
Big Data SQL - Teil 1: Grundlagen
Oftmals wird von RDBMS oder aber von Big-Data-Systemen gesprochen. Es wird sich also je nach Gebrauch nur für eine der Technologien entschieden. Wie aber lassen sich diese beiden Welten miteinander verbinden und wo liegen die Unterschiede? In diesem Artikel wird das von Oracle bereitgestellte Produkt "Big Data SQL" vorgestellt. Dies beinhaltet eine Zusammenfassung der Grundlagen und eine praktische Vorstellung von Big Data SQL anhand eines Anwendungsbeispiels.
Was ist Big Data SQL?
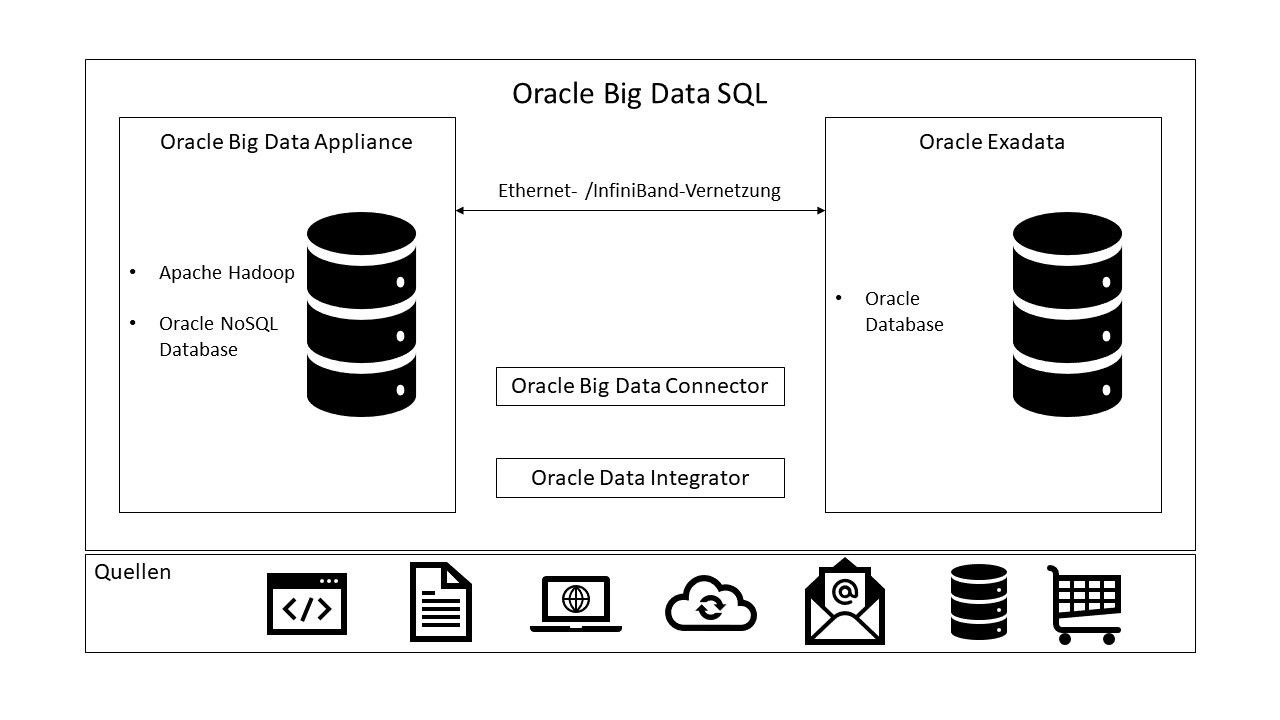
Big Data SQL ist ein Produkt von Oracle, welches die Erweiterung der einfachen SQL-Technologie zu einer sogenannten Crossover-Datenbank-Technologie ermöglicht. Dies ist der Zusammenschluss des herkömmlichen RDBMS mit einem Big-Data-System, wie beispielsweise Hadoop. Oracle Big Data SQL bietet einen nahtlosen Zugang und die intigrierte Datenspeicherung von Oracle Database-, Hadoop- und NoSQL-Quellen. Über Oracle Big Data SQL sind unter anderem alle Sicherheits-Features und die SmartScan-Funktion zugänglich. Es unterstützt Abfragen von nicht-relationalen Daten, die sich in mehreren Big-Data-Quellen befinden. Die Daten, die sich über diverse Datenbanken verteilen, können nahtlos angezeigt und analysiert werden. Somit sind SQL-Abfragen auf beispielsweise Hadoop-Systeme möglich.
SmartScan-Funktion
Die SmartScan-Funktion ist ein Feature der Oracle Exadata Database Machine, welches Spalten- und Prädikatfilterung auf der Speicherebene durchführt, und dies bevor die Abfrageergebnisse zur Datenbankebene zurückgesendet werden. Durch den Verarbeitungsagenten von Big Data SQL auf den DataNodes des Hadoop-Clusters wird die SmartScan-Funktion auf externe Tabellen erweitert. Der Grund dafür ist, dass externe Oracle-Tabellen keine herkömmlichen Indizes besitzen und bei Abfragen normalerweise ein vollständiger Tabellenscan erforderlich ist. Die SmartScan-Funktion als Big-Data-SQL-Komponente dient als abschließender Filterungsdurchlauf. Dieser wird lokal auf dem Hadoop-Server durchgeführt, um sicherzustellen, dass nur die angeforderten Elemente an die Oracle-Datenbank gesendet werden. Dabei verwendet die Implementierung der SmartScan-Funktion die massiv parallele Verarbeitungsleistung des Hadoop-Clusters. Dadurch wird das Filtern der Daten an der Quelle und das Verwerfen von irrelevanten Daten ermöglicht. Vorteile des SmartScans sind zum einen die Minimierung der Datenbewegung und des Netzwerkverkehrs zwischen Cluster und Datenbank und zum anderen das Verkleinern der Ergebnismengen, die an den Oracle-Datenbankserver zurückgegeben werden; abschließend die Aggregation (falls möglich) der Daten. Diese erfolgt, indem die Skalierbarkeit und die Clusterverarbeitung genutzt werden.
Welche Komponenten werden bei einer Oracle-Big-Data-SQL-Installation benötigt?
Die Oracle-Big-Data-SQL-Architektur besteht aus einer Installation auf einem Oracle-Datenbanksystem (single node oder RAC) und einer parallelen Installation auf beispielsweise einem Hadoop-Cluster. Die beiden Systeme werden entweder über das Ethernet oder über InfiniBand vernetzt. Hadoop- und Hive-Clients (auf dem Rechenknoten des Oracle-Datenbanksystems) ermöglichen die Kommunikation zwischen der Datenbank und dem Oracle-Big-Data-SQL-Prozess. Dieser wird auf jeden DataNode des Hadoop-Clients ausgeführt. Durch diesen Mechanismus kann Oracle Database Daten im Hadoop-Cluster abfragen.
Der Big-Data-SQL-Verarbeitungsprozess auf den DataNodes wird von YARN verwaltet und in die Hadoop-Infrastruktur integriert. Die drei Hauptfunktionen, welche von dem Prozess bereitgestellt werden, sind SmartScan, Storage Indexes und Aggregation Offload. Wie sich eine solche Oracle-Big-Data SQL-Installation auf einem System praktisch verhält, erfahren Sie in dem zweiten Teil dieser Blog-Reihe.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Big Data? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren
Consultant bei ORDIX
Kommentare