
Big Data SQL - Teil 2: Anwendungsbeispiel
Wie im vorherigen Artikel bereits angekündigt liegt der Fokus des zweiten Teils der Blog-Reihe auf der praktischen Umsetzung von Oracle Big Data SQL. Dies erfolgt an einem Anwendungsbeispiel, welches mit möglichst realitätsnahen Daten arbeitet und im Folgenden vorgestellt wird. Es handelt sich hierbei um Blitzerdaten, welche zufällig generiert wurden. Dabei wird sowohl eine Blitzer_ID, der Stadtname und eine Region für einen Blitzer angelegt. „Stadt" sagt aus, an welchem Ort der Blitzer aufgestellt ist und die "Region" beschreibt das jeweilige Bundesland. Die Virtuelle Maschine (VM), die hier für die Umsetzung verwendet wurde, basiert auf der von Oracle bereitgestellten "Oracle Big Data Lite Virtual Machine" in der Version 4.11 (letztes Update Oktober 2018). Die VM dient zur Einarbeitung in Oracle Big Data SQL und kann dementsprechend auch ohne zusätzliche Kosten verwendet und erweitert werden. Dennoch ist zu beachten, dass keine weiteren Updates für die VM verfügbar sind und diese somit ältere Produktversionen enthält. Einen Überblick von der VM sowie den Download finden Sie über diesen Link: https://www.oracle.com/database/technologies/bigdatalite-v411.html#download_bdalite
In der VM wird die Oracle-Version 12cR1 verwendet und beinhaltet Oracle Big Data SQL in der Version 3.2. Es wird die Version 5.13.1 der Cloudera-Distribution von Apache Hadoop verwendet. Einen Überblick der Versionskompatibilitätsmatrix von Big Data SQL zu Oracle Database und Apache Hadoop finden Sie unten in der Skriptsammlung (4.1 Versionskompatibilitätsmatrix).
Da der Fokus dieser Blog-Reihe auf der Vorstellung des Oracle Big-Data-SQL-Produktes liegt, und nicht etwa eine detaillierte Anleitung für ein mögliches Produktivsystem sein soll, wurde das Hadoop-Cluster nicht abgesichert und sämtliche Sicherheitsvorkehrungen ignoriert. Folglich wurden die Schreib- und Leserechte sehr pauschal und großzügig vergeben.
Um das Anwendungsbeispiel vollständig aufzubauen, wurde ein Setup-Skript erstellt, welches sowohl eine neue Datenbank und Tabellen in Hive anlegt als auch alle notwendigen Oracle-Tabellen erstellt und diese mit Daten füllt. Außerdem werden Verzeichnisse angelegt, die für unterschiedliche Oracle-Datenbankobjekte erforderlich sind. Das Skript lässt sich in der Skriptsammlung unter 4.1 Oracle Setup-Skript einsehen.
Für das Anwendungsbeispiel ist eine weitere Komponente notwendig. Dies sind die Oracle Big-Data-Connectoren, welche die Schnittstellen von Oracle und die des Hadoop-Clusters verbindet. Mithilfe der Big-Data-Connectoren können die Daten aus dem Hadoop Cluster in die Oracle-Datenbank überführt werden. Eine detailliertere Beschreibung erfolgt im Laufe des Artikels.
1 Hadoop/Hive
Neben einer existierenden Oracle-Datenbank benötigt das Anwendungsbeispiel ein Hadoop-Cluster mit integriertem Hive. Die Anpassung bzw. das Aufsetzen erfolgt über diverse Skripte, die ebenfalls im Laufe des Artikels vorgestellt werden. Der Aufbau des HDFS besteht darin, Verzeichnisse anzulegen, welche für die spätere Ablage der Rohdaten gedacht sind. Das Skript zur Hive-Datenbank lädt die Rohdaten in die Datenbank.
