
Automatisierte Fehlererkennung auf Basis von Log-Dateien
"Suche nicht nach Fehlern, suche nach Lösungen" (Henry Ford)
Log-Dateien dokumentieren das Verhalten einer Anwendung oder eines Systems. Die Analyse dieser Daten ist damit ein Schlüsselfaktor für die Sicherheit, Stabilität und Nutzbarkeit der Komponenten. In vielen Applikationen beinhalten die Log-Dateien aber auch Fehler oder Warnungen, bei denen explizit kein Handlungsbedarf besteht und die maximal einen informativen Charakter haben. Die hohe Anzahl solcher Meldungen, im Vergleich zur geringen Menge an tatsächlichen Fehlern, führt dazu, dass sich die Analyse oft sehr aufwändig gestalten kann. Diese Problemstellung findet sich auch bei der ORDIX AG wieder. Zu diesem Zweck wurde eine automatisierte Fehlererkennung basierend auf den Log-Dateien implementiert.
Die verwendeten Log-Dateien stammen von einer Microservice-Anwendung zur Synchronisation der Mitarbeiter:innen-Kontakte. Die Anwendung wird allen Mitarbeiter:innen permanent genutzt und synchronisiert für jede:n einzelne:n die Kontaktdaten aller Mitarbeiter:innen.
Log-Parsing
Log-Zeilen bestehen in den meisten Fällen aus zwei Teilen, den Metadaten und der Log-Meldung.

Die Metadaten enthalten gewisse Informationen, wie Datum und Uhrzeit, den Log Level oder auch Informationen zur Klasse oder Funktion, in der die Meldung erzeugt wurde. Dahingegen bestehen Log-Meldungen aus einem konstanten Text und einem oder mehreren variablen Parametern. Um solche Log-Zeilen effizient analysieren zu können, muss ein geeignetes Log-Parsing-Verfahren verwendet werden.
Log-Parsing kann in zwei Bestandteile aufgeteilt werden:
- Das Parsen der gesamten Log-Zeile, zur Trennung von Metadaten und Meldung.
- Das Parsen der Meldung.
Alle Meldungen, die vom gleichen Logging-Aufruf erzeugt wurden, besitzen den gleichen konstanten Text, hier Log-Key genannt.

