
Data Governance #13 – Ex Machina – Wenn Metadaten mittels KI sprechen lernen
Data Governance trifft auf KI: Wie Datenkataloge mit MCP und LLMs die Grenzen zwischen Mensch und Maschine neu definieren
Zur Klärung der zentralen Begriffe haben wir ein Glossar zur Beitragsreihe Data Governance für Sie eingerichtet.
09.01.2026: Update zum LM Studio & OpenMetadata Workflow
In der ersten Version dieses Beitrags hatte ich erwähnt, dass das direkte Patchen von Informationen über LM Studio noch nicht funktionierte. Um Daten in den Catalog zu synchronisieren, war damals ein API-Call über ein Shell-Skript notwendig. Mittlerweile gibt es neue Versionen, die den Prozess deutlich vereinfachen:
- LM Studio 0.3.36
- OpenMetadata Server 1.11.4
In dieser Kombination funktioniert nun auch die patch_entity-Funktion problemlos. Ein kurzes Beispiel folgt gleich.
RAG: Mehr Qualität für mein LLM
Um meinem in LM Studio eingesetzten LLM (openai/gpt-oss-20b) mehr Informationen über die Sakila-Datenbank bereitzustellen, habe ich einen PDF-MCP-Container eingerichtet. Dieser Container bezieht seine Daten aus zwei MySQL-Dokumentationen (im PDF-Format):
- Allgemeine MySQL-Server-Dokumentation
- Beschreibung der Sakila-Datenbank
Das Setup bestand aus zwei Schritten:
- Start eines Containers
docker run -i --rm -v /Users/mj/mysql/:/pdfs mcp/pdf-reader - Erweitern der MCP-Konfiguration von LM Studio