Durch das Ausführen des HDFS-Setup-Skriptes werden wie erwähnt alle notwendigen Verzeichnisse im HDFS erstellt. Darunter fallen "user/${USER}/dwh" und "user/${USER}/raw". In das /raw-Verzeichnis werden die Rohdaten geladen, die sich vorab lokal auf dem Linux-OS befinden. Die verwendeten Rohdaten stammen aus der Datengenerierung und haben somit keine nähere Bedeutung. Bereinigte Daten werden in das /dwh-Verzeichnis geladen. Sobald die Verzeichnisse im HDFS angelegt wurden, werden diese mit den Beispieldaten gefüllt.
# Erstellen von Verzeichnissen für den aktuellen Benutzer
hdfs_dirs=(dwh raw)
hadoop fs -mkdir -p ${hdfs_dirs[*]}
# Kopieren der Rohdaten von Lokal zum HDFS
# hadoop fs -copyFromLocal <localsrc> <hdfs destination>
hadoop fs -copyFromLocal /home/oracle/bigdata-training /common/src/test/resources/data/raw/blitz raw/
# Kopieren der bereinigten Daten zum HDFS
hadoop fs -copyFromLocal /home/oracle/bigdata-training /common/src/test/resources/data/dwh/blitz dwh/
Das vollständige Skript können Sie in der Skriptsammlung unter „HDFS Setup-Skript" einsehen.
Das Hive-Setup-Skript ist für den Aufbau der in dem Hive Warehouse liegenden Datenbank zuständig. Um dies zu erreichen, werden erst die bereinigten Daten in ein temporäres Verzeichnis kopiert. Dies ist notwendig, damit sich die bereits bereinigten Daten in dem HDFS befinden und somit weiterverarbeitet werden können. In diesem Beispiel ist das "/tmp/bigdata-training/hive-in". Neben der Erstellung neuer Verzeichnisse muss sichergestellt werden, dass diese vom HDFS-Benutzer beschrieben werden können. Dies gilt jedoch spezifisch nur für diese VM. Sollte ein Sicherheitskonzept bestehen, müssen die Berechtigungen dementsprechend angepasst werden. Somit kann anschließend die Blitzer-Datenbank in Hive erstellt und diese mit Daten gefüllt werden.
Kopieren der Blitzerstationsdaten in das temporäre Input-Verzeichnis
hadoop fs -cp 'dwh/blitz/speedometer*' ${tmp_hive_dir}/blitz
# Sicherstellen, dass alle Dateien von allen HDFS Benutzern geschrieben werden können
hadoop fs -chmod -R 777 ${tmp_hive_dir}/blitz
# Erstellen der Blitzer Datenbank und laden aller Daten
rlwrap -a beeline -u jdbc:hive2://localhost:10000/default -n oracle -p welcome1 -f /home/oracle/bigdata-training/common/src/main/hive/create-blitzer_db.hive "$@"
Das vollständige Skript können Sie in der Skript-Sammlung unter „Hive Setup-Skript" einsehen.
Das "Create-User"-Skript wird benötigt, um einen Benutzer zu erstellen, welcher Berechtigungen für das gesamte Oracle Schema erhält. Darunter fallen die Berechtigungen zum Erstellen von Sessions, Tabellen und Views. Außerdem werden weitere Verzeichnisse angelegt, unter anderem für Big Data SQL und für die SQL-Connectoren.
create user blitz identified by welcome1; -- create database directory objects used by NoSQL DB and Oracle SQL Connector -- system privileges required to create external tables -- Oracle SQL Connector for Hadoop create directory blitz_osch_dir as '/home/oracle/ora-directories/blitz/osch /exttab'; grant read, write on directory blitz_osch_dir to blitz;
Das vollständige Skript können Sie in der Skript-Sammlung unter „Create User Skript" einsehen.
Das Skript zum Erstellen des Oracle-Datenbankschemas für den Benutzer "Blitz" ist in der Skript-Sammlung unter „Create Table Skript Oracle" und das Skript zum Erstellen der Hive Tabellen unter "Create Table Skript Hive" zugänglich.