Ein häufig gewählter Ansatz zur Extrahierung des Log-Keys sind reguläre Ausdrücke, die im Vorfeld manuell definiert werden müssen. Ohne umfangreiches Domain-Wissen können jedoch nicht alle möglichen Muster abgebildet werden.Aufgrund der Tatsache, dass die Meldungen aus freiem Text bestehen, ist es nicht trivial, die Parameter zu identifizieren und somit den Log-Key zu ermitteln. Wenn nicht auf den Sourcecode oder Expert:innenwissen zugegriffen werden kann, sind sowohl Log-Key als auch die Position der Parameter im Text unbekannt. Zudem können die regulären Ausdrücke nur auf die spezifische Applikation angewandt werden, für die sie entwickelt wurden. Um diese Einschränkung zu verhindern, existieren Log-Parsing-Methoden, die auf String-Vergleichen basieren. Eine solche Methode ist der Algorithmus Basic Signature Generation (BSG) [1], der aus drei Schritten besteht:
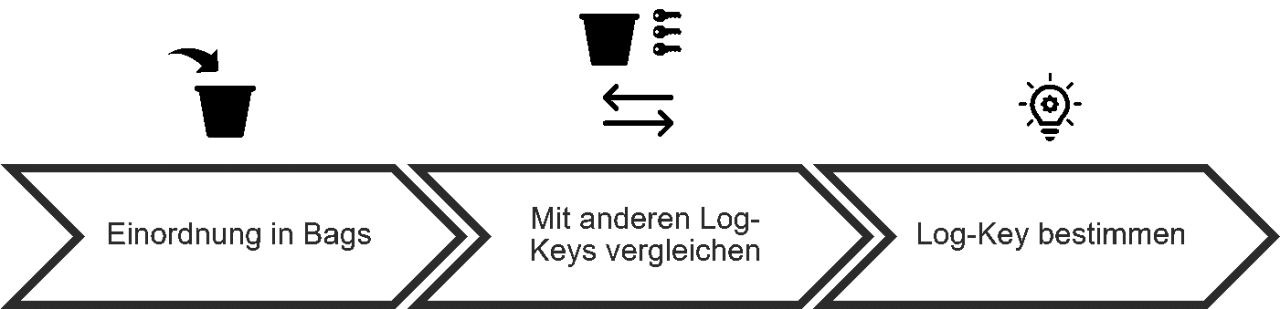
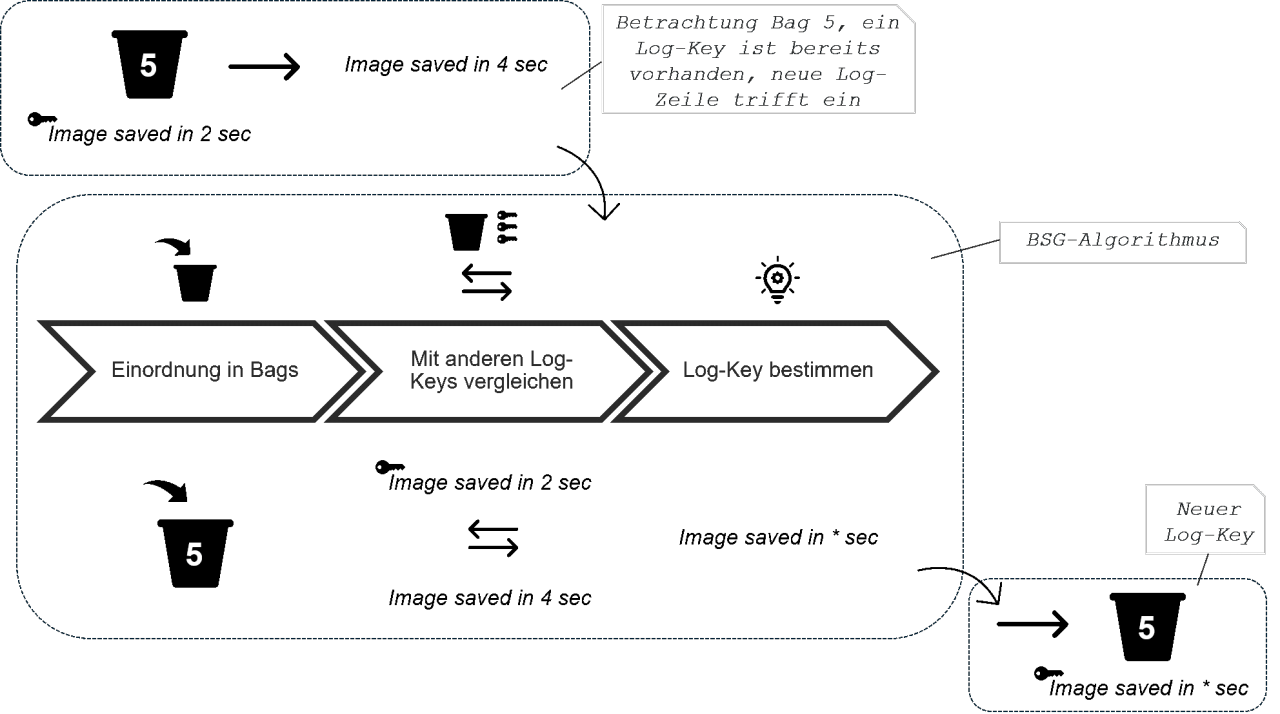
- Einordnung in Bags: Im ersten Schritt werden die Meldungen nach ihrer Länge gruppiert. Alle Meldungen mit der gleichen Anzahl von Wörtern werden in einen sogenannten Bag eingeordnet.
- Vergleich mit anderen Log-Keys: Die Log-Meldungen liegen nun in Bags fester Länge vor, weshalb die Meldungen im nächsten Schritt mittels eines String-Vergleichs basierend auf der Levenshtein-Distanz verglichen werden.
- Bestimmung Log-Key: Wird die Meldung einem bestehenden Log-Key zugeordnet, wird die Zeilen-ID gespeichert und der Log-Key ggf. aktualisiert. Andernfalls wird die Meldung selbst als neuer Log-Key gespeichert.
Zudem ist es möglich zu Beginn des Log Parsings eine Vorverarbeitung basierend auf Expert:innenwissen vorzunehmen, wie beispielsweise das Filtern von IP-Adressen. Der Schritt basiert auf der Annahme, dass einfache reguläre Ausdrücke wenig menschlichen Aufwand erfordern, jedoch große Auswirkungen auf die Qualität des Algorithmus haben können. Dieser Schritt ist jedoch nur optional.
