
Effiziente Containerisierung: JEE-Anwendung mit Datenbankanbindung in Docker für Staging optimieren
In diesem Blog-Beitrag zeigen wir euch, wie ihr eine einfache JEE-Anwendung mit Datenbankanbindung mithilfe von JBoss (oder WildFly) und Docker für den Einsatz in unterschiedlichen Umgebungen containerisieren könnt. Ihr erfahrt, wie ihr alle erforderlichen Konfigurationen und Programme in einem Docker-Image integrieren und spezifische Datenbankdetails erst im finalen Schritt der Container-Erstellung hinzufügen könnt.
Ausgangslage
Für unser Projekt benötigen wir einen Applikationsserver, der der JBoss Version EAP 7.4 entspricht. Die JEE-Anwendung, die darauf läuft, erstellt eine Tabelle in einer Datenbank und bietet eine spezifische URL, über die Daten über eine Web-Seite eingegeben und in der Datenbank gespeichert werden können. Die Herausforderung besteht darin, diese Anwendung in einem Docker-Image zu integrieren, das generalisierte Datenquellen-Konfigurationselemente wie Verbindungs-String, Benutzername und Passwort enthält. Diese Details sollen jedoch erst bei der Erstellung des Containers, etwa über die Kommandozeile, hinzugefügt werden, um die Wiederverwendbarkeit zu gewährleisten.
Die Bedeutung von Staging
Bevor wir ins Detail gehen, ist es wichtig zu verstehen, warum das Staging in diesem Szenario so entscheidend ist. Staging ist eine Phase im Softwareentwicklungsprozess, die zwischen der Entwicklung und der Produktion liegt. Es handelt sich um eine nahezu exakte Kopie der Produktionsumgebung, in der eine Anwendung getestet wird, bevor sie live geht.
Warum ist das so wichtig?
- Realitätsnahe Tests: Im Staging wird die Anwendung unter Bedingungen getestet, die der Produktionsumgebung sehr nahekommen. Dies stellt sicher, dass die Anwendung in der Live-Umgebung einwandfrei funktioniert.
- Fehlervermeidung: Durch das Testen im Staging können potenzielle Fehler identifiziert und behoben werden, bevor sie in die Produktion gelangen. Das minimiert das Risiko von Ausfällen oder anderen schwerwiegenden Problemen in der Live-Umgebung.
- Konfigurationsvalidierung: Da die Konfigurationen der Software erst im letzten Schritt hinzugefügt werden, ist das Staging der ideale Ort, um sicherzustellen, dass diese korrekt sind und die Anwendung wie erwartet funktioniert.
- Benutzerakzeptanztest: Staging ermöglicht es, die Anwendung durch Endbenutzer oder Stakeholder testen zu lassen, bevor sie in die Produktionsumgebung überführt wird.
Durch die Integration von Staging in euren Containerisierungsprozess könnt ihr sicherstellen, dass eure Anwendung fehlerfrei läuft und alle Konfigurationen korrekt sind, bevor sie in die Produktion geht.
Prinzipieller Ablauf
Unsere Basis bildet ein bereits bestehendes, öffentlich verfügbares Docker Image. Dieses werden wir um zusätzliche Elemente erweitern und dann als neues Image lokal speichern. Aus diesem neuen Image erzeugen wir anschließend den eigentlichen Container, wobei wir die Konfigurationsdetails für die verwendete Datenquelle zur Laufzeit als Argumente übergeben.