Oracle Big-Data-Connector
Die Oracle Big-Data-Connectoren sind sogenannte Software Suites, um bspw. Apache Hadoop in die Oracle-Datenbank zu integrieren. Sie werden für die Erfassung von Daten und für die Erstverarbeitung verwendet. Für die integrierte Analyse wird eine Verknüpfung zu den in Oracle Database liegenden Daten hergestellt.
Zu den Oracle Big-Data-Connectors zählen unter anderem der „Oracle SQL Connector for Hadoop", „Oracle Loader for Hadoop" und „Oracle DataSource for Hadoop".
Oracle SQL Connector for Hadoop
Der Zugriff auf die Daten in Hadoop erfolgt beim „Oracle SQL Connector for Hadoop" über die Oracle-Datenbank. Es werden externe Oracle-Tabellen verwendet, um Oracle-Datenbanken den Lesezugriff im HDFS auf Hive-Tabellen, Text-Dateien und Data-Pump-Dateien zu ermöglichen. Die externen Tabellen sind Oracle-Datenbankobjekte, die den Speicherort von Daten außerhalb der Oracle-Datenbank angeben. Durch die Abfrage auf die externe Tabelle wird auf Daten zugegriffen, die im HDFS liegen.
Für die Konfiguration des Oracle SQL Connector for Hadoop wird eine XML-Konfigurationsdatei benötigt. Im Anschluss werden alle zu konfigurierenden Eigenschaften in einer Tabelle aufgelistet und beschrieben.
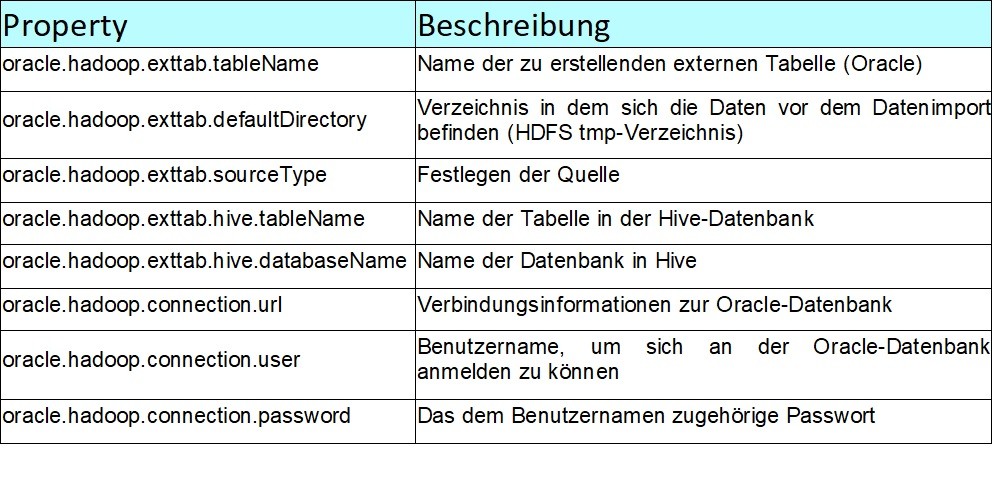
Um dies zu konfigurieren, muss eine XML-Datei angelegt werden. Den Inhalt der XML-Datei können Sie in der Skript-Sammlung unter „Konfigurationsdatei – Oracle SQL Connector for Hadoop" einsehen.