Im Folgenden ist der Ablauf des BSG-Algorithmus nochmal exemplarisch dargestellt:
Automatisierte Fehlererkennung
Mittels der extrahierten Log-Keys kann im nächsten Schritt eine Fehlererkennung erfolgen. Die Problematik kann dabei im Kontext der Anomaliedetektion betrachtet werden, bei der die Fehler der Anwendung Anomalien entsprechen.
Fehlerarten
Grundsätzlich wird zwischen drei verschiedenen Arten von Anomalien unterschieden, die sich auch in der Fehlererkennung der Log-Dateien wiederfinden.

- Punktanomalien: Punktanomalien sind Log-Meldungen, deren Auftreten zu jedem Zeitpunkt einen Fehler darstellt.
- Kollektive Anomalien: Kollektive Anomalien sind Log-Meldungen, die individuell betrachtet keinen Fehler bedeuten, deren Aufkommen zusammen, z.B. ungewöhnlich häufig an einem Tag, auf ein inkorrektes Programmverhalten schließen lässt.
- Kontextuelle Anomalien: Kontextuelle Anomalien sind Log-Meldungen, die zu einem bestimmten Zeitpunkt einen Fehler bedeuten, zu einem anderen Zeitpunkt jedoch als normales Programmverhalten gewertet werden können. Dies können beispielsweise Meldungen sein, die in einem Wartungsfenster von 5:00 bis 6:00 Uhr morgens auftreten dürfen, jedoch nicht außerhalb dieses Zeitraumes.
In den von uns verwendeten Daten lagen nur Punktanomalien und kontextuelle Anomalien vor, weswegen beim Einsatz der Modelle auch nur diese Fehlerarten analysiert werden konnten.
Modelle
Als Modelle zur automatisierten Fehlererkennung kommen unterschiedliche Optionen in Frage, je nach Abhängigkeit des Anwendungsfalls und der Datengrundlage.
Supervised Learning
Beim Supervised Learning stehen für die Log-Dateien umfangreiche Labels zur Verfügung. Das bedeutet, dass alle möglichen Fehlerszenarien in den Trainingsdaten abgedeckt und diese entsprechend markiert sind. Dies geht mit einem hohen manuellen Aufwand einher und erfordert ein umfangreiches Expert:innenwissen.
Semi-Supervised Learning
Beim Ansatz des Semi-Supervised Learnings wird vorausgesetzt, dass alle Log-Zeilen des Trainingsdatensatzes aus einem fehlerfreien Zustand des Systems stammen. Ein Modell wird somit mit dem „Normalzustand" trainiert und kann dadurch „unnormales" Verhalten entdecken.
Unsupervised Learning
Liegen weder Labels vor noch Daten aus einem rein fehlerfreien Zustand, können Verfahren des Unsupervised Learnings zum Einsatz kommen. Ziel dieser Techniken ist es, Strukturen und Muster in den Daten zu erkennen und zu prüfen, welche Datenpunkte von diesen abweichen.
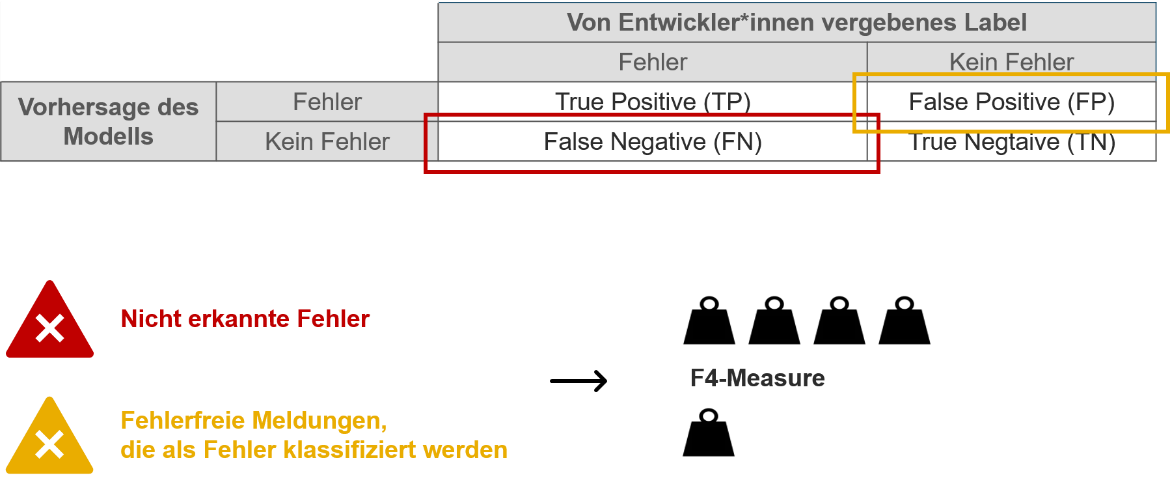
Für den Anwendungsfall der Microservice-Anwendung wurden Modelle aus allen drei Bereichen analysiert. Zum Vergleich der unterschiedlichen Verfahren musste eine geeignete Metrik gewählt werden. Dabei kann ein Modell zwei unterschiedliche Arten von falschen Vorhersagen treffen:
- False Negatives: Obwohl ein Fehler aufgetreten ist, klassifiziert das Modell die Zeile als „Kein Fehler". Diese falsche Modellentscheidung wird als schwerwiegender bewertet, da es vor allem wichtig ist, dass alle aufgetretenen Fehler korrekt identifiziert werden.
