
Apache Airflow – Einfache Automatisierung von Workflows im Unternehmen
Das Airflow-Projekt wurde im Oktober 2014 bei Airbnb gestartet, um das massive Wachstum an Daten-Workflows in den Griff zu bekommen. Seit Juni 2015, ist Airflow als Open-Source-Projekt verfügbar und wird von der Apache Software Foundation geleitet.
Airbnb bezeichnet Airflow als Workflow-Management-Plattform. Airflow ist in Python geschrieben und auch die Workflows selbst werden in Python definiert. Im Prinzip funktioniert Airflow ähnlich wie Cron, baut aber eher darauf auf, verschiedene, abhängige Tasks zu Workflows zusammenzuschließen und diese auszuführen. Die Abhängigkeiten können klar definiert und auch an Bedingungen geknüpft werden.
Integration von Airflow in andere Technologien
Um die Verbindung zwischen Airflow und anderen Technologien zu vereinfachen, bietet Airflow sogenannte Provider Packages an, die entsprechende Integrationen beinhalten. Dadurch können z.B. Technologien, wie HDFS oder Spark, direkt angesprochen werden, ohne dass die nötige Verbindung in eigenem Python Code implementiert werden muss. Mit nur wenig eigenem Code werden damit komplexe Daten-Pipelines und Workflows möglich.
Directed Acyclic Graphs
In Airflow werden Workflows als DAG definiert. Ein DAG ist ein gerichteter, azyklischer Graph (directed acyclic graph) und kommt ursprünglich aus der Grafentheorie. Ein Graph stellt eine abstrakte Struktur dar, die eine Menge von Objekten, sowie deren Verbindungen zueinander enthält. Dabei werden die Objekte als Knoten und die Verbindungen als Kanten bezeichnet.
Um einen Aufgabenablauf in Airflow zu realisieren, ist es wichtig, dass der Graph keine Wiederholungen enthält, also azyklisch ist. Da die Kanten in Airflow die Abhängigkeiten der Knoten (bzw. Tasks) anzeigen, kann eine zyklische Abhängigkeit nicht funktionieren.
Ein DAG in Airflow besteht aus mehreren Tasks (Knoten) und deren Abhängigkeiten zu den anderen Tasks (Kanten). Er ist die Datenstruktur, in der alle auszuführenden Aufgaben beschrieben werden müssen. Selbst wenn ein DAG nur ein Task enthält, muss dafür ein eigener, vollständiger DAG angelegt werden.
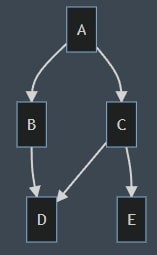
Im Bild ist ein beispielhafter DAG dargestellt, der als Einstiegspunkt Task A ausführt und danach die Tasks B und C. B und C haben keine Abhängigkeit untereinander und können parallel ausgeführt werden. Task E kann sofort nach Beendigung von Task C ausgeführt werden, während Task D noch eine zusätzliche Abhängigkeit zu Task B hat und auf die Beendigung dessen warten muss.
DAG-Files
DAG werden in Airflow als Python-Skripte implementiert. Tasks werden über Operatoren implementiert. Airflow liefert z.B. den PythonOperator, mit dem Python-Code ausgeführt wird, oder den BashOperator, der Shell-Befehle ausführt, mit. Für weitere Technologien werden Operatoren über Provider Packages hinzugefügt, z.B. für Apache HDFS, Apache Spark, Apache Cassandra, AWS S3, Google BigQuery oder Protokolle wie HTTP, FTP und SSH. Eine Übersicht über die Provider Packages findet sich in der Airflow-Dokumentation.
Obwohl alle Tasks in der gleichen Python-Datei implementiert werden, teilen sie sich in der Ausführung nicht unbedingt eine Python-Umgebung. Wenn mehrere "Worker" verwendet werden, können einzelne Tasks auf verschiedenen Servern ausgeführt werden. Variablen, Imports und Ähnliches können nicht taskübergreifend verwendet werden. Datensätze müssen entsprechend zwischengespeichert werden. Einzelne Variablen und geringe Datenmengen können über XComs geteilt werden.