Sofern die Konfiguration der XML-Datei abgeschlossen ist, können nun die Daten in eine externe Oracle-Tabelle geladen werden. Dazu muss folgendes Kommando in der Bash ausgeführt werden:
hadoop jar $OSCH_HOME/jlib/orahdfs.jar oracle.hadoop.exttab.ExternalTable -conf src-oracle/scripts/oracle/osch/osch-config-hive-speedometer.xml -createTable
Anschließend lässt sich im SQL*Plus die externe Tabelle anzeigen:
Select * from blitz.speedometer_osch; +---------------------------------------------+---------------------------------------+------------------------------------------+ | speedometer_osch.meter_id | speedometer_osch.stadt | speedometer_osch.region | +---------------------------------------------+---------------------------------------+------------------------------------------+ | 1111 | Paderborn | NRW | | 1112 | Münster | NRW | | 1113 |Köln | NRW | | 4441 | Frankfurt | Hessen | | 4442 | Marburg | Hessen | | 5551 | Ulm | Baden-Württemberg | +---------------------------------------------+---------------------------------------+------------------------------------------+
Oracle Loader for Hadoop
Der „Oracle Loader for Hadoop" ist ein effizienter und leistungsstarker Loader für schnelle Datenübertragung von Hadoop in eine Oracle-Datenbank. Die Daten können vorpartitioniert und in ein datenbankfähiges Format umgewandelt werden. Die Datensätze können nach Primary Key oder benutzerdefinierten Spalten sortiert werden, bevor das Laden der Daten oder die Erstellung der Ausgabedatei abgeschlossen ist. Der Oracle Loader verwendet das Parallelverarbeitungs-Framework von Hadoop, um Verarbeitungsvorgänge nicht auf dem Datenbankserver ausführen zu müssen. Durch die Auslagerung wird die CPU-Auslastung auf Datenbankserver-Ebene reduziert.
Für die Konfiguration des "Oracle Loader for Hadoop" wird eine XML-Konfigurationsdatei benötigt. Im Anschluss werden alle zu konfigurierenden Eigenschaften in einer Tabelle aufgelistet und beschrieben.
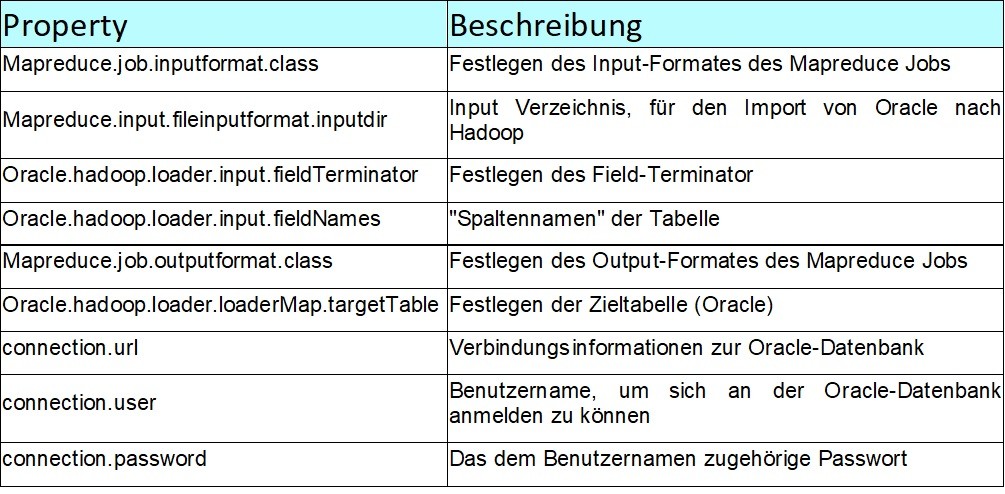
- Delimited Text Input Format
- Complex Text Input Formats
- Hive Table Input Format
- Avro Input Format
- Oracle NoSQL Database Input Format
Um den Oracle "Loader for Hadoop" konfigurieren zu können, muss ebenfalls eine separate XML-Datei erstellt werden. Die Konfiguration können Sie in der Skript-Sammlung unter „Konfigurationsdatei – Oracle Loader for Hadoop" einsehen.