- False Positives: In Wahrheit ist kein Fehler aufgetreten, dennoch entscheidet sich das Modell für „Fehler". False Positives sind nicht so schwerwiegend wie False Negatives, dennoch sollte deren Anzahl nicht zu hoch werden, da der Aufwand der daraus resultierenden manuellen Analyse sehr hoch werden würde und das Modell somit unbrauchbar wird.
Um den genannten Anforderungen gerecht zu werden, wird als Metrik zur Modellbewertung der F4-Measure verwendet, der False Negatives stärker gewichtet als False Positives.
Des Weiteren müssen Anforderungen definiert werden, die ein Modell erfüllen muss. Für die Microservice-Anwendung ergab die Anforderungsanalyse folgende Ergebnisse:
- Das Modell muss unabhängig von der Auslastung des Systems sein.
Die Auslastung der Anwendung hängt von der Häufigkeit der Synchronisation ab.Diese variiert auch im Normalzustand, weshalb eine Auslastung des Systems in keinem Zusammenhang mit möglichen Fehlern steht. In anderen Anwendungsfällen kann die Auslastung hingegen eine entscheidende Rolle bei der Fehlererkennung spielen, wie beispielsweise für die Network Intrusion Detection. - Punktanomalien und kontextuelle Anomalien müssen erkannt werden.
Kollektive Anomalien konnten hingegen nicht berücksichtigt werden, da sie, wie bereits beschrieben, in den vorliegenden Daten nicht aufgetreten sind.
Diese Anforderungen gelten speziell für die analysierte Microservice-Anwendung und können nicht auf alle Systeme übertragen werden. Je nach Anwendungsfall muss eine dedizierte Anforderungsanalyse und Modellauswahl erfolgen. Gerne unterstützen wir Sie dabei!
Im Kontext der Microservice-Anwendung konnten insbesondere zwei Modelle alle Anforderungen erfüllen und zudem sehr gute F4-Measure erreichen: Der DecisionTree [2] und ein Long Short-Term Memory (LSTM) [3], eine spezielle Art eines neuronalen Netzes. Der DecisionTree ist ein Verfahren des Supervised Learnings, das LSTM kann hingegen sowohl als Supervised-Modell als auch als Semi-Supervised-Modell zum Einsatz kommen kann. Folgende Ergebnisse wurden erzielt:
