
Jede Hürde meistern? Data Warehousing mit Apache NiFi?
Mit seiner benutzerfreundlichen Web-Oberfläche und den vielfältigen Möglichkeiten zur Datenintegration ist Apache NiFi ein „go-to-Tool“, wenn es um Datenverarbeitung und -übertragung geht. In diesem Blogbeitrag wollen wir unsere Erfahrungen im Aufbau eines Data Warehouse mit Apache NiFi teilen und einen Überblick darüber geben, was NiFi auf diesem Gebiet leisten kann und an welchen Stellen potenzielle Fallstricke lauern.
Ob man auf Daten von IOT-Geräten, relationalen Datenbanken oder Cloud-Services zugreifen möchte, NiFi bietet eine Vielzahl an Integrations- und Extraktionsmöglichkeiten.
In der Theorie klingt dies vielversprechend, aber wie bewährt sich dieses Tool in der Praxis, vor allem beim Aufbau eines Data Warehouses?
Unser Use-Case: Ein Self-Service Business Intelligence Tool
Unsere Herausforderung bestand darin, mithilfe von PowerBI ein internes Self-Service Business Intelligence Tool zu entwickeln. Bekanntlich ist die Grundlage eines jeden Reports ein sauber strukturiertes und hochqualitatives Data Warehouse.
Um Kosten zu sparen, die Performance zu verbessern und die Quelldatenbank zu entlasten, entschieden wir uns, unser Data Warehouse auf einer separaten PostgreSQL-Datenbank zu betreiben. Wir nutzten Apache NiFi, um die Daten aus der Quelldatenbank, unserem zentralen ERP-System, zu extrahieren und zu laden. Dabei war es wichtig, die Daten auf referenzielle Integrität zu überprüfen und zu bereinigen sowie sie zu historisieren, um Änderungen nachvollziehen zu können.
Unser Data Warehouse besteht aus einer Staging-, Core- und Datamart-Area. In die Staging-Area werden initial alle Rohdaten geladen. In der Core-Area beginnen wir unsere Daten zu bereinigen, zu validieren und zu historisieren. Im Datamart werden die Daten so aufbereitet, dass sie für den/die Endanwender:in leicht konsumierbar sind. Den Aufbau des Data Warehouses kann man auch im Detail aus der unteren Grafik entnehmen.
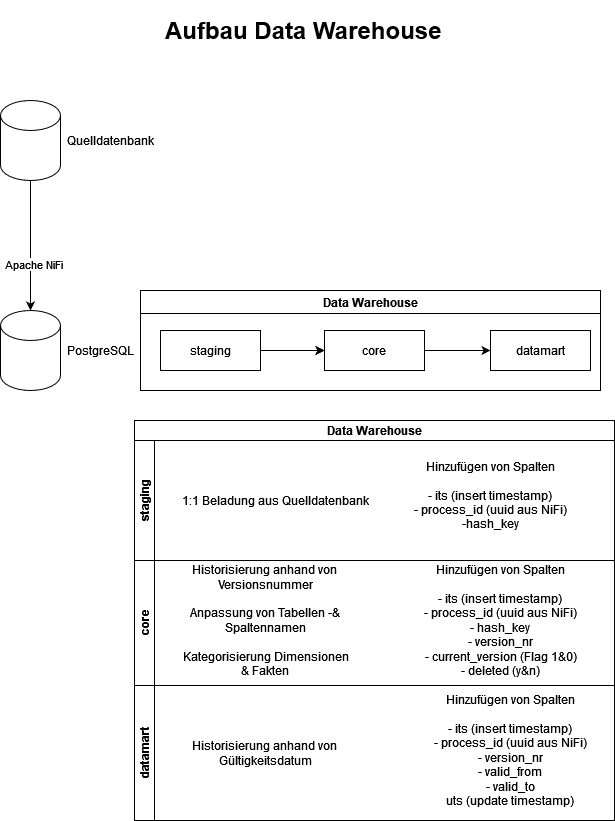
Hürde #1 – Die Beladung der „Staging-Area"
Im Staging-Bereich laden wir die Daten unverändert in die PostgreSQL-Datenbank. Wir ergänzen lediglich drei Spalten: einen Insert-Timestamp zur Nachverfolgung des Erhaltzeitpunkts, eine Prozess-ID zur Identifikation der auslösenden NiFi-Prozedur und eine Hash-Key-Spalte für die spätere Historisierung.