hadoop fs -rm -r tmp/olh_outputdir
Um nun die Daten in eine Oracle-Datenbanktabelle laden zu können, muss folgendes Kommando in der Bash ausgeführt werden:
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader -conf src-oracle/scripts/oracle/olh/olh-config-delimited-blitzer.xml -Dmapreduce.job.reduces=1 -Dmapreduce.output.fileoutputformat.outputdir=tmp/olh_outputdir
An dieser Stelle lässt sich, wie oben bereits angedeutet, die Parallelisierung konfigurieren (-Dmapreduce.job.reduces=1). Je nach zugewiesenem Wert wird die Ausführungszeit eines MapReduce-Jobs halbiert, gedrittelt, etc. In diesem Beispiel hat dies zu keinem signifikanten Unterschied geführt, da es sich lediglich um eine kleine Datenmenge handelt, weshalb der Wert „1" gewählt wurde. Anschließend lässt sich über den SQL*Plus das Ergebnis anzeigen:
Select * from blitz.speedometer_olh; +---------------------------------------------+---------------------------------------+------------------------------------------+ | speedometer_olh.meter_id | speedometer_olh.stadt | speedometer_olh.region | +---------------------------------------------+---------------------------------------+------------------------------------------+ | 1111 | Paderborn | NRW | | 1112 | Münster | NRW | | 1113 |Köln | NRW | | 4441 | Frankfurt | Hessen | | 4442 | Marburg | Hessen | | 5551 | Ulm | Baden-Württemberg | +---------------------------------------------+---------------------------------------+------------------------------------------+
Oracle DataSource for Hadoop
Durch das Anlegen von externen Hive-Tabellen kann mit dem "Oracle DataSource for Hadoop" die Schnittstelle implementiert werden, mit der auf die Daten in einer Oracle-Tabelle zugegriffen werden kann. Es wird der direkte und transparente Zugriff auf Oracle-Tabellen ermöglicht. Außerdem sorgen implementierte Optimierungen für einen schnellen, parallelen, konsistenten und sicheren Zugang auf Stammdaten.
Um aus Hadoop auf die Daten einer bestehenden Oracle-Datenbank zugreifen zu können, muss eine externe Hive Tabelle angelegt werden, die dem Oracle-Schema entspricht. Das notwendige Skript kann in der Skript-Sammlung unter „Create External Hive Table Skript" am Ende dieses Artikels eingesehen werden.
Ausführen lässt sich das SQL-Skript in der Bash über folgendes Kommando:
rlwrap -a beeline -u jdbc:hive2://localhost:10000/default -n oracle -p welcome1 --hivevar schema=climate -f src-oracle/scripts/oracle/od4h/create-od4h-hive-tables.sql "$@"
Sobald das Skript abgeschlossen ist, lassen sich die Daten über die beeline-Shell mit einer SELECT-Anweisung anzeigen.
rlwrap -a beeline -u jdbc:hive2://localhost:10000/default -n oracle -p welcome1 "$@"
use blitz;
select * from speedometer_od4h;
+---------------------------------------------+---------------------------------------+------------------------------------------+
| speedometer_od4h.meter_id | speedometer_od4h.stadt | speedometer_od4h.region |
+---------------------------------------------+---------------------------------------+------------------------------------------+
| 1111 | Paderborn | NRW |
| 1112 | Münster | NRW |
| 1113 |Köln | NRW |
| 4441 | Frankfurt | Hessen |
| 4442 | Marburg | Hessen |
| 5551 | Ulm | Baden-Württemberg |
+---------------------------------------------+---------------------------------------+------------------------------------------+
Apache Sqoop
- Überprüfung der Datenbank, um die Metadaten für die zu importierenden Daten zu sammeln.
- Es wird dem Cluster ein Map-only-Hadoop-Job übergeben.
- Die Datenübertragung erfolgt schließlich unter Verwendung der gesammelten Metadaten. Die importierten Daten werden im HDFS gespeichert, abhängig von der importierten Tabelle.
- Es werden Metadaten gesammelt und anschließend der Datentransfer gestartet.