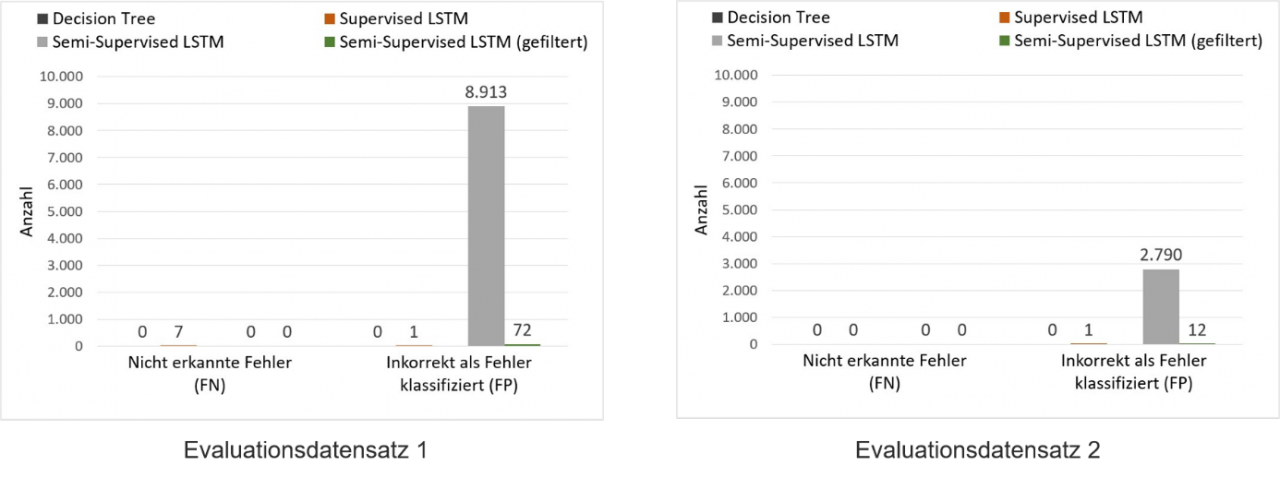
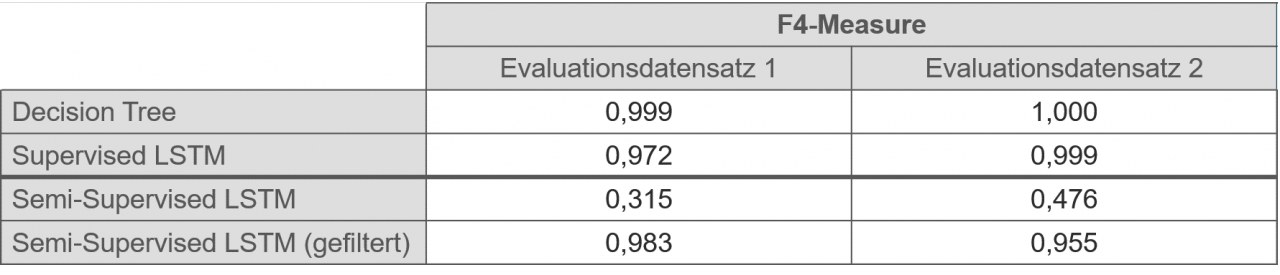
Wie zu sehen ist, hat sich bei den Modellen des Supervised Learnings der initiale Aufwand des Labellings bezahlt gemacht und es konnte ein F4-Measure nahe der 1 erreicht werden. Das Semi-Supervised LSTM konnte hingegen aufgrund der hohen Anzahl False Positives zunächst keinen guten F4-Measure erreichen. Eine manuelle Analyse der Daten hat jedoch gezeigt, dass durch eine einfache Filter-Operation ebenfalls ein sehr guter F4-Measure erreicht werden kann. Dabei wurden die False Positives anhand des Loglevels gefiltert, so dass nur Log-Zeilen vom Typ ERROR oder WARN berücksichtigt wurden. Dies ist möglich, da bei der Microservice-Anwendung nur Zeilen mit diesen Logleveln tatsächlich einen Fehler bedeuten können. Somit konnten sowohl der Decision Tree als auch das Semi-Supervised LSTM auf beiden Evaluationsdatensätzen alle tatsächlich aufgetretenen Fehler korrekt erkennen (keine False Negatives).
Für die Microservice-Anwendung konnten sowohl im Bereich des Supervised als auch des Semi-Supervised Learnings sehr gute Ergebnisse erzielt werden. Für die Supervised-Modelle liegt der Aufwand im initialen Labelling der Log-Zeilen, bei den Semi-Supervised-Modellen in der anschließenden manuellen Analyse. Die Anwendungsfälle von Log-Analyse und automatisierter Fehlererkennung sind vielseitig und umfangreich. Je nach Anforderungen des Systems sind unterschiedliche Modelle geeignet. Gerne beraten wir sie zu den Einsatzmöglichkeiten der automatisierten Fehlererkennung für Ihre Systeme und Anwendungen!
Quellen
[1] Shuting Guo, Zheng Liu, Wenyan Chen und Tao Li. "Event extraction from streaming system logs". In: Lecture Notes in Electrical Engineering. Bd. 514. 2019, S. 465–474. isbn: 9789811310553. doi: 10.1007/978-981-13-1056-0_47.
[2] https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Data Management? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren
Kommentare