
Data Governance #03 – A Beautiful Mind, ähm Data Domain: Strukturen brauchen die Daten 2/2
Zur Klärung der zentralen Begriffe haben wir ein Glossar zur Beitragsreihe Data Governance für Sie eingerichtet.
Im zweiten Teil unserer Blogreihe haben wir untersucht, was eine Data Domain ist und welche Herausforderungen bei der Erstellung einer solchen Struktur auftreten können. Nun gehen wir einen Schritt weiter und zeigen, wie Data Domains mit einem Data Catalog zusammengeführt werden können. In einer Welt, die zunehmend datengetrieben agiert, wird der Umgang mit Metadaten immer wichtiger. Unternehmen müssen nicht nur sicherstellen, dass ihre Daten korrekt, zugänglich und qualitativ hochwertig sind, sondern auch die dazugehörigen Metadaten effizient verwalten – diese beschreiben, wie, wann und warum die Daten erstellt und genutzt werden.
Ein zentraler Bestandteil jeder erfolgreichen Data Governance-Strategie ist daher der Aufbau eines Data Catalogs. Anhand der MySQL sakila-Datenbank, die das Geschäftsmodell unseres fiktiven Unternehmens „Blockbuster Bytes AG" abbildet, zeigen wir, wie ein solcher Catalog genutzt werden kann, um Metadaten, Zugriffsrechte und Datenqualität effektiv zu verwalten und in ein praktisches Data Governance Framework zu integrieren.
Was ist ein Data Catalog und warum ist er wichtig?
Ein Data Catalog ist ein strukturiertes Repository, in dem Metadaten zu den Datenbeständen eines Unternehmens erfasst und verwaltet werden. Diese Metadaten geben Auskunft darüber, was die Daten bedeuten, wo sie gespeichert sind, wie sie verwendet werden und wer Zugriff darauf hat. Der Data Catalog spielt eine entscheidende Rolle in der Data Governance, da er hilft, Transparenz zu schaffen und die Datenqualität zu sichern.
Ein Data Catalog erleichtert den Zugriff auf Daten, indem er eine Übersicht darüber bietet, welche Daten vorhanden sind, wie sie strukturiert sind und wie sie abgerufen werden können. Besonders in großen Organisationen mit vielen verschiedenen Datensätzen ist dies entscheidend, um den Überblick zu behalten und sicherzustellen, dass alle Stakeholder auf dieselben Daten zugreifen können, ohne dass Missverständnisse oder Fehler entstehen.
Ein Data Catalog lässt sich mit einem Katalog in einem Online-Shop wie Amazon vergleichen. Genau wie ein Amazon-Katalog Informationen über Produkte enthält — zum Beispiel den Namen, die Beschreibung, den Preis, die Verfügbarkeit und den/die Verkäufer:in — enthält ein Data Catalog Metadaten über die Datenbestände eines Unternehmens. Diese Metadaten beinhalten Informationen darüber, was die Daten repräsentieren (z. B. Kundendaten, Verkaufszahlen), wo sie gespeichert sind (z. B. in einer Datenbank oder einem Data Warehouse), wie sie verwendet werden können (z. B. für Analysezwecke oder Berichterstattung) und wer Zugriff darauf hat (z. B. bestimmte Teams oder Abteilungen).
Während ein Amazon-Katalog den Nutzenden hilft, Produkte zu finden, zu verstehen und zu kaufen, hilft ein Data Catalog den Nutzenden (wie Datenanalyst:innen, Data Stewards oder Business-Teams) dabei, die relevanten Daten schnell zu finden, zu verstehen und korrekt zu nutzen, wobei Transparenz und Zugriffsrechte eine zentrale Rolle spielen.
In unserem Beispiel ist die „Datenwelt" natürlich nicht sehr komplex. Aktuell befinden sich alle relevanten Daten in einer einzigen Datenquelle, der MySQL-Datenbank „sakila". Aber stellen Sie sich vor, wie viel effizienter und leistungsfähiger ein solcher Daten-Katalog sein könnte, wenn er mit mehreren hundert Datenquellen verbunden wäre. Diese Quellen könnten nicht nur relationale Datenbanken wie MySQL, sondern auch Data Lakes oder Data Warehouses umfassen. Ähnlich wie ein umfangreicher Online-Shop, der Tausende von Produkten aus verschiedenen Kategorien an einem zentralen Ort vereint, ermöglicht ein gut strukturierter Data Catalog den Nutzer:innen, alle verfügbaren Datenquellen schnell zu durchsuchen, zu verstehen und zu nutzen. Dies schafft nicht nur Transparenz, sondern verbessert auch die Effizienz und die Qualität der Datenanalyse in einer komplexen, datengestützten Umgebung.