Vereinfachte grafische Darstellung:
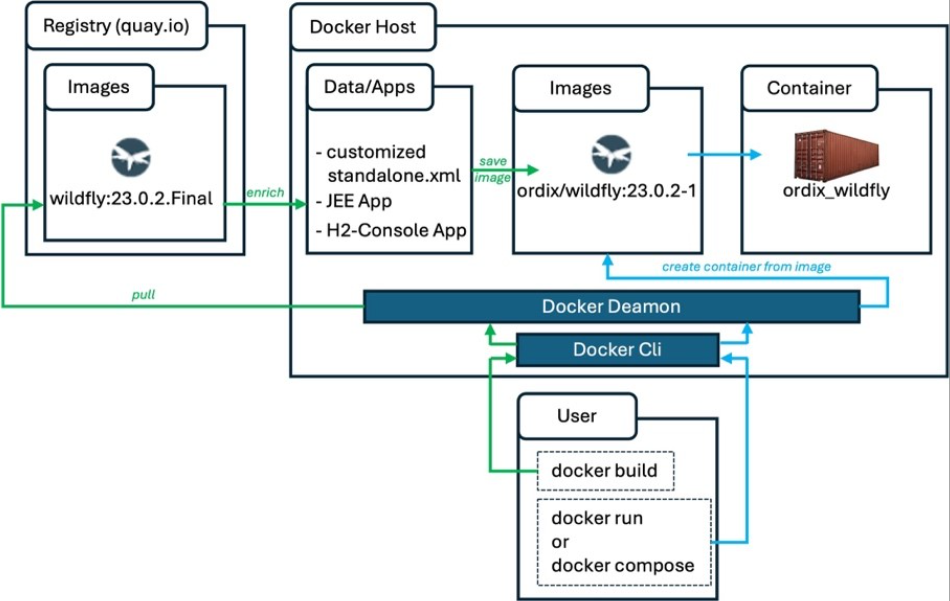
Erstellung des erweiterten Docker Images
Für dieses Vorhaben haben wir das frei verfügbare Docker-Basisimage ‚wildfly:23.0.2.Final' aus der quay.io Registry ausgewählt, das bereits eine H2-Datenbank enthält. Diese WildFly-Version ist kompatibel zu JBoss EAP 7.4. Die enthaltene Datenbank werden wir in unserer Anwendung nutzen (URL: quay.io/wildfly/wildfly:23.0.2.Final).
Damit die JEE-Anwendung später Daten in der Datenbank speichern kann, müssen sowohl die Anwendung als auch der WildFly-Server entsprechend konfiguriert werden.
In einem Java EE-Projekt, das auf WildFly ausgeführt wird, spielt die Datei ‚persistence.xml' eine entscheidende Rolle. Sie ist für die Konfiguration der Datenbank-Persistenz verantwortlich und definiert, wie die Anwendung mit der Datenbank interagiert. Die Datei befindet sich im Verzeichnis ‚META-INF´ der Anwendung und legt unter anderem die zu verwendende Datenquelle (‚jta-data-source') fest.
Für die korrekte Funktion der Anwendung muss sichergestellt sein, dass die in der ‚persistence.xml' angegebene Datenquelle (‚jta-data-source') mit dem in der Datei ‚standalone.xml' des WildFly-Servers konfigurierten JNDI-Namen übereinstimmt. Dies ermöglicht eine flexible Datenbankanbindung, die in verschiedenen Umgebungen genutzt werden kann.
Die Anpassung dieser Konfigurationen ist entscheidend, um eine reibungslose Interaktion zwischen der Anwendung und der Datenbank zu gewährleisten, insbesondere wenn die Anwendung containerisiert und in verschiedenen Umgebungen eingesetzt wird.
<app_name>/src/main/resources/META-INF/persistence.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="manager1" >
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source>
<class>entities.Kunde</class>
<!-- <validation-mode>CALLBACK</validation-mode> -->
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.hbm2ddl.auto" value="create-drop"/>
</properties>
</persistence-unit>
</persistence>
In einem WildFly-Server ist die zuvor genannte Datei ‚standalone.xml' eine zentrale Konfigurationsdatei, die alle wesentlichen Einstellungen des Servers enthält. Diese Datei definiert unter anderem Datenquellen, Sicherheitseinstellungen, Subsysteme, Logging-Konfigurationen und vieles mehr. Sie ist der Dreh- und Angelpunkt für die Konfiguration des Servers im sogenannten „Standalone-Modus“, in dem WildFly auf einem einzelnen Server oder in einer nicht-verbundenen Umgebung läuft.
