über 25 | 30 | 417 |
Tabelle 1: Auswertungen aus der British Doctors Study [2]
Beispielanalyse mit Python
Wie bereits im zweiten Artikel der Reihe Data Mining [3] wird auch für dieses Beispiel Python mit anaconda [4] und dem Jupyter Notebook [5] eingesetzt. Es ist ratsam sich vor dem eigentlichen Beginn einer Analyse einen Überblick über die Daten zu verschaffen. Der in Abbildung 3 dargestellte Scatterplot der Daten bildet hierzu eine gute Grundlage. Der Plot wurde mit dem Code aus Abbildung 4 erzeugt. Nach notwendigen Imports werden die Daten aus Tabelle 1 in ein Pandas DataFrame geladen und mit der Bibliothek matplotlib ausgegeben. Bei so wenigen Daten lässt sich schon durch reines Hinschauen ein Zusammenhang zwischen der Zahl der täglich gerauchten Zigaretten und der Sterblichkeit durch Lungenkrebs erkennen.
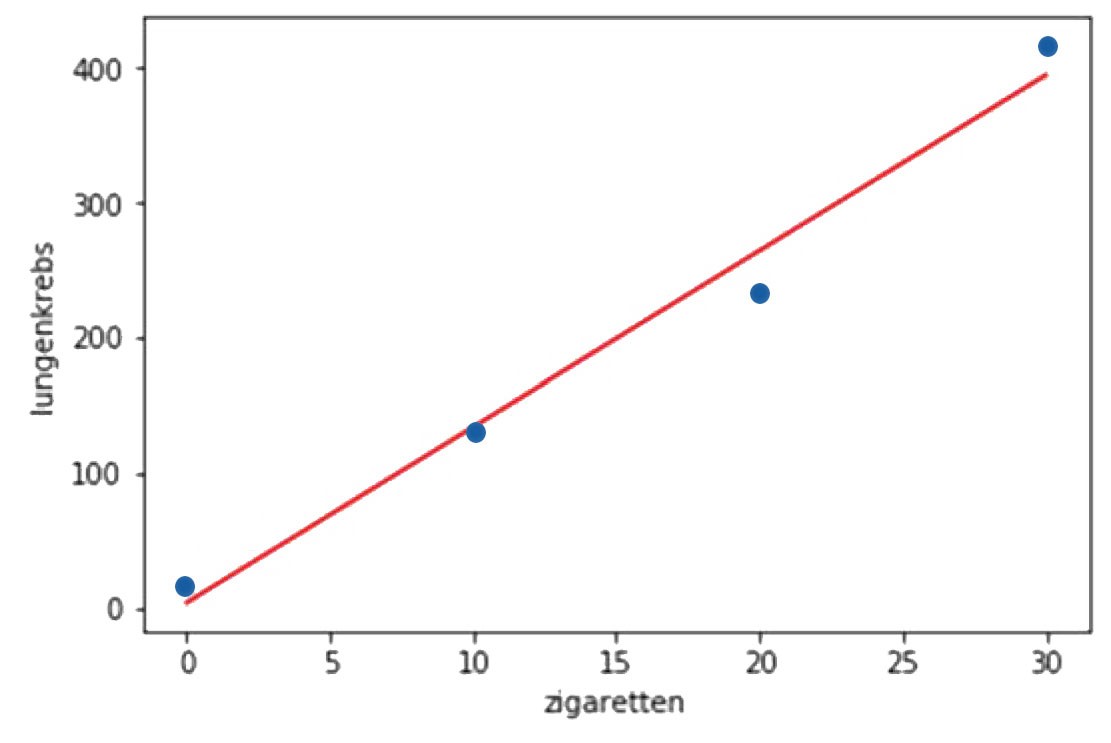
In Abbildung 5 wird dieser Zusammenhang belegt nachdem das Ergebnis einer Regressionsanalyse (zu sehen in dem Code der Abbildung 6) mit in den Scatterplot eingefügt wurde.
In diesem Beispiel wird die Methode stats.linregress aus dem Paket SciPy [6] verwendet. In vielen anderen Bibliotheken existieren vergleichbare Methoden.
Der Methode stats.linregress werden mit dem Befehl df.zigaretten und df.lungenkrebs die zu analysierenden Daten übergeben. Als Ergebnis besonders interessant sind die beiden Parameter beta_0 und beta_1. Diese werden verwendet, um zu 100 x-Werten zwischen dem minimalen und maximalen Zigarettenkonsum entsprechende y-Werte zu berechnen. Die Zahl von 100 ist willkürlich gewählt, um einen möglichst glatten Plot zu erreichen. Relevant wird diese Zahl beim Plot von Ergebnissen einer multiplen linearen Regression, die nicht durch eine einfache Gerade gezeichnet werden kann.
Von den weiteren Rückgabewerten der Methode stats.linregress ist insbesondere der r_value von Interesse. Quadriert wird er zu r2 und ist eine in der Statistik weit verbreitete Maßzahl für die Qualität eines Modells. Ein Wert von 1 steht hierbei für ein perfektes Ergebnis ohne existierenden statistischen Fehler. Umso kleiner der Wert wird, desto schlechter ist das Modell. Der absolute Wert von 0,98 bescheinigt unserem Modell eine gute Qualität. Der Blick auf die Gerade aus Abbildung 5 bestätigt dies, da sie die Datenpunkte gut repräsentiert.