Um die Daten aus der Quelldatenbank abzurufen, nutzen wir den ExecuteSQLRecord-Prozessor (grün im nachfolgenden Bild). Dieser führt einen SELECT-Befehl auf der Quelldatenbank aus und lädt die gewünschte Tabelle als JSON-Datei in NiFi. Innerhalb von NiFi können wir Transformationen durchführen, wie z. B. das Hinzufügen von Spalten mit dem QueryRecord-Prozessor (blau im Bild). Schließlich konvertieren wir die JSON-Dateien mit dem ConvertJSONtoSQL-Prozessor in INSERT-Statements und führen diese mit dem PutSQL-Prozessor (violett im Bild) auf der PostgreSQL-Datenbank.
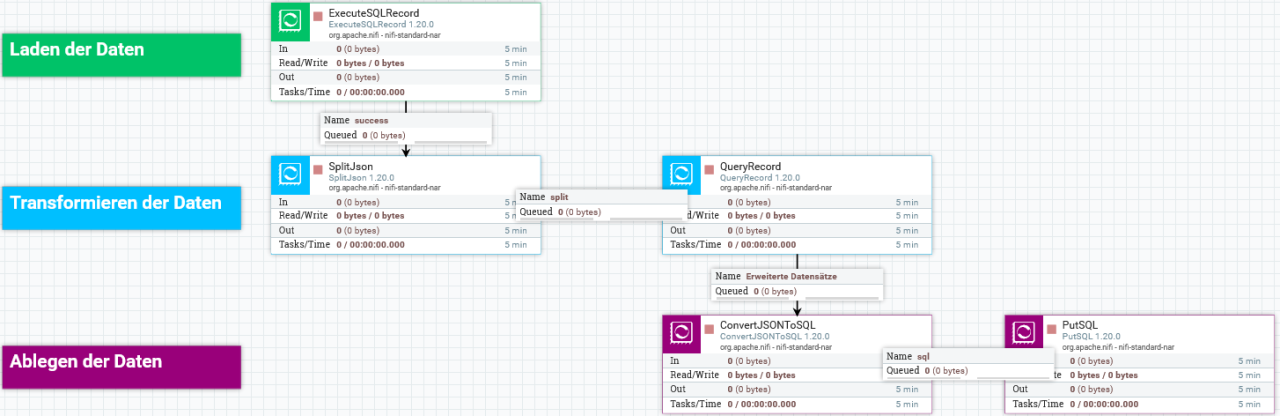
Hier machten wir unsere ersten Lernerfahrungen. Welchen Prozessor nutzen wir? Es gibt Viele, die auf Datenbanken zugreifen und jeweils für spezifische Anwendungsfälle ausgelegt sind. Einige unserer initialen Lösungsansätze, wie die Nutzung des ExecuteSQL-Prozessors und das anschließende Transformieren in JSON-Dateien, erzeugten erheblichen Overhead und führten zu Performanceproblemen. Beispielsweise dauerte das Laden einer Tabelle mit etwas über 600.000 Einträgen und deren Transformation ins JSON-Format über eine Stunde. Andere Ansätze, wie der QueryDatabaseTables-Prozessor, waren zwar performanter, boten aber nicht genügend Freiraum für die Transformation unserer Datenbankeinträge.
Apache NiFi hat mittlerweile in vielen Prozessoren einen Record-Reader und -Writer implementiert, der sehr effizient FlowFiles in verschiedenen Formaten ausgeben kann. Aus diesem Grund haben wir uns für den ExecuteSQLRecord-Prozessor entschieden.
Für Eins-zu-Eins-Migrationen bietet Apache NiFi natürlich auch einfachere und effizientere Lösungen an, wie z. B. die Prozessoren: QueryDatabaseTables, PutDatabaseRecord und ListDatabaseTables.
Zusätzlich stellte sich die Frage, ob wir pro Tabelle einen Flow erstellen müssen. Da wir mehr als 50 Tabellen migrieren, wäre es ineffizient, für jede Tabelle und jeden Beladungsschritt separate Flows aufzusetzen. Um dies zu vermeiden, nutzen wir den GenerateFlowFile-Prozessor als Trigger. Dieser Prozessor erzeugt FlowFiles mit vordefinierten Inhalten und Attributen. In ihm hinterlegen wir eine Liste der Tabellennamen und übergeben diese als Attribute für die weitere Verarbeitung an die nachfolgenden Prozessoren. Die Arbeit mit Attributen ist in NiFi sehr effizient und wird daher empfohlen.