Die DAG-Dateien müssen so abgelegt werden, dass alle weiteren Komponenten die Dateien lesen können, da kein direkter Code unter den Komponenten geteilt wird, sondern lediglich Anweisungen wie "Führe Task X aus DAG Y aus". Der auszuführende Code wird dann aus der Datei des DAG gelesen.
Airflow Komponenten
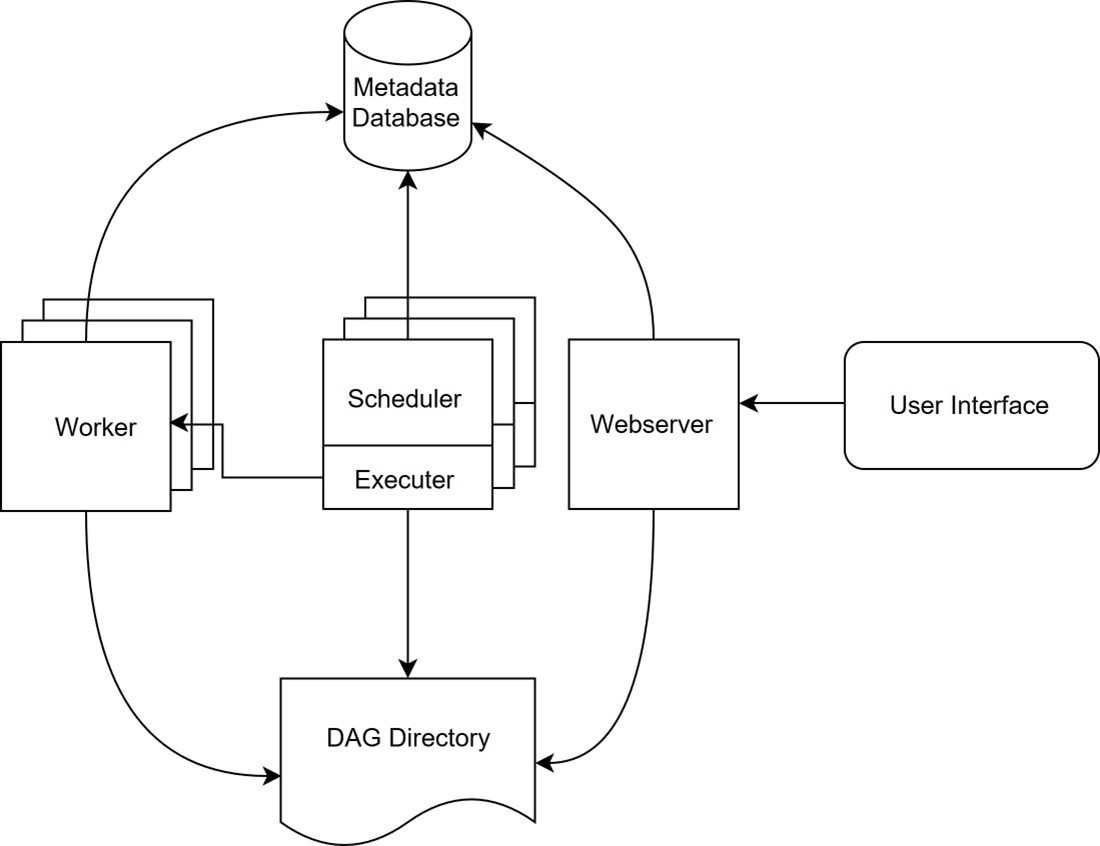
Scheduler
Der Scheduler ist die Kernkomponente von Airflow. Er ist dafür verantwortlich, die DAG zu lesen, deren Ausführung zu planen und "DAG Runs" zu erstellen. Ein DAG Run ist die laufende Instanz eines DAG. Ein DAG kann mehrere parallele Instanzen gleichzeitig haben. Sollte ein DAG Run nicht beendet sein, bevor der Job das nächste Mal läuft, so wird der Job trotzdem erneut gestartet. Die verschiedenen DAG Runs beinhalten eine zeitliche Eingrenzung, damit mehrere parallele Instanzen nicht die gleichen Daten verarbeiten.
Für den Scheduler ist der Inhalt des DAG irrelevant. Er benötigt den Ausführungszeitpunkt oder eventuelle andere Trigger, sowie die Taskübersicht. Andere Trigger können selbst implementiert werden oder auf vordefinierten Events basieren, bspw. kann ein DAG gestartet werden, wenn neue Dateien im HDFS abgelegt werden. Die vom Scheduler erstellten DAG Runs werden dann vom Executor lokal ausgeführt oder an weitere Worker aufgeteilt.