Die Datei ‚standalone.xml' befindet sich im Verzeichnis:
/opt/jboss/wildfly/standalone/configuration
Diese Datei ist besonders wichtig, wenn man ein Docker-Image des Servers erstellt, da hier beispielsweise Parameter wie die Datenbank-Verbindungszeichenfolge, Benutzername und Passwort flexibel gehalten werden können, um sie erst bei der Erstellung des Docker-Containers zu spezifizieren. So wird sichergestellt, dass das gleiche Image in unterschiedlichen Umgebungen verwendet werden kann, indem die spezifischen Umgebungsparameter erst zur Laufzeit hinzugefügt werden.
Wie zuvor erwähnt wird WildFly standardmäßig mit einer vorkonfigurierten H2-Datenquelle ausgeliefert, die wir hier wiederverwenden. Der in der ‚standalone.xml' bereits vorhandene JNDI-Name muss daher direkt in die ‚persistence.xml' übernommen werden. Zusätzlich ist sicherzustellen, dass die ‚persistence.xml' auf den für H2 benötigten ‚hibernate.dialect' eingestellt ist. Danach kann die Anwendung kompiliert und die benötigte *.war Datei erstellt werden.
Hier wird eine WAR-Datei (Web Application Archive), anstelle einer *.jar, verwendet, weil sie speziell für die Bereitstellung von Webanwendungen in Java Enterprise-Umgebungen entwickelt wurde. Eine WAR-Datei enthält alle benötigten Ressourcen, einschließlich HTML, JSP-Seiten, Servlets und andere Komponenten, die für eine Webanwendung notwendig sind. Sie wird häufig verwendet, wenn es um die Bereitstellung von Webanwendungen auf einem Java Application Server wie WildFly geht.
Um zu vermeiden, dass die Details der Datenquelle in der WildFly-Konfigurationsdatei hart kodiert werden, modifizieren wir die Datei ‚standalone.xml'.
Die Konfiguration der Verbindungszeichenfolge, des Benutzernamens und Passworts wird wie folgt angepasst und für die spätere Verwendung lokal gespeichert.
/opt/jboss/wildfly/standalone/configuration/standalone.xml
…
<datasources>
<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="ExampleDS" enabled="true" use-java-context ="true" statistics-enabled="${wildfly.
datasources.statistics-enabled:${wildfly.statistics-enabled:false}}">
<connection-url>${env.DB_CONNECTIONSTRING}</connection-url>
<driver>h2</driver>
<security>
<user-name>${env.DB_USER}</user-name>
<password>${env.DB_PASSWORD}</password>
</security>
</datasource>
<drivers>
<driver name="h2" module="com.h2database.h2">
<xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
…
Die Einträge „${env.DB_CONNECTIONSTRING}", „${env.DB_USER}" und „${env.DB_PASSWORD}" ersetzen dabei die vorhandenen.
Die Erstellung des erweiterten Docker Images erfolgt nun mithilfe eines sogenannten Dockerfiles. Bei dieser Datei handelt es sich um eine Art Steuerdatei, in der in einem definierten Format hinterlegt wird, wie und womit das Image erstellt werden soll.
Dockerfile
# get base image from repository
FROM
quay.io/wildfly/wildfly:23.0.2.Final
# general info
LABEL maintainer="Ordix AG"
# copy applications to be deployed
COPY MitJpaPG.war /opt/jboss/wildfly/standalone/deployments/app.war
COPY H2Console.war /opt/jboss/wildfly/standalone/deployments/H2Console.war
# copy wildfly standalone configuration
COPY standalone.xml /opt/jboss/wildfly/standalone/configuration/standalone.xml
# set ports for outside reachability
EXPOSE 8080 9990
# add admin user
RUN ["/opt/jboss/wildfly/bin/add-user.sh","admin","password"]
# start wildfly in standalone mode
ENTRYPOINT ["/opt/jboss/wildfly/bin/standalone.sh","-b","0.0.0.0","-bmanagement","0.0.0.0"]
Die ins Image zu kopierenden Dateien (Zeilen 18 20 & 26) müssen dabei im gleichen Verzeichnis wie das Dockerfile liegen.