Hürde #2 – Die Beladung des Cores
Für unsere Core-Beladung hatten wir gleich eine Handvoll von Anforderungen: Anpassung und Änderung von Tabellen- und Spaltennamen, funktionale Delta-Beladungslogik und der Historisierung der Daten.
Tabellen- und Spaltennamen innerhalb von NiFi anzupassen, stellt keine große Herausforderung dar. Dies ist durch mehrere Prozessoren einfach zu verwirklichen. Wir nutzten anfänglich den JoltTransformJson-Prozessor, der JOLT-Transformationen auf JSON-Dateien durchführt. So können wir mit diesem Spalten leicht umbenennen oder die Struktur sowie den Inhalt der Tabelle manipulieren. Der JoltTransformJson-Prozessor arbeitet mit dem Inhalt der FlowFiles. Dieser wird, wenn nicht benötigt, gesondert im Content Repository gespeichert und nur bei Bedarf in NiFi geladen. Dies erlaubt in der Regel eine effiziente und schnelle Bearbeitung der Daten innerhalb des Flows. Wenn wir jedoch große Datenmengen einschließlich der Daten in NiFi prozessieren, werden diese zunächst in den Arbeitsspeicher geladen, was zu einem großen Overhead führen kann. Ein weiterer Prozessor, den man für diesen Use-Case nutzen kann, ist der QueryRecord-Prozessor. Für diesen benötigen wir keine Jolt-Transformationen, sondern können direkt im SQL-Format die gewünschten Transformationen auf beliebigen Dateiformaten ausführen lassen.
Eine weitere unbeantwortete Frage war die Verfolgung von Datenänderungen in den Quelldaten. Wie können wir diese mit NiFi mitbekommen?
Für bestimmte Quelldatenbanken (z. B. MySQL, PGSQL) gibt es Prozessoren, die über „Data Mining“-Technologie Datenänderungen nachverfolgen können. Für unsere Quelle, eine Informix-Datenbank, gibt es aktuell keine entsprechende Lösung. Damit stellt sich die nächste Frage: „Können wir Änderungen an der Datenquelle generisch verfolgen?“ Wir haben aus diesem Grund eine eigene Delta-Beladungslogik entwickelt und in NiFi implementiert.
Wir haben ein Verfahren entwickelt, das Datenänderungen nachverfolgen kann. Dazu nutzen wir JOINS auf den Daten in der Staging- und Core-Area der Postgres-Datenbank. Zusätzlich haben wir die Spalte „hash_key“ eingeführt, die die Hash-Werte der einzelnen Zeilen berechnet und uns erlaubt, die Zeilen miteinander zu vergleichen. Dabei ist die meiste Arbeit für die Lookups auf die Datenbank verlegt worden. Hier ist wichtig zu erwähnen, dass es kaum die Möglichkeit gibt, Daten innerhalb von NiFi zu mappen und zu joinen. So haben wir uns entschieden, die JOINS mithilfe des ExecuteSQL-Prozessors auf der Datenbank auszuführen und die bereits gefilterten Daten zur Weiterverarbeitung in NiFi zu laden.
Hürde #3 – Delta-Beladungslogik
Wie oben erwähnt, gibt es bedauerlicherweise keinen speziellen NiFi-Prozessor, der Datenänderungen in anderen Datenbanken automatisch verfolgen kann. Doch das bedeutet noch lange nicht, dass wir diese Herausforderung nicht meistern können. Mithilfe der Deltabeladungslogik möchten wir alle Änderungen in unserer Staging-Area nachverfolgen und in unserem Core-Bereich historisieren. Dafür haben wir einige zusätzliche Spalten eingeführt, darunter „version_nr“, „current_version“, „deleted“, sowie „hash_key“.