Um keine Missverständnisse aufkommen zu lassen: Es geht hierbei ausschließlich um die Transparenz der Datenstrukturen – also darum, dass klar ersichtlich ist, welche Daten existieren, woher sie kommen und welche Qualität sie besitzen. Der Data Catalog dient nicht dazu, den direkten Zugriff auf die Daten zu ermöglichen oder zu verbessern, sondern vielmehr dazu, die Metadaten zu verwalten und den Überblick über die Datenbestände zu behalten. Ähnlich wie in einem Online-Shop, der eine Übersicht über alle Produkte bietet, ohne dass man direkt auf die Waren zugreift, geht es beim Data Catalog vor allem darum, den Nutzenden die nötige Transparenz und das Verständnis über die vorhandenen Daten zu vermitteln. So können sie informierte Entscheidungen treffen, welche Daten perspektivisch genutzt werden, ohne dass der Zugriff auf die Daten selbst im Vordergrund steht. Natürlich gibt es auch Softwarelösungen (Data Catalogs), welche auch beim Zugriff auf Daten über integrierte Prozesse unterstützen können.
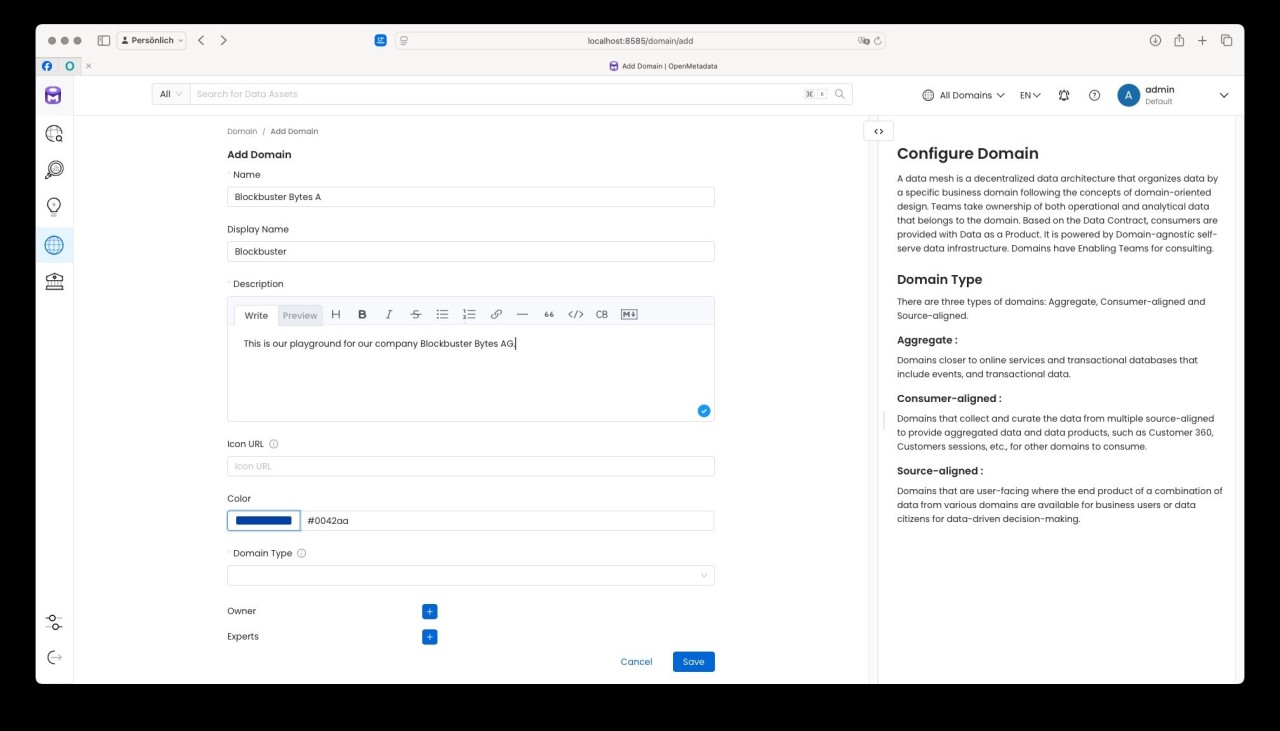
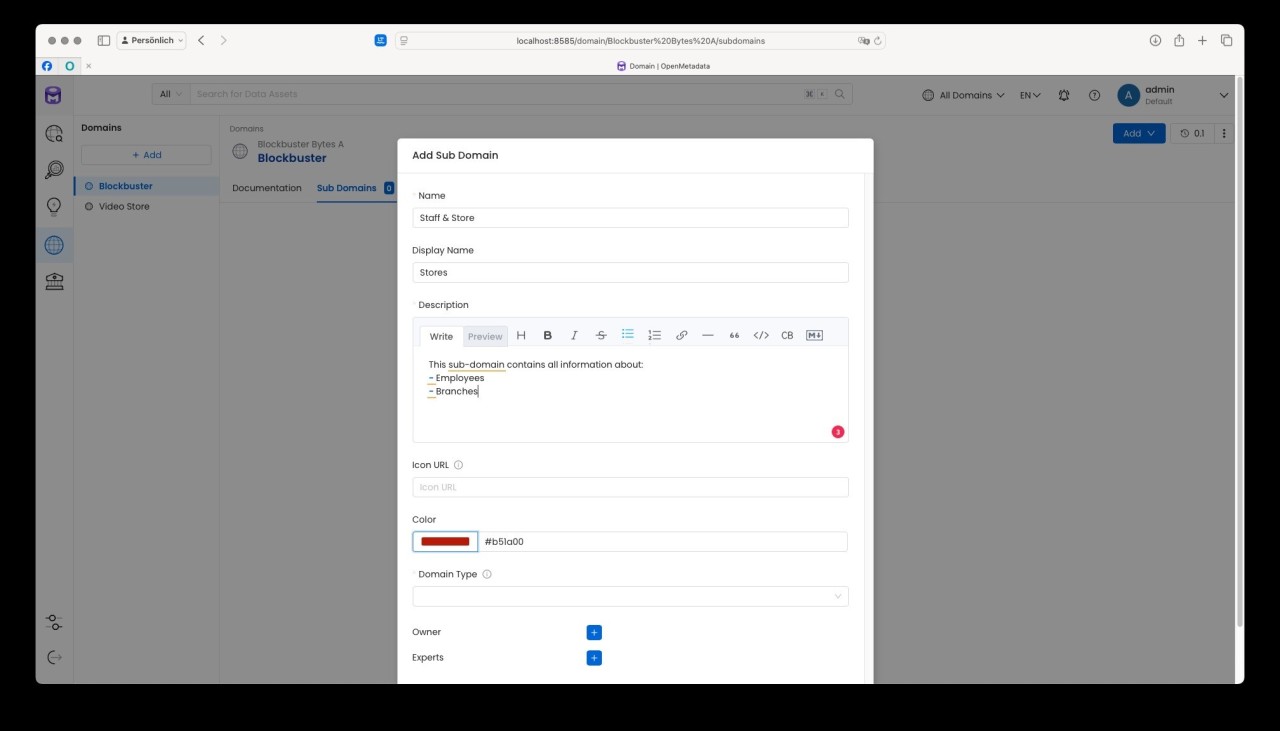
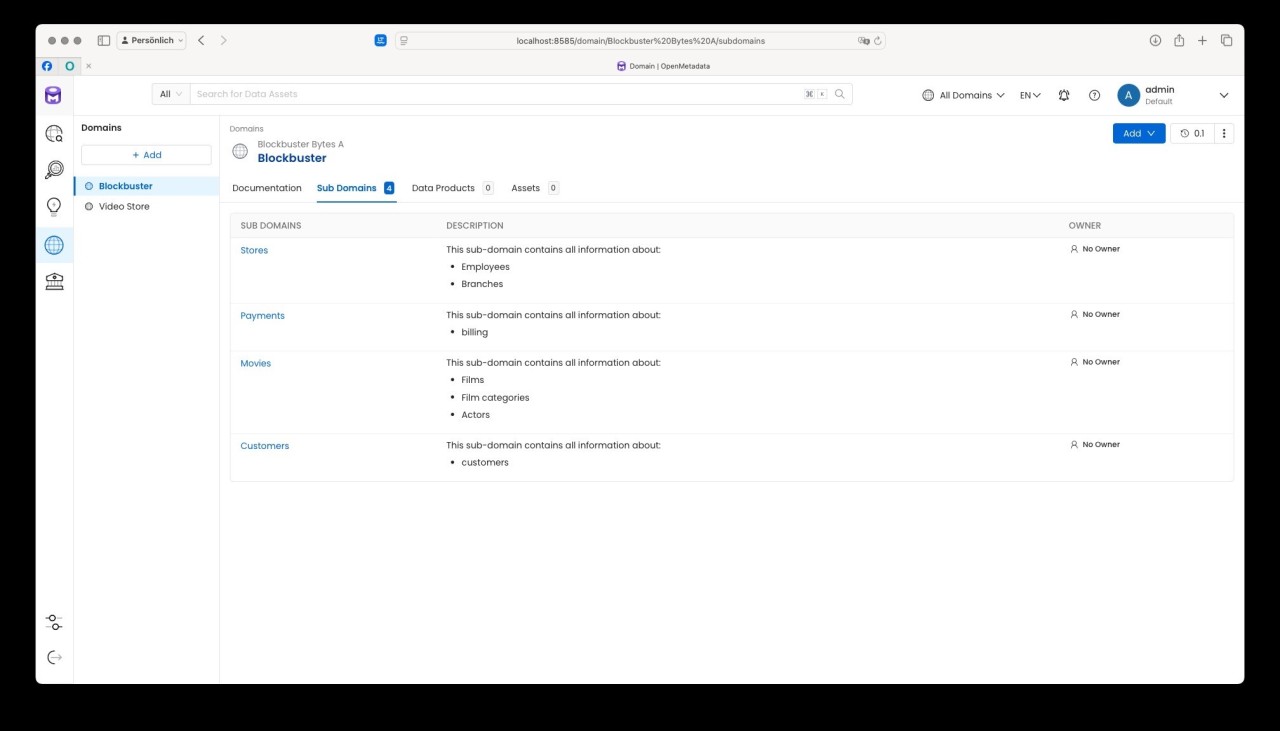
Für unser Beispiel haben wir in OpenMetaData eine Domaine „Blockbuster" mit den vier Sub-Domains
- Stores
- Payments
- Movies
- Customers
erzeugt:
Metadaten in der Data Governance: Verwaltung und Herausforderungen
Metadaten sind die Daten, die die Struktur, Bedeutung und Nutzung anderer Daten beschreiben. Sie bieten Kontext und Informationen, die es den Benutzer:innen ermöglichen, die Daten zu verstehen und korrekt zu verwenden. Die Verwaltung von Metadaten ist eine der zentralen Herausforderungen der Data Governance. Metadaten müssen kontinuierlich gepflegt und aktualisiert werden, um sicherzustellen, dass sie mit den zugrunde liegenden Daten synchron bleiben.