Durch die Eingabe des Kommandos:docker build -t ordix/wildfly:23.0.2-1 .
wird anschließend das erweiterte Image lokal erstellt (hier mit dem Namen ‚ordix/wildfly' und dem Tag (Version) 23.0.2-1). Dabei ist zu beachten, dass das Kommando im Verzeichnis auszuführen ist, in dem sich auch das Dockerfile befindet, da der ‚.' am Ende der Kommandozeile den Build-Kontext auf dieses festlegt.
Container Erstellung über ‚docker run'
Docker kann direkt über entsprechende Kommandos aus Images Container erzeugen.
Für den vorliegen Fall lautet die Kommandozeile:
docker run -it -p 8080:8080 -p 9990:9990
-e DB_CONNECTIONSTRING=”jdbc:h2:mem:test;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE” -e DB_USER=sa -e DB_PASSWORD=sa
--name=ordix_wildfly ordix/wildfly:23.0.2-1
Erklärung der Parameter:
- -it: Führt den Container nach dem Start im interaktiven Modus aus, sodass man direkt mit der Shell des Containers interagieren kann.
- -p: Weist Ports zu, durch die der Container von außen erreichbar ist. Hier bedeutet 8080:8080, dass der Hostport 8080 mit dem Containerport 8080 verknüpft wird.
- -e: Definiert Umgebungsvariablen für den Container. In diesem Beispiel werden Verbindungsdetails für die Datenbank als Umgebungsvariablen übergeben.
- --name: Gibt dem neuen Container einen spezifischen Namen, in diesem Fall ordix_wildfly.
- Letzter Parameter: Das Image, aus dem der Container erstellt wird, wird hier angegeben (ordix/wildfly:23.0.2-1). Dabei handelt es sich um das zuvor lokal erstellte Docker-Image. Es können aber auch Images aus öffentlichen Registries wie Docker Hub verwendet werden.
Mit diesem Befehl haben wir nun einen Container erstellt, der eine WildFly-Instanz ausführt und mit den angegebenen Datenbankverbindungsdetails konfiguriert ist. Damit können wir die Anwendung testen und in einer isolierten Umgebung bereitstellen.
Alternative Container-Erstellung über ‚docker compose'
Die Erstellung und Verwaltung von Containern über das ‚docker run'-Kommando kann schnell unübersichtlich und fehleranfällig werden, insbesondere wenn mehrere Container mit verschiedenen Parametern gestartet werden müssen. Hier bietet die Verwendung einer ‚compose.yml'-Datei erhebliche Vorteile:
- Übersichtlichkeit und Wartbarkeit: Eine ‚compose.yml'-Datei bündelt alle Konfigurationsparameter wie Umgebungsvariablen, Netzwerkeinstellungen und Volume-Mounts in einem einzigen Dokument. Dadurch wird die Verwaltung von Containern übersichtlicher und besser dokumentiert.
- Automatisierung und Skalierbarkeit: Mit Docker Compose könnt ihr komplexe Multi-Container-Anwendungen mit einem einzigen Befehl (‚docker-compose up') starten. Das vereinfacht die Automatisierung und ermöglicht eine einfache Skalierung von Diensten.
- Wiederholbarkeit: Die Konfiguration in einer ‚compose.yml'-Datei sorgt dafür, dass Container stets mit den gleichen Parametern gestartet werden, was die Wiederholbarkeit und Konsistenz der Deployments verbessert.
- Umgebungsspezifische Konfiguration: ‚compose.yml' ermöglicht es, Umgebungsvariablen und andere Einstellungen für verschiedene Umgebungen wie Entwicklung, Test und Produktion leicht anzupassen, ohne manuelle Eingaben in der Kommandozeile zu machen.
- Versionierung: Die ‚compose.yml'-Datei kann versioniert werden, was die Nachverfolgbarkeit von Änderungen erleichtert und die Zusammenarbeit im Team verbessert.
Insgesamt ermöglicht die Verwendung von ‚compose.yml' eine sauberere, reproduzierbare und effizientere Verwaltung von Docker-Containern, insbesondere bei der Arbeit mit komplexen Anwendungsumgebungen.