Interessanter als der absolute Wert ist jedoch der Vergleich der r2-Werte von verschiedenen in Frage kommenden Modellen. Die Maßzahl kann in einem solchen Fall genutzt werden, um gute von schlechten Modellen zu unterscheiden.
%matplotlib inline
import matplotlib.pyplot asplt
import pandas as pd
df = pd.DataFrame ({'zigaretten':[0,10,20,30],
'lungenkrebs': [17,131,233,417]}])
df.plot('zigaretten', 'lungenkrebs', kind='scatter')
plt.title('Todesfälle <-> täglich gerauchte Zigaretten')
plt.xlabel('täglich gerauchte Zigaretten')
plt.ylabel('Todesfälle durch Lungenkrebs')
plt.plot()
Abb. 4: Datenerzeugung und Ausgabe als Scatterplot
import numpy as np
from scipy import stats
df.plot ('zigaretten', 'lugenkrebs', kind='scatter')
beta_1, beta_0, r_value, p_value, std_err = stats.
linregress(df.zigaretten, df.lungenkrebs)
X = np.linspace(df.zigaretten.min(), df.zigaretten.max(), 100)
Y = beta_0 + beta1 * X
plt.plot(X; Y; color='red')
plt.show()
Ausblick multiple lineare Regression
Im Code-Beispiel wurde nur eine Quellvariable betrachtet. In der Praxis gibt es natürlich sehr viele verschiedene Einflussfaktoren auf eine Zielvariable. Auch wenn die zu Grunde liegende Mathematik etwas komplexer wird, unterscheiden sich uni- und multiple lineare Regression von den Verfahren her nicht wesentlich.
Interessant ist vielmehr ein ganz neuer Aspekt, den es zu beachten gibt. Und zwar gilt es aus der häufig sehr großen Menge an Quellvariablen diejenigen zu identifizieren, die den größten Einfluss auf die Zielvariable haben. Ein gutes Modell kann eine Zielvariable mit möglichst wenigen, dafür tatsächlich relevanten, Quellvariablen vorhersagen.
Um ein gutes Modell zu finden, müssen in der Praxis viele unterschiedliche Modelle betrachtet werden. Die mögliche Zahl der verschiedenen Modelle steigt exponenziell mit der Anzahl der Quellvariablen. Bei der Modellauswahl helfen mathematische Verfahren, aber zu einem großen Teil auch die Erfahrung des Menschen, der die Analysen vornimmt.
Einige warnende Worte zum Ende
Vorsicht bei Extrapolation. Im ersten Beispiel wurden Werte von x zwischen 1 und 10 zur Erzeugung des Modells verwendet. Nur in diesem Bereich kann das Modell sinnvolle Vorhersagen treffen, da es auch nur in diesem Wertebereich trainiert wurde.
Vorsicht vor Ausreißern. Eine Tageshöchsttemperatur von 1.000° C ist für einen Menschen als klarer Messfehler erkennbar und sollte somit bei der Modellermittlung nicht beachtet werden. Gerade bei wenigen verfügbaren Trainingswerten kann ein solcher Ausreißer einen deutlichen Einfluss auf ein Modell haben und es im Zweifel sogar gänzlich unbrauchbar machen. Es gilt also geeignete Verfahren zu verwenden, die Ausreißer zu erkennen und diese gegebenenfalls zu entfernen.
Fazit
Mithilfe der linearern Regression lassen sich aus vorhandenen Daten Modelle erstellen, die in der Lage sind für neue Datensätze Vorhersagen zu treffen. Die eingesetzten Algorithmen sind mathematisch recht komplex, verdichten sich aber mit geeigneten Python-Bibliotheken auf wenige Zeilen Code.
Um gute Ergebnisse zu erzielen, müssen in der Praxis sehr viele mögliche Modelle miteinander verglichen werden und Ausreißer zuverlässig als solche erkannt werden. Hierzu ist spezielles Wissen erforderlich, welches aber nur im engen Zusammenspiel mit eingehender Kenntnis der Daten seine vollen Möglichkeiten ausspielt. Aus dieser Sicht macht es Sinn, bereits früh in einem Projekt Fachabteilung und Experten aus dem Bereich Data Mining an einen Tisch zu bringen.
Links/Quellen
[2] British Doctors Study zur Sterblichkeit bei Rauchern https://www.ncbi.nlm.nih.gov/pmc/articles/PMC437139/
[3] ORDIX® news Artikel 1/2017 – „Data Mining in der Praxis (Teil II) - Klassifikation": https://ordix.de/ordix-news-archiv/1-2017.html
[4] Anaconda Cloud https://anaconda.org/
[5] Project Jupyter http://jupyter.org/
[6] Tools für Python https://www.scipy.org/
Bildnachweis
© iStockphoto | flyfloor | Diagrams projection
Kommentare