Ein häufiges Problem in Unternehmen ist die Fragmentierung der Metadaten. Unterschiedliche Abteilungen und Systeme erfassen Metadaten auf unterschiedliche Weise, was zu Inkonsistenzen und Verwirrung führt. Hier kommt ein Data Catalog ins Spiel, der eine zentrale, einheitliche Quelle für alle Metadaten bietet und dabei hilft, diese Inkonsistenzen zu vermeiden.
Was sind eigentlich Metadaten?
Metadaten bieten wichtige Kontextinformationen zu den eigentlichen Daten und sind unerlässlich für eine effektive Datenverwaltung.
Datenbeschreibung: Beschreibt, was die Daten bedeuten und was sie repräsentieren. Zum Beispiel: „Kundennummer" in einer Tabelle könnte durch Metadaten beschrieben werden als: „Eindeutige Identifikation für jeden Kunden."
Datenformat: Gibt das Format der Daten an, z. B. ob es sich um Text, Ganzzahlen, Dezimalzahlen, Datum oder Uhrzeit handelt. Beispiel: „Bestelldatum" könnte im Format „YYYY-MM-DD" vorliegen.
Datenquelle: Beschreibt, woher die Daten stammen, z. B. die Herkunft einer Tabelle oder einer externen API. Beispiel: „Kundendaten stammen aus dem CRM-System."