- Die Daten werden unterteilt und mit individuellen Jobs in die Datenbank verschoben.
sqoop export --connect jdbc:oracle:thin:@localhost:1521:orcl --username blitz --password welcome1 -m1 --fields-terminated-by '\t' --export-dir "dwh/blitz/speedometer/" --table SPEEDOMETER
Import der Daten (Hadoop) über der Bash:
Sqoop import –connect jdbc:oracle:thin:@localhost:1521:orcl –username blitz –password welcome1 –m 1 \ --fields-terminated-by '\t' --table <table_name> --target-dir out/sqoop-*
Zusammenfassung/ Fazit
Zusammengefasst ist der Umgang mit Oracle Big Data SQL unkompliziert und durch die von Oracle bereitgestellte Big Data Lite VM existiert eine einfache Variante, um dieses Produkt kennenzulernen. Sowohl die Oracle-Big-Data-Connectoren als auch Apache Sqoop bieten viele unterschiedliche Möglichkeiten, um Daten zwischen den Technologien zu replizieren. Wie bereits erwähnt, ist die aktuelle Version der VM (Big Data Lite 4.11) bereits veraltet. Das Produkt Oracle Big Data SQL, welches sich in der VM in der Version 3.2 befindet, wird jedoch weiterentwickelt und ist aktuell in der Version 4.1 erhältlich.
Skript-Sammlung
4.1 Versionskompatibilitätsmatrix
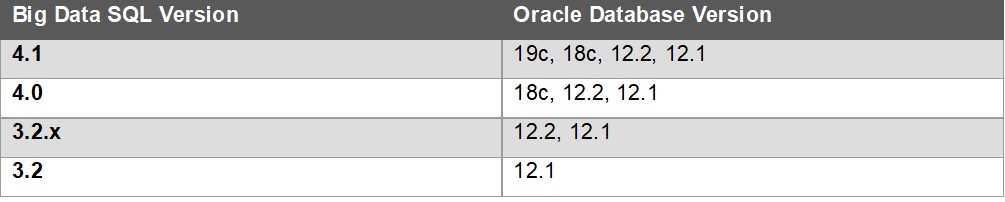
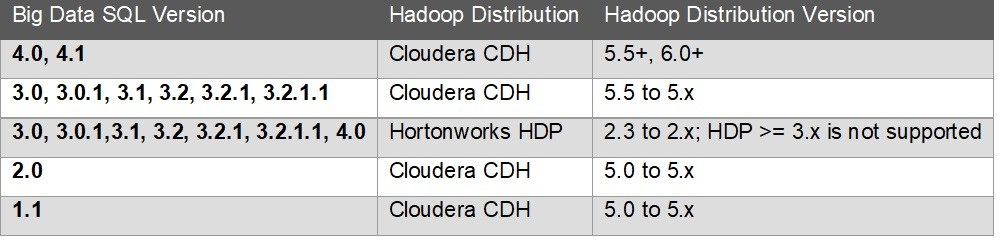
Oracle Setup-Skript
cat setup-oracle.sh
#!/usr/bin/env bash
# get application path (directory, where this script is stored in)
APP_PATH=$(which $0)
APP_PATH=$(dirname ${APP_PATH})
APP_PATH=$(readlink -e "$APP_PATH")
# Setup HDFS and Hive
/home/oracle/bigdata-training/common/bin/setup-hdfs.sh
/home/oracle/bigdata-training/common/bin/setup-hive.sh
# create directories required by Oracle database objects
mkdir -p /home/oracle/ora-directories/blitz/bdsql/default_dir
mkdir -p /home/oracle/ora-directories/blitz/nosqldb/exttab/loc
mkdir -p /home/oracle/ora-directories/blitz/nosqldb/exttab/bin
mkdir -p /home/oracle/ora-directories/blitz/osch/exttab
# Create Oracle User blitz (and directory objects)
echo exit | rlwrap sqlplus system@orcl/welcome1 @/home/oracle/bigdata-training/oracle/src/scripts/oracle/create-user-blitz.sql "$@"
# Create Schema for user blitz
echo exit | rlwrap sqlplus blitz@orcl/welcome1 @/home/oracle/bigdata-training/oracle/src/scripts/oracle/sqoop/create-oracle-tables.sql "$@"
HDFS Setup-Skript
cat /home/oracle/bigdata-training/common/bin/setup-hdfs.sh #!/usr/bin/env bash # Create tmp directory for everyone hadoop fs -mkdir -p /tmp/bigdata-training hadoop fs -chmod -R /tmp/bigdata-training 777 # Create diretories for current user hadoop fs -mkdir -p dwh hadoop fs -mkdir -p raw # Copy raw data from local to HDFS hadoop fs -copyFromLocal /home/oracle/bigdata-training/common/src/test/resources/data/raw/blitz raw/ # Copy cleansed data to HDFS hadoop fs -copyFromLocal /home/oracle/bigdata-training/common/src/test/resources/data/dwh/blitz dwh/
Hive Setup-Skript
cat /home/oracle/bigdata-training/common/bin/setup-hive.sh
#!/usr/bin/env bash
# HDFS tmp-Verzeichnis setzen
tmp_hive_dir=/tmp/bigdata-training/hive-in
# HDFS tmp-Verzeichnis leeren
hadoop fs -rm -r ${tmp_hive_dir}