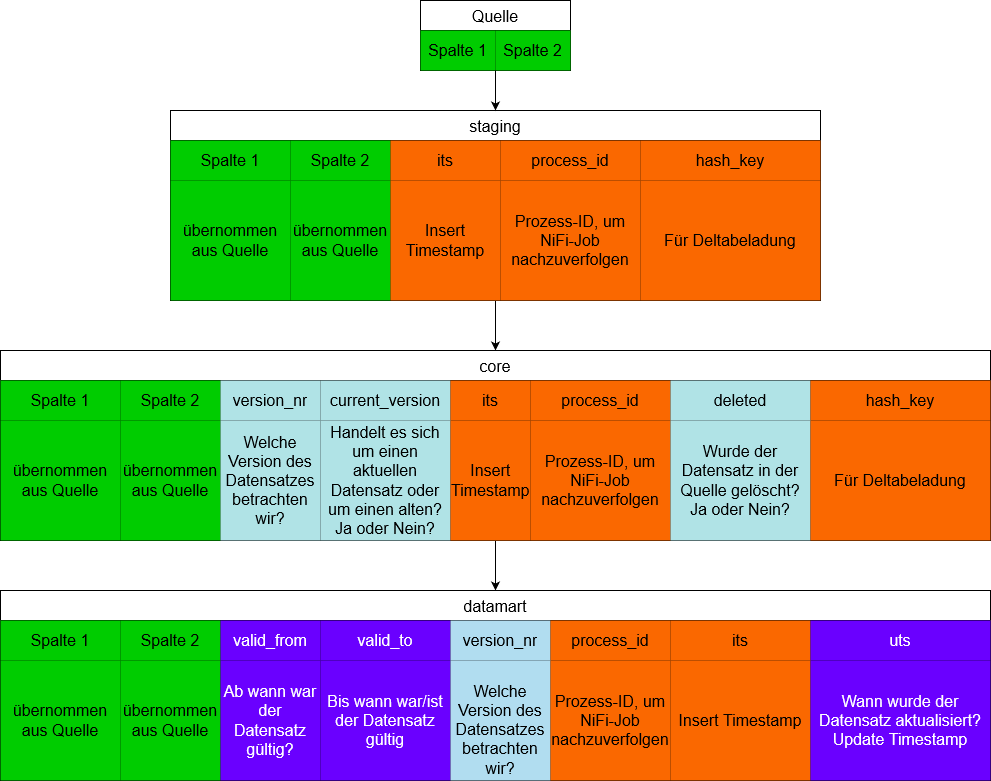
Die Spalten „current_version“ und „deleted“ fungieren als Flags. Das Flag „current_version“ bietet uns bei mehreren Versionen („version_nr“) einen einfachen Überblick über die Aktualität der Daten, während das „deleted“-Flag es uns ermöglicht, gelöschte Zeilen aus der Quelle zu historisieren. Das Diagramm oben verdeutlicht, wie wir über unseren Verarbeitungsprozess sukzessive Informationen („Flags“) unseren Daten hinzufügen und damit die notwendigen Informationen für unsere oben definierten Anforderungen generieren.
Für unsere Deltabeladungslogik gibt es vier Arten von Änderungen, die wir berücksichtigen mussten:
Änderungsnachverfolgung im Staging
1. Gelöschte Zeilen:
- Mit einem LEFT JOIN und den Primary Keys ermitteln wir, welche Zeilen im Core, aber nicht mehr im Staging vorhanden sind.
- Identifizierte Zeilen werden mit einem "deleted"-Flag markiert und die Tabelle in der Core-Area aktualisiert.
2. Neue Zeilen:
- Mit einem RIGHT JOIN ermitteln wir, welche Zeilen im Staging, aber nicht im Core vorhanden sind.
- Diese neuen Zeilen werden transformiert und in die Core-Area übernommen.
3. Geänderte Zeilen:
- Ein JOIN unter Berücksichtigung der Spalten „version_nr“, „current_version“ und „hash_key“ identifiziert geänderte Zeilen.
- Bei einer Diskrepanz der Hash Keys wird die neue Version des Datensatzes in die Core-Area hinzugefügt.
4. Keine Änderungserkennung möglich:
- Tabellen ohne Primary Key werden per TRUNCATE INSERT aktualisiert.
Alle Schritte werden über dieselben Prozessoren ausgeführt, indem Primary Keys, Tabellennamen und andere wichtige Daten als Attribute übergeben werden. Dies ermöglicht eine einfache Erweiterung der Tabellenliste ohne Änderungen am Flow.
Hürde #4 – Immer komplexer werdende Flows und die Datamart-Beladung
Für die Beladung unseres Datamarts war es erforderlich, eine Historisierung mit Gültigkeitszeiträumen umzusetzen. Wir führten die Spalten „valid_from“, „valid_to“ und „uts“ (Update-Timestamp) ein, um nicht nur die verschiedenen Versionen zu verfolgen, sondern auch festzuhalten, von wann bis wann sie gültig waren. Dadurch konnten wir genau bestimmen, wann Änderungen vorgenommen wurden.
Unser NiFi-Flow wurde mit steigenden Anforderungen immer komplexer. Daher haben wir diese spezielle Anforderung vor allem mit MERGE-Skripten gelöst, die wir über Apache NiFi auslösen. Für uns war dies praktischer, obwohl NiFi theoretisch die Aufgabe ebenfalls bewältigen könnte.