Executor
Der Executor ist für die Ausführung der Tasks zuständig. Er kann die Tasks entweder auf der eigenen Hardware (mit lokalen Exekutoren) oder auf mehreren Workern (mit Remote-Exekutoren) ausführen. Der Executor ist in den Scheduler integriert und verwendet den gleichen Prozess. Für eine Airflow-Installation kann nur ein Executor definiert werden. Eine Mischung aus mehreren Exekutoren (bspw. DAG A lokal, DAG B im Kubernetes Cluster) ist nicht möglich.
Von Airflow werden zum Zeitpunkt des Artikels die folgenden Exekutoren unterstützt:
Lokale Exekutoren:
- SequentialExecutor
- LocalExecutor
- DebugExecutor
- CeleryExecutor
- KubernetesExecutor
- CeleryKubernetesExecutor
- DaskExecutor
Datenbank
Airflow verwendet eine relationale Datenbank, um Metadaten abzuspeichern und die verschiedenen Komponenten zu synchronisieren. Offiziell unterstützt werden SQLite, MySQL und PostgreSQL. Theoretisch können Sie alle Datenbanken verwenden, die von SQLAlchemy unterstützt werden. SQLAlchemy ist eine Python-Bibliothek, die eine standardisierte API für verschiedene Datenbanken (z.B. MySQL, PostgreSQL, MS SQL-Server, etc.) bereitstellt.
Alle, außer der offiziell unterstützten Datenbanken, sind aber nicht getestet und ein problemloser Betrieb ist damit nicht garantiert. Einige Features werden teilweise auch offiziell nicht unterstützt, bspw. funktioniert ein Clustering der Scheduler mit dem MS SQL-Server nicht.
SQLite wird in der Standalone Installation von Airflow verwendet, jedoch nicht für eine produktive Nutzung empfohlen. Hierfür sollte MySQL oder PostgreSQL verwendet werden. SQLite unterstützt nicht alle Airflow-Features, bspw. kann der LocalExecutor nicht verwendet werden.
Alle Airflow-Komponenten müssen Zugriff auf die Datenbank haben, da diese der Kommunikationsweg zwischen den einzelnen Komponenten ist. Sollte die Datenbank abstürzen, kann auch Airflow nicht mehr arbeiten. Sie ist demnach ein Single Point-of-Failure.
In zukünftigen Versionen soll die Abhängigkeit zu der Datenbank verringert werden.
Webinterface
Zum Abschluss stellt Airflow noch ein Webinterface bereit, über das die einzelnen DAG und deren Ausführungen überwacht werden können. Hier können DAG auch aktiviert und gestoppt werden. Ein DAG kann im Webinterface auch direkt gestartet werden.
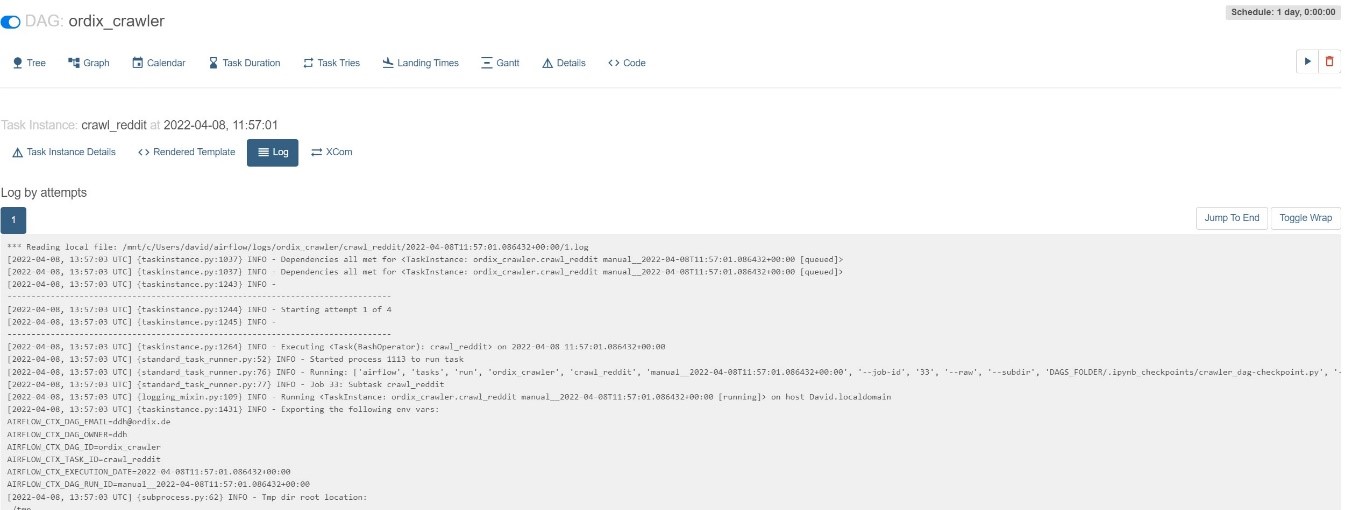
Während (und nach) der Ausführung können über das Webinterface Logs (siehe Bild) und weitere Informationen über die Ausführung eingesehen werden.