# Erstellen eines neuen Input-Verzeichnisses für die Hive Daten
hadoop fs -mkdir -p ${tmp_hive_dir}/blitz
# Kopieren der Blitzerstationsdaten in das temporäre Input-Verzeichnis
hadoop fs -cp 'dwh/blitz/speedometer*' ${tmp_hive_dir}/blitz
# Sicherstellen, dass alle Dateien von allen HDFS Benutzern geschrieben werden können
hadoop fs -chmod -R 777 ${tmp_hive_dir}/blitz
# Erstellen der Blitzer Datenbank und laden aller Daten
rlwrap -a beeline -u jdbc:hive2://localhost:10000/default -n oracle -p welcome1 -f /home/oracle/bigdata-training/common/src/main/hive/create-blitzer_db.hive "$@"
Create User Skript
cat /home/oracle/bigdata-training/oracle/src/scripts/oracle/create-user.sql create user blitz identified by welcome1; grant create session to blitz; grant create table to blitz; grant create view to blitz; grant unlimited tablespace to blitz; -- create database directory objects used by NoSQL DB and Oracle SQL Connector -- system privileges required to create external tables -- Oracle SQL Connector for Hadoop create directory blitz_osch_dir as '/home/oracle/ora-directories/blitz/osch/exttab'; grant read, write on directory blitz_osch_dir to blitz; -- OSCH_BIN_PATH exists already (part of the Big Data Lite VM) -- This diretory contains the hdfs_stream script. To create external tables the user blitz needs read and execute privileges for this directory -- OSCH_BIN_PATH = /u01/connectors/osch/bin grant read, execute on directory osch_bin_path to blitz; -- Oracle Big Data SQL create directory blitz_bdsql_default_dir as '/home/oracle/ora-directories/blitz/bdsql/default_dir'; grant read, write on directory blitz_bdsql_default_dir to blitz;
Create Table Skript Oracle
cat /home/oracle/bigdata-training/oracle/src/scripts/oracle/sqoop/create-oracle-tables.sql
create table speedometer (
blitzer_id number(10) not null,
stadt varchar(32),
region varchar(32),
constraint speedom_pk primary Key (blitzer_id)
);
Create Table Skript Hive
cat /home/oracle/bigdata-training/common/src/main/hive/create-blitzer_db.hive create schema if not exists blitz; use blitz; drop table if exists speedometer; create table speedometer (blitzer_id int, stadt string, region string) row format delimited fields terminated by '\t'; load data inpath '/tmp/bigdata-training/hive-in/blitz/speedometer/' into table speedometer; set hive.exec.dynamic.partition = true; set hive.exec.dynamic.partition.mode = nonstrict;
Konfigurationsdatei - Oracle SQL Connector for Hadoop
cat src-oracle/scripts/oracle/osch/osch-config-hive-speedometer.xml
<?xml version="1.0"?>
<!-- Required Properties -->
<configuration>
<property>
<name>oracle.hadoop.exttab.tableName</name>
<value>speedometer_osch</value>
</property>
<property>
<name>oracle.hadoop.exttab.defaultDirectory</name>
<value>blitz_osch_dir</value>
</property>
<property>
<name>oracle.hadoop.exttab.sourceType</name>
<value>hive</value>
</property>
<property>
<name>oracle.hadoop.exttab.hive.tableName</name>
<value>speedometer</value>
</property>
<property>
<name>oracle.hadoop.exttab.hive.databaseName</name>
<value>blitz</value>
</property>