Im vorliegenden Fall sieht die Datei ‚compose.yml' wie folgt aus:
compose.yml
version: "3.9"
services:
wildfly_ordix:
image: ordix/wildfly:23.0.2-1
container_name: ordix_wildfly
volumes:
# creating volume as type 'volume'
- type: volume
source: wildfly_data
target: /opt/jboss
environment:
- "DB_CONNECTIONSTRING=${DB_CONNECTIONSTRING}"
- "DB_USER=${DB_USER}"
- "DB_PASSWORD=${DB_PASSWORD}"
ports:
- 8080:8080
- 9990:9990
# when creating volume as type 'volume' (path: /var/lib/docker/volumes/...)
volumes:
wildfly_data:
name: wildfly_data
Eine Besonderheit, gegenüber der zuvor gezeigten Container-Erstellung über ‚docker run', ist hier, dass wir zusätzlich einen definierten Containerpfad auf ein Docker Volume abbilden (Zeilen 11-21 & 39-43).
Wesentlicher Vorteil der Verwendung von Docker Volumes in einer ‚compose.yml'-Datei ist hier die Möglichkeit, bestimmte Verzeichnisse im Container auf den Host zu spiegeln. Dies wird durch die Definition von Volumes in der ‚compose.yml'-Datei ermöglicht.
Warum Volumes wichtig sind:
- Direkter Zugriff auf Container-Daten: Durch das Mapping eines Containerpfads auf ein Docker Volume kann direkt vom Host aus auf diesen Bereich zugegriffen werden und umgekehrt. So können zum Beispiel neue Applikationen problemlos in das Deployment-Verzeichnis des WildFly Servers kopiert werden.
- Persistente Datenspeicherung: Daten, die in einem Docker Volume gespeichert werden, bleiben auch nach dem Löschen des Containers erhalten. Dies ist besonders nützlich, wenn Anwendungen Daten speichern, die nicht verloren gehen sollen, selbst wenn der Container neu gestartet wird.
Ein Volume zeigt dabei auf ein bestimmtes Verzeichnis unter dem Pfad /var/lib/docker/volumes auf dem Host.
Die Kommandozeile zur Erzeugung des Containers über die ‚compose.yml' lautet wie folgt:
DB_CONNECTIONSTRING="jdbc:h2:mem:test;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE" DB_USER=sa DB_PASSWORD=sa docker compose up
In diesem Fall übergeben wir die Umgebungsvariablen (Environment-Informationen) direkt vor dem eigentlichen Befehl ‚docker compose up'.
- DB_CONNECTIONSTRING="jdbc:h2:mem:test;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE"
→ zeigt auf ${DB_CONNECTIONSTRING} in Zeile 25 der ‚compose.yml'
- DB_USER=sa
→ zeigt auf ${DB_USER} in Zeile 27 der ‚compose.yml'
- DB_PASSWORD=sa
→ zeigt auf ${DB_PASSWORD } in Zeile 29 der ‚compose.yml'
Wurden die Umgebungs-Informationen bereits zuvor gesetzt, dann reicht ein:
docker compose up
Fazit
Durch die Verwendung eines bestehenden WildFly-Container-Images war es uns möglich, ein neues Image mit verallgemeinerten Datenquellen-Konfigurationselementen zu erstellen. Dies erleichtert die Wiederverwendbarkeit in unterschiedlichen Umgebungen erheblich. Die daraufhin erzeugten Container lassen sich mit den Docker-Kommandos ‚run' oder ‚compose' einfach und konsistent für verschiedene Staging-Umgebungen erstellen.
Das Dockerfile und die ‚compose.yml' können in einer Versionsverwaltung gespeichert und in CI/CD-Prozesse integriert werden, was die Automatisierung und Nachverfolgbarkeit der Entwicklung fördert. Die Nutzung von ‚docker compose' bietet dabei klare Vorteile, da sie die oft fehleranfällige manuelle Eingabe von ‚docker run'-Kommandos vermeidet und eine zuverlässige, wiederholbare Bereitstellung ermöglicht.
Seminarempfehlung
DOCKER UND PODMAN CONTAINER ESSENTIALS E-DOCK-01
Mehr erfahrenPrincipal Consultant
Kommentare