Datenherkunft (Data Lineage): Verfolgt die Herkunft und den Lebenszyklus der Daten – von der Quelle über Transformationen bis zur endgültigen Speicherung. Beispiel: „Kundendaten wurden aus dem Salesforce-CRM in die Datenbank importiert."
Datenstruktur: Beschreibt die Struktur der Daten, wie Tabellen, Spalten, Datentypen und Beziehungen zwischen den Tabellen. Beispiel: „Die Tabelle 'Mitarbeiter' hat die Spalten 'MitarbeiterID', 'Name', 'Abteilung' und 'Einstellungsdatum'."
Zugriffsrechte: Definiert, wer auf bestimmte Daten zugreifen kann. Beispiel: „Nur autorisierte HR-Mitarbeitende dürfen auf die Gehaltsinformationen zugreifen."
Datenqualität: Metadaten, die die Qualität der Daten angeben, z. B. Vollständigkeit, Genauigkeit und Konsistenz. Beispiel: „Die Tabelle 'Bestellungen' hat eine 98%-ige Vervollständigung der Lieferadressen."
Datenaktualität: Gibt an, wie aktuell die Daten sind oder wann sie zuletzt aktualisiert wurden. Beispiel: „Die Kundendaten wurden zuletzt am 1. Dezember 2024 aktualisiert."
Verwendungszweck: Beschreibt, zu welchem Zweck oder in welchem Kontext die Daten verwendet werden. Beispiel: „Die Verkaufszahlen werden verwendet, um Monatsberichte zu erstellen."
Datenklassifizierung: Kategorisiert die Daten basierend auf ihrer Sensibilität, z. B. vertrauliche, öffentlich zugängliche oder interne Daten. Beispiel: „Die Mitarbeiteradresse ist als vertrauliche Information klassifiziert."
Metadaten sind entscheidend für die Verwaltung und Nutzung von Daten, insbesondere in großen, komplexen Datenumgebungen, da sie den Benutzer:innen helfen, die Daten besser zu verstehen, ihre Qualität zu beurteilen und den richtigen Umgang mit ihnen sicherzustellen.
Wie funktioniert dies in der Praxis?
In unserem Beispiel möchten wir die Tabelle „customer" mit Metadaten anreichern und untersuchen, wie diese in OpenMetadata dargestellt werden. Nehmen Sie sich ein paar Sekunden Zeit, um die verfügbaren Meta-Informationen zur Tabelle und deren Attributen (Spalten) zu entdecken.