<property>
<name>oracle.hadoop.connection.url</name>
<value>jdbc:oracle:thin:@${HOST}:${TCPPORT}/${SERVICE_NAME}</value> </property>
<property>
<name>TCPPORT</name>
<value>1521</value>
</property>
<property>
<name>HOST</name>
<value>bigdatalite.localdomain</value>
</property>
<property>
<name>SERVICE_NAME</name>
<value>orcl</value>
</property>
<property>
<name>oracle.hadoop.connection.user</name>
<value>BLITZ</value>
</property>
<property>
<name>oracle.hadoop.connection.password</name>
<value>welcome1</value>
<description> A password in clear text is NOT RECOMMENDED. Use an Oracle wallet instead.</description>
</property>
</configuration>
Konfigurationsdatei - Oracle Loader for Hadoop
cat src-oracle/scripts/oracle/olh/olh-config-delimited-blitzer.xml
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<!-- Input settings -->
<property>
<name>mapreduce.job.inputformat.class</name>
<value>oracle.hadoop.loader.lib.input.DelimitedTextInputFormat</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.inputdir</name>
<value>/user/oracle/dwh/blitz/speedometer</value>
</property>
<property>
<name>oracle.hadoop.loader.input.fieldTerminator</name>
<value>\u0009</value>
<description>Using horizontal tabulator as field terminator</description>
</property>
<property>
<name>oracle.hadoop.loader.input.fieldNames</name>
<value>BLITZER_ID,NAME,REGION</value>
</property>
<property>
<name>mapreduce.job.outputformat.class</name>
<value>oracle.hadoop.loader.lib.output.JDBCOutputFormat</value>
</property>
<!-- Target table information -->
<property>
<name>oracle.hadoop.loader.loaderMap.targetTable</name>
<value>speedometer</value>
</property>
<!-- Connection information -->
<property>
<name>oracle.hadoop.loader.connection.url</name>
<value>jdbc:oracle:thin:@${HOST}:${TCPPORT}/${SERVICE_NAME}
</value>
</property>
<property>
<name>TCPPORT</name>
<value>1521</value>
</property>
<property>
<name>HOST</name>
<value>bigdatalite.localdomain</value>
</property>
<property>
<name>SERVICE_NAME</name>
<value>orcl</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.user</name>
<value>BLITZ</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.password</name>
<value>welcome1</value>
<description> A password in clear text is NOT RECOMMENDED. Use an Oracle wallet instead
</description>
</property>
</configuration>
Create External Hive Table Skript
cat src-oracle/scripts/oracle/od4h/create-od4h-hive-tables.sql
use ${hivevar:schema};
DROP TABLE if exists speedometer_od4h;
CREATE EXTERNAL TABLE speedometer_od4h (
blitzer_id int,
stadt string,
region string
)
STORED BY 'oracle.hcat.osh.OracleStorageHandler'
WITH SERDEPROPERTIES (
'oracle.hcat.osh.columns.mapping' = 'blitzer_id,stadt,region')
TBLPROPERTIES (
'mapreduce.jdbc.url' = 'jdbc:oracle:thin:@bigdatalite.localdomain:1521:orcl',
'mapreduce.jdbc.username' = 'blitz',
'mapreduce.jdbc.password' = 'welcome1',
'mapreduce.jdbc.input.table.name' = 'speedometer'
);
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Big Data? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren
Consultant bei ORDIX
Kommentare