
Code Coverage – Not a Reliable Quality Measure
One of the typical requirements for new software is a prescribed minimum level of code coverage, i.e., the proportion of the source code that is executed by automated tests. Especially in areas such as medical technology, the automotive industry, or financial systems, 100 % code coverage is often required. But even code that is completely covered by tests is not necessarily error-free. In this article, we learn what is behind the term code coverage and why 100 % coverage can be misleading. We find that combining code coverage with meaningful checks in the tests themselves and additionally including mutation tests is much more robust and desirable for assessing code quality than measuring coverage alone.
Meaning of the term Code Coverage
Code coverage is the percentage of source code that is executed by at least one test. In simple terms, code coverage is calculated using the following formula:
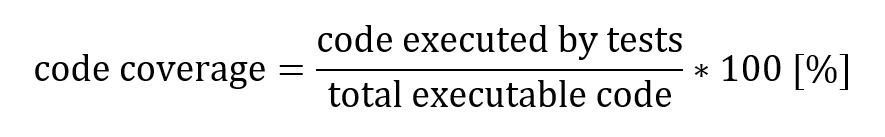
Using built-in tools (see below for examples), developers usually measure code coverage during the execution of unit and integration tests.
Types of code coverage
Function/Method Coverage = Percentage of methods that are called (directly or indirectly) by at least one test.
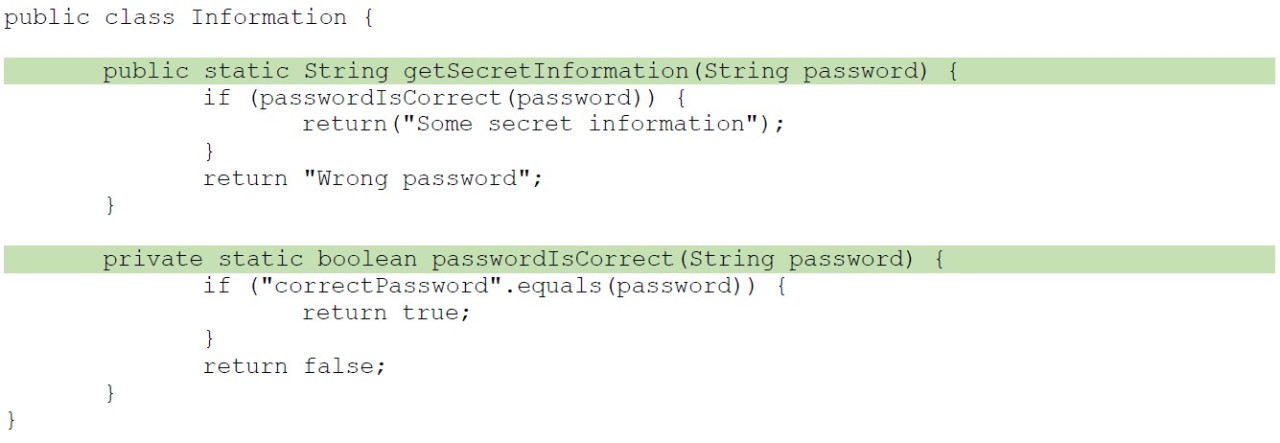
Consider a class with two methods and the associated test class:
public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
}
By having only one unit test, we get a function coverage of 100 %, because the call of the first method occurs directly in the test and the second method is called by the first one.
Line Coverage = Percentage of lines of code in which at least one instruction is called within at least one test.
Consider the above example:

public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
}
We notice that not all lines are covered by the given test. In both methods, the last lines are not touched. We achieve complete coverage by a second test:
public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
@Test
public void testGetSecretInformationWrongPassword() {
String returnValue = Information.getSecretInformation("wrongPassword");
Assertions.assertEquals("Wrong password", returnValue);
}
}
Now we not only have 100 % function coverage, but also 100 % line coverage.

Branch Coverage = The percentage of branches that are run through at least one test. Branches occur as if-clauses, for example, and complete branch coverage can be achieved by running each branch through a test. Thus, in an if-query with a single condition, both the true and false cases must be covered. A loop is considered to be covered if the true and false cases of the termination condition have been met at least once. In the example above, we have already achieved 100 % branch coverage through two tests.
This type of coverage is interesting since it is possible to achieve complete line coverage, but not consider all scenarios of the function flow and thus possibly miss errors. Let's look at the following faulty function:
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null;
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
return winner;
}
}
If we now write a test in which we check the scenario getWinner(2,1), we get the expected result (the winner is Team1) and also complete function and line coverage. However, the branch coverage is only 50% because we only cover one of two branches by the test.