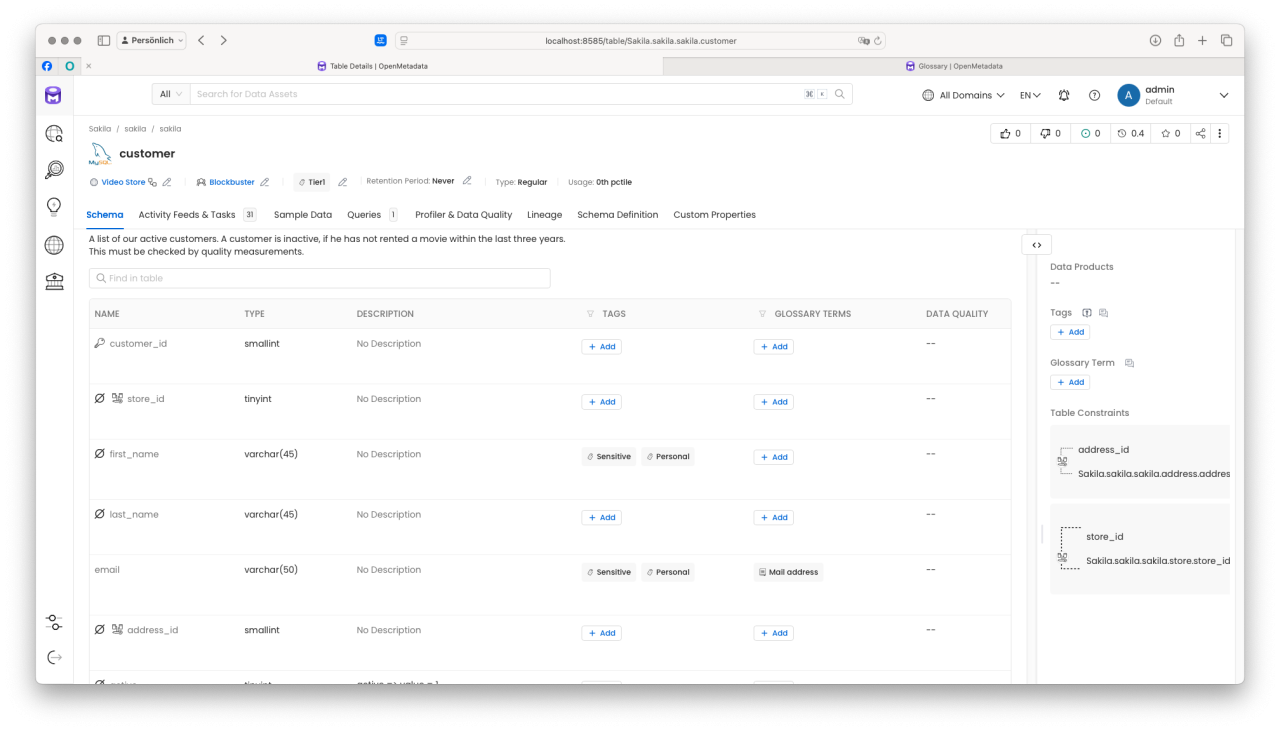
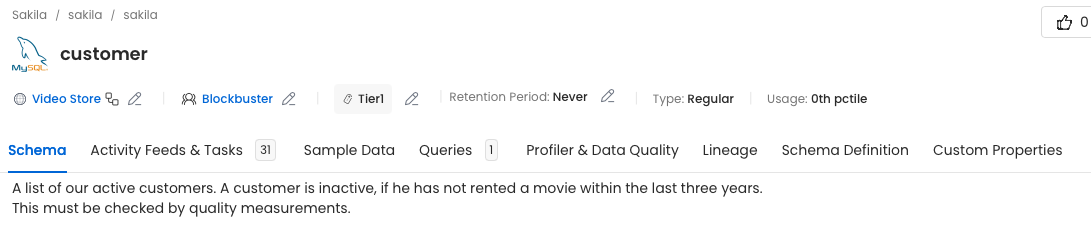
Bereits in diesem Abschnitt können wir folgende interessante Details erkennen:
- Beschreibung der Tabelle: Die Tabelle enthält eine Beschreibung, die potenziellen Datennutzer:innen (wie dem KI-Team) hilft, relevante Daten zu identifizieren. Dies ist besonders nützlich, wenn Entitäten (Tabellen oder Spalten) weniger aussagekräftige Namen haben.
- Zugehörigkeit zu einer Domain: Wir sehen, dass die Tabelle der Domain „Video Store" zugeordnet ist und vom Team „Blockbuster" verwaltet wird. Dies schafft Klarheit darüber, wer die Daten verantwortet.
- Retention Period (Datenaufbewahrung): Es ist gekennzeichnet, dass die Daten keinem Verfallsdatum unterliegen und somit nicht regelmäßig gelöscht oder bereinigt werden müssen. Dies könnte beispielsweise im Kontext der DSGVO auf eine anlassbezogene Datenhaltung hinweisen.
- Markierung und Tagging von Attributen: Bestimmte Spalten, wie „email", sind mit Tags und Labels versehen. Die Spalte ist auch unter alternativen Bezeichnungen wie „Mail address" auffindbar. Zusätzlich sind die Daten als „persönliche" und „sensitive" Informationen gekennzeichnet, was ihre besondere Behandlung verdeutlicht.
Das Tool unterstützt die Beteiligten zudem aktiv bei der Pflege und Beschreibung der Metadaten. Dabei können auch Fehler entdeckt werden: In unserem Fall fehlt bei der Spalte „last_name" noch die Klassifizierung als „vertraulich/sensibel". Gehen wir davon aus, dass wir uns intern auf Standards verständigt haben. Beispielsweise könnte festgelegt sein, dass Nachnamen unter verschiedenen Bezeichnungen auffindbar sein sollen (z. B. lastname, surname) und dass ihre Vertraulichkeit explizit gekennzeichnet wird.