Hochverfügbarkeit von Airflow
Prinzipiell lassen sich alle Airflow-Komponenten einfach skalieren. Mehrere Worker können mit den Remote Exekutoren, wie dem CeleryExecutor oder dem KubernetesExecutor verwendet werden. Wenn, wie beim CeleryExecutor, weitere Technologien verwendet werden, müssen diese ebenfalls für Hochverfügbarkeit konfiguriert sein.
Die Skalierung des Schedulers (und damit die Skalierung des Executors) ist etwas komplizierter, da hier das Datenbank-Feature "row-level locks" (mit SELECT ... FOR UPDATE) verwendet wird. Dieses Feature wird ab PostgreSQL 9.6+ oder MySQL 8+ unterstützt. MariaDB sollte ab Version 10.6.0 funktionieren, wird vom Airflow-Team aber nicht offiziell getestet. Auch der MS SQL-Server wird nicht getestet. Hier kann eine Skalierung der Scheduler zu Fehlern und auch Deadlocks führen. MySQL 5.x unterstützt das Feature nicht und kann nicht für hochverfügbare Scheduler verwendet werden. (Siehe auch Scheduler — Airflow Documentation)
Die Datenbank muss als Single Point-of-Failure ebenfalls hochverfügbar konfiguriert sein. Oftmals wird dies durch Replicas oder Standby-Server erreicht, wie es z.B. für PostgreSQL in der Dokumentation erklärt wird.
Alle Komponenten (und auch alle Worker) benötigen weiterhin Zugriff auf die DAG-Dateien, z.B. über ein Netzlaufwerk oder eine Synchronisation der Dateien auf die verschiedenen Server.
Für Kubernetes gibt es offizielle, produktionsgeeignete HELM-Charts, die eine hochverfügbare Umgebung "ab Werk" unterstützen. Die Charts sind in der Airflow-Dokumentation zu finden.
Fazit
Airflow ist besonders geeignet, wenn viele verschiedene Aufgaben auf mehreren Servern, zu bestimmten Zeiten ausgeführt werden sollen. Für einzelne, lokale Aufgaben ist Airflow weniger geeignet, da hier der Konfigurationsaufwand zu hoch ist. Zum Ausprobieren ist die Standalone-Installation aber sehr einfach aufzusetzen.
Airflow hilft dabei, verschiedene Workflows im Unternehmen übersichtlich darzustellen, auszuführen und zu überwachen. Anfangs ist es zwar mit viel Aufwand verbunden, alle bestehenden Workflows auf Airflow zu migrieren. Dafür können diese danach aber alle in einer zentralen, (wenn richtig konfiguriert) hochverfügbaren Umgebung verwaltet werden.
In einem folgenden Blogartikel wird Ronny Horst die praktische Anwendung von Airflow in einem aktuellen Projekt beschreiben.
Quellen
Airflow Dokumentation - https://airflow.apache.org/docs/
Celery Dokumentation - https://medium.com/airbnb-engineering/airflow-a-workflow-management-platform-46318b977fd8
Buch zu Apache Airflow: Data Pipelines with Apache Airflow (manning.com) - https://www.manning.com/books/data-pipelines-with-apache-airflow
Seminarempfehlung
Junior Consultant bei ORDIX
Kommentare