If we now add a second test with the call getWinner(1,2) to cover the second branch, we obviously do not get Team2 as the winner and discover the error.
Path Coverage = The percentage of paths that are passed through at least one test. To make the difference between branch and path coverage clear, let's look at the following example:
public class Greeting {
public static String greeting(boolean hasBirthday, boolean myFriend) {
String message = "Hello."; // 0
if (hasBirthday) { // 1
message += " Happy birthday!"; // 2
}
if (myFriend) { // 3
message += " Have a nice day!"; // 4
}
return message; // 5
}
}
By making the test calls greeting(true, true) and greeting(false, false) we achieve full branch coverage, but the path coverage is only 50 % with this, as we have covered paths 0-1-2-3-4-5 and 0-1-3-5 by this, but not paths 0-1-2-3-5 (which would be the call greeting(true, false)) and 0-1-3-4-5 (call greeting(false, true)).
Loops quickly produce an extremely high (possibly even an infinite) number of paths, all of which would have to be covered by tests in order to achieve 100 % path coverage. Therefore, somewhat weakened versions of path coverage are often determined by reducing the number of required covered paths to a certain number.
There are numerous other types of code coverage (loop coverage, statement coverage, parameter value coverage…), but in practice it is mainly line and branch coverage that are used as metrics.
High coverage does not indicate high quality
Even 100% code coverage (of whatever kind) does not guarantee error-free code. Let's take another look at the SoccerMatch class. To achieve complete branch coverage, we wrote two different unit tests and tested the scenarios “Team1 wins” and “Team2 wins”. The second scenario in the original version did not give the expected result. Suppose we changed the function as follows:
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
else {
winner = "Team2";
}
return winner;
}
}
Now the tests with the calls getWinner(2,1) and getWinner(1,2) each deliver the expected result and 100 % branch coverage is also achieved. Everything great? Well, only for Team2, because when calling getWinner(1,1) we would find that in case of a tie the second team celebrates the victory, so our method is not error-free despite coverage. Only after the following adjustment …
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
else if (goalsTeam1 < goalsTeam2) {
winner = "Team2";
}
return(winner);
}
}
… the method does become error-free and, as expected, returns null in the test call of getWinner(1,1). However, the method could be upgraded by excluding the negative inputs.
It is also important to keep in mind that only the respective calls within the tests are decisive for the coverage, the existence of assertions is irrelevant for the calculation, because this only considers the calls of the code places. Thus, it is possible to obtain 100 % code coverage and not check the behavior of the program in any way.
The following erroneous method …
public class Access {
public static String getAccessMessage(boolean denied) {
String message = "Access allowed";
if (denied) {
message.replace("allowed", "denied");
}
return message;
}
}
… can be fully covered by the following tests:
public class AccessTest {
@Test
public void testAccessAllowed() {
String message = getAccessMessage(false);
}
@Test
public void testAccessDenied() {
String message = getAccessMessage(true);
}
}
But only by correct assertions, i.e., by checking whether the message actually has the expected content, we will find out that in the true case (i.e., in the second test) the message is not “Access denied”. So if we extend the tests with meaningful checks of the return, we find that the second test fails.
public class AccessTest {
@Test
public void testAccessAllowed() {
String message = getAccessMessage(false);
Assertions.assertEquals("Access allowed", message);
}
@Test
public void testAccessDenied() {
String message = getAccessMessage(true);
Assertions.assertEquals("Access denied", message);
}
}
The correct implementation of the above method is as follows:
public class Access {
public static String getAccessMessage(boolean denied) {
String message = "Access allowed";
if (denied) {
message = message.replace("allowed", "denied");
}
return message;
}
}
Computation of code coverage
Many common IDEs offer tools that can measure and display the code coverage, e.g. JaCoCo for Java or coverage.py for Python. The coverage is determined during the test run and then displayed in the form of a coverage report. Often, the tools offer the possibility to specify which type of coverage should be calculated or to exclude certain parts of the program from the calculation (for example, test classes or automatically generated Getter/Setter).
Conclusion
Code coverage offers software developers a good orientation for the creation of tests and points out places in the source code that may not be sufficiently covered by tests, may even be unreachable and thus require refactoring.
A high level of code coverage, on the other hand, gives the impression of carefully tested software and thus seems to indicate a low probability of errors.
In practice, however, a high degree of coverage alone does not guarantee the high quality of the tests and of the software. Even if a test does not contain any assertions (and thus does not check the functionality of the called methods), such a test still ensures code coverage. A high degree of coverage also encourages the writing of tests that are not very meaningful or even superfluous, and costs time and money unnecessarily.
It has been shown that a code coverage of 60-80% is actually a good guideline, and that it is much more important to make sure that this number does not drop during further development. In addition, the available tests must not only cover the code, but also contain meaningful assertions and check the behavior of the called methods according to the set requirements, so that one can make a reasonable statement about the quality of the tests and the software. Furthermore, mutation tests provide an additional support to measure the quality of the automated tests. The importance and use of mutation tests is described in this blog post (written in German).
Consultant bei ORDIX
Kommentare