{
"mcpServers": {
"openmetadata": {
"url": " http://localhost:8585/mcp",
"headers": {
"Authorization": "Bearer eyJraWQi…Q"
}
},
"pdf-reader": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-v",
"/Users/mj/mysql/:/pdfs",
"mcp/pdf-reader"
]
}
}
}
Dieses Setup ermöglicht es uns, die Tabellen der Sakila-Datenbank umfassender zu beschreiben und fehlende Informationen gezielt zu ergänzen.
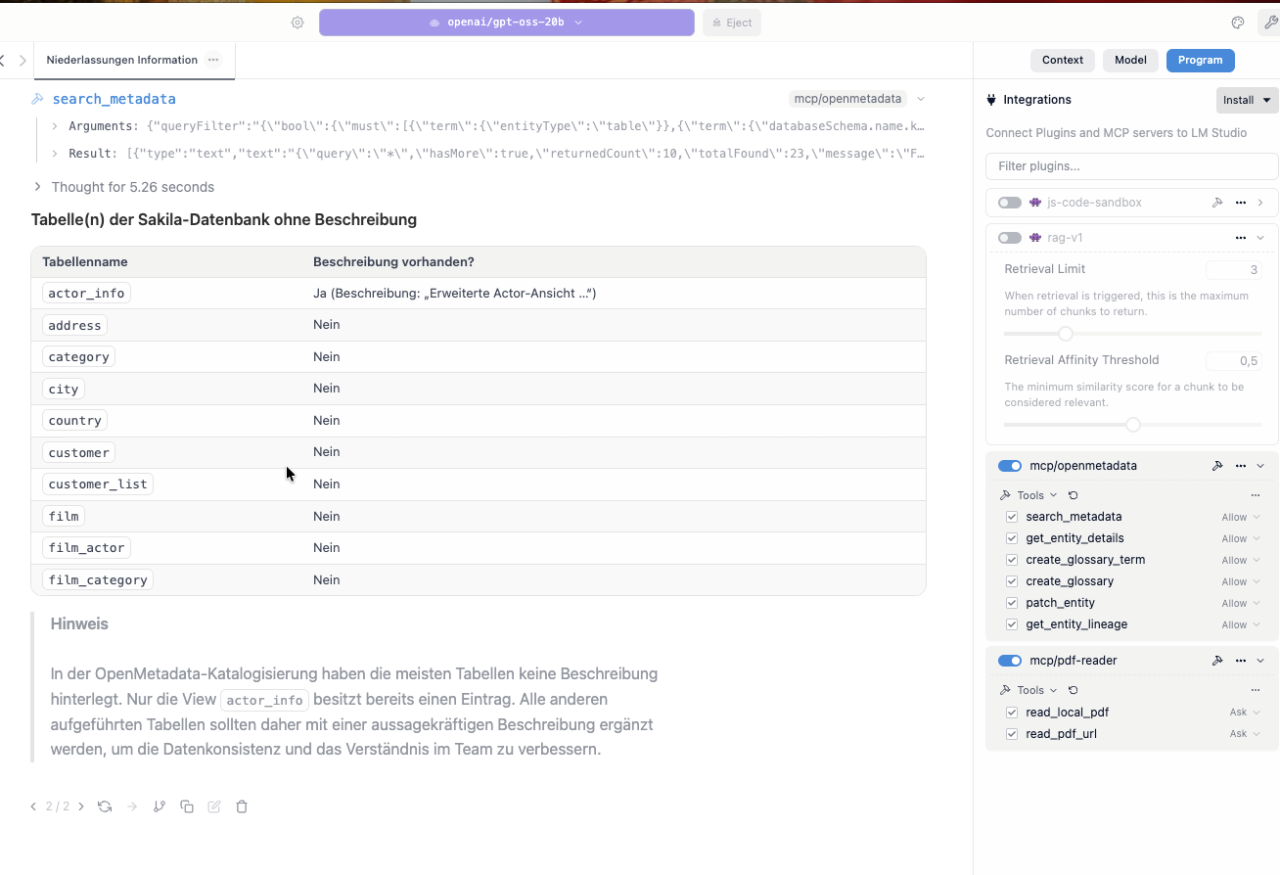
Erste Abfrage: Tabellen ohne Beschreibung
Wir starten unseren Dialog mit folgender Frage:
Welche Tabellen in der sakila-Datenbank haben noch keine Beschreibung?
Liefere mir eine kurze Übersicht als Tabelle.
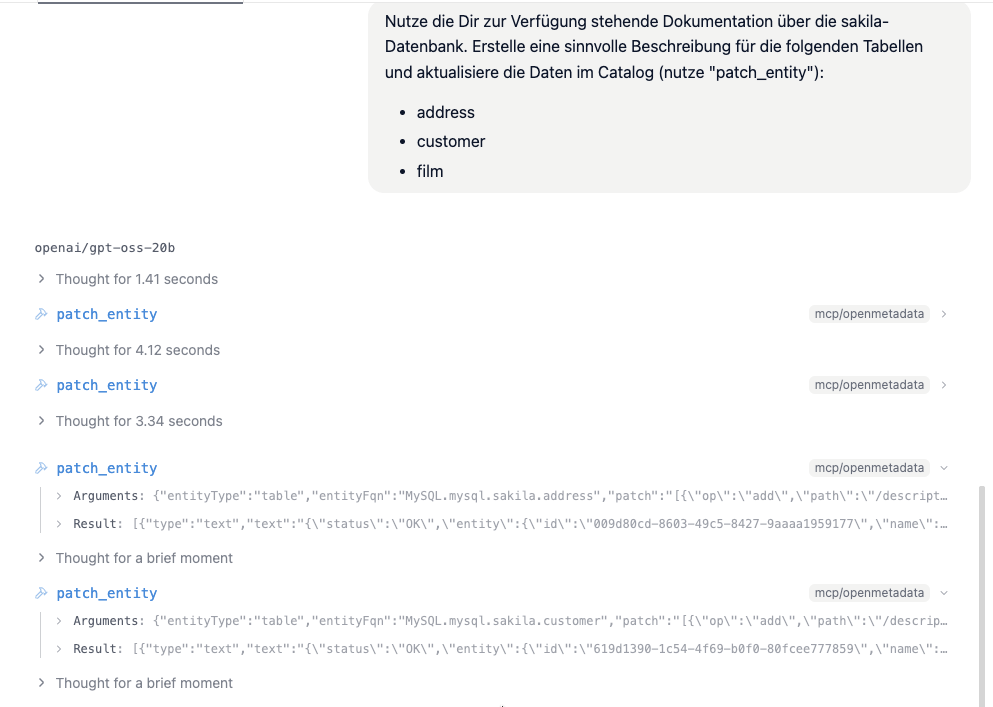
Nächster Schritt: Tabellen beschreiben
Um die Daten im Catalog zu aktualisieren, nutzen wir die vorhandene Dokumentation und die patch_entity-Funktion. Beispielhaft werden folgende Tabellen ergänzt:
- address
- customer
- film
Hinweis: Die Verarbeitung großer Datenmengen auf einem MacBook ist ressourcenintensiv. Für umfangreichere Aufgaben empfiehlt sich ein leistungsfähigerer Rechner oder Server.
Nutze die Dir zur Verfügung stehende Dokumentation über die sakila-Datenbank. Erstelle eine sinnvolle Beschreibung für die folgenden Tabellen und aktualisiere die Daten im Catalog (nutze "patch_entity"):
- address
- customer
- film