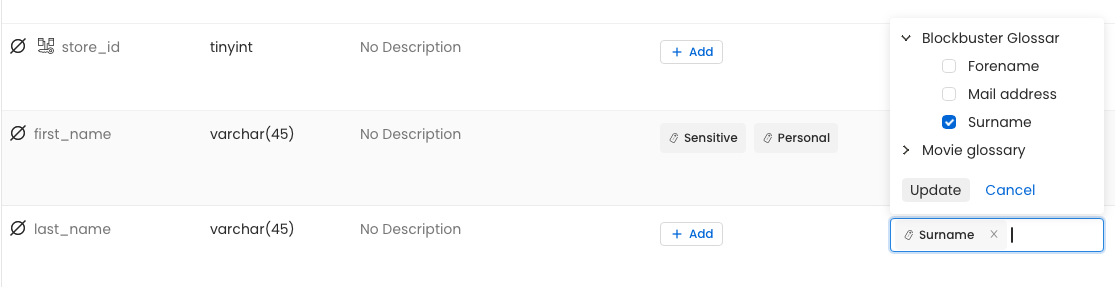
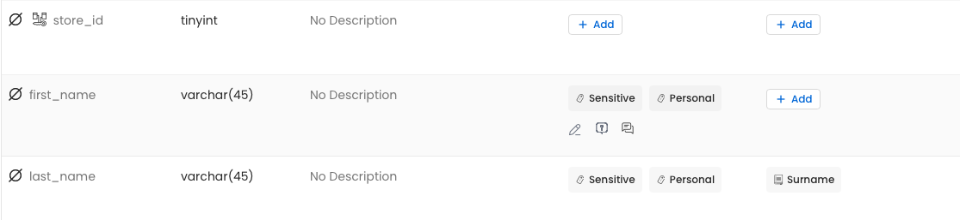
Durch die Ergänzung eines Alias wird die Spalte „last_name" nun unter alternativen Bezeichnungen auffindbar und parallel als „sensitive" sowie „vertraulich/personal data" markiert. Diese zusätzlichen Metadaten haben nicht nur einen beschreibenden Charakter, sondern können auch aktiv weiterverwendet werden – beispielsweise bei der Zugriffssteuerung oder bei der Entscheidung, ob bestimmte Daten verschlüsselt gespeichert werden müssen.
Fazit
Der Aufbau und die Pflege eines Data Catalogs ist ein essenzieller Bestandteil moderner Data Governance und bietet enorme Vorteile für Unternehmen, die in einer zunehmend datengetriebenen Welt agieren. Ein gut strukturierter Data Catalog schafft Transparenz über vorhandene Datenquellen und ermöglicht es, Metadaten wie Herkunft, Struktur, Vertraulichkeit und Verwendungszwecke zentral zu verwalten.
Das in diesem Beitrag beschriebene Beispiel mit der MySQL-Datenbank sakila verdeutlicht, wie Metadaten durch Tools wie OpenMetadata sinnvoll angereichert und genutzt werden können. Ob durch die Zuordnung von Domains, das Tagging sensibler Daten oder die Definition von Aliassen – der Data Catalog hilft nicht nur dabei, Daten leicht auffindbar zu machen, sondern legt auch die Grundlage für regulatorische Compliance und die Verbesserung der Datenqualität.
Dieses Beispiel zeigt auch, wie wichtig die kontinuierliche Pflege und Aktualisierung von Metadaten ist. Standards, Glossare und klare Verantwortlichkeiten tragen dazu bei, dass die Qualität und Konsistenz der Metadaten gewährleistet bleibt. Die Praxis der Metadatenverwaltung zeigt deutlich, wie eine strukturierte Herangehensweise nicht nur den operativen Umgang mit Daten verbessert, sondern auch strategische Entscheidungen im Unternehmen unterstützt.
Zusammenfassend lässt sich sagen, dass ein Data Catalog Unternehmen nicht nur dabei unterstützt, ihre Datenlandschaft besser zu verstehen, sondern auch einen erheblichen Beitrag zur Effizienz, Sicherheit und Transparenz in datengetriebenen Prozessen leistet.
P.S. A Beautiful Mind (2001); https://www.imdb.com/title/tt0268978/mediaviewer/rm955373313/?ref_=tt_ov_m_sm
Seminarempfehlungen
MYSQL ADMINISTRATION DB-MY-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenIT-ORGANISATION UND IT-GOVERNANCE - OPTIMIERUNG IHRER IT-ORGANISATION PM-28
Mehr erfahrenPrincipal Consultant bei ORDIX
Kommentare