Die Ziellinie – Aus Erfahrungen lernen
Es ist wichtig, aus den Erfahrungen zu lernen und objektiv zu bleiben, unabhängig von der eigenen Begeisterung für das verwendete Tool.
Obwohl Apache NiFi viele Stärken hat, insbesondere in der Kategorie „Extraktion und Laden“, ist die Transformation von Daten noch eingeschränkt. So bietet es leider noch immer keine Möglichkeit, Unterschiede zwischen Daten zu verfolgen. Daher mussten wir für unsere Deltabeladungslogik einen komplexen Dataflow erstellen. Wichtig ist hier zu erwähnen, dass Apache NiFi kein klassisches ETL-Tool ist, auch wenn es manchmal fälschlicherweise als solches betrachtet wird. Apache NiFi ist ein Datenintegrationstool, welches oftmals im Big Data-Kontext Anwendung findet.
Apache NiFi bietet nur begrenzte Möglichkeiten, unterschiedliche FlowFiles miteinander zu mappen oder zu „joinen“. Wenn man Lookups über verschiedene Tabellen erstellen möchte, muss man für jede Spalte einen eigenen Controller-Service anlegen. Doch sobald wir über mehrere Spalten „joinen“ wollten, stieß diese Lösung an ihre Grenzen. Wir haben viele verschiedene Ansätze ausprobiert, sei es mit von der Community entwickelten Prozessoren oder eigenen Skripten. Bedauerlicherweise war es nicht möglich, Mappings innerhalb von NiFi zu realisieren. Die Arbeit mit dem Inhalt ist anspruchsvoll und belastet sowohl die Performance als auch den Arbeitsspeicher. Daher sollte dies, wenn möglich, vermieden werden, um allgemeine Transformationen weniger aufwendig zu gestalten. NiFi ermöglicht jedoch eine ausgezeichnete Arbeit mit Attributen. Man kann auch in einigen Fällen die Arbeit mit dem Inhalt umgehen, indem man diesen einmalig als Attribut speichert und alle Transformationen auf diesen ausführt.
Eine der vielen Stärken von NiFi ist die sehr aktive Community. Bei der Suche nach Lösungen für verschiedene Probleme sind wir auf Prozessoren und Lösungsansätze gestoßen, die von der Community entwickelt wurden. Da es sich um ein Open-Source-Tool handelt, entwickelt sich NiFi stets in verschiedenen Richtungen weiter.
Die Integration verschiedener Quellen verläuft reibungslos. Wir haben beispielsweise Daten von HTTP-Seiten angefordert und in unserer Datenbank gespeichert. Die Anbindung an Zielsysteme ist ebenfalls einfach. Wir versenden einige der Daten als E-Mail mithilfe des PutEmail-Prozessors und speichern sie gleichzeitig in zwei verschiedenen Datenbanken. Die Daten könnten auch in der Cloud oder in lokalen Dateisystemen abgelegt werden. Apache NiFi bietet an sich eine Vielzahl an Connectoren und Prozessoren, um Datenquellen und Zielsysteme anzubinden.
Das Transformieren in andere Formate stellt kein Problem dar und ist sogar in einigen Prozessoren integriert. So kann man direkt angeben, ob der FlowFile als JSON, XML, CSV, Avro, Parquet oder in einem anderen gewünschten Format ausgegeben werden soll.
Kann man nun mit Apache NiFi erfolgreich ein Data Warehouse aufbauen? Sicherlich. Es bedarf nur einiges an Kreativität und einige kleine Umwege.
Tatsächlich haben wir uns am Ende gegen NiFi entschieden, aus verschiedenen Gründen, aber vor allem wegen der Performance-Probleme. Wir nutzen es weiterhin als Datenintegrationstool, um Daten aus unseren unterschiedlichen Quellen in die Cloud zu laden. Als ETL-Tool verwenden wir es nicht mehr und haben uns dazu entschieden, ein klassischen ELT in unserer Datenbank aufzubauen.
Seminarempfehlungen
APACHE NIFI GRUNDLAGEN DB-BIG-07
Mehr erfahrenAPACHE NIFI GRUNDLAGEN - KOSTENLOSES WEBINAR W-NIFI-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahren
MeetUp: Apache NiFi Germany
Tipp: Für den fachlichen Austausch empfehlen wir außerdem die MeetUp-Gruppe „Apache NiFi Germany“:
Consultant bei ORDIX
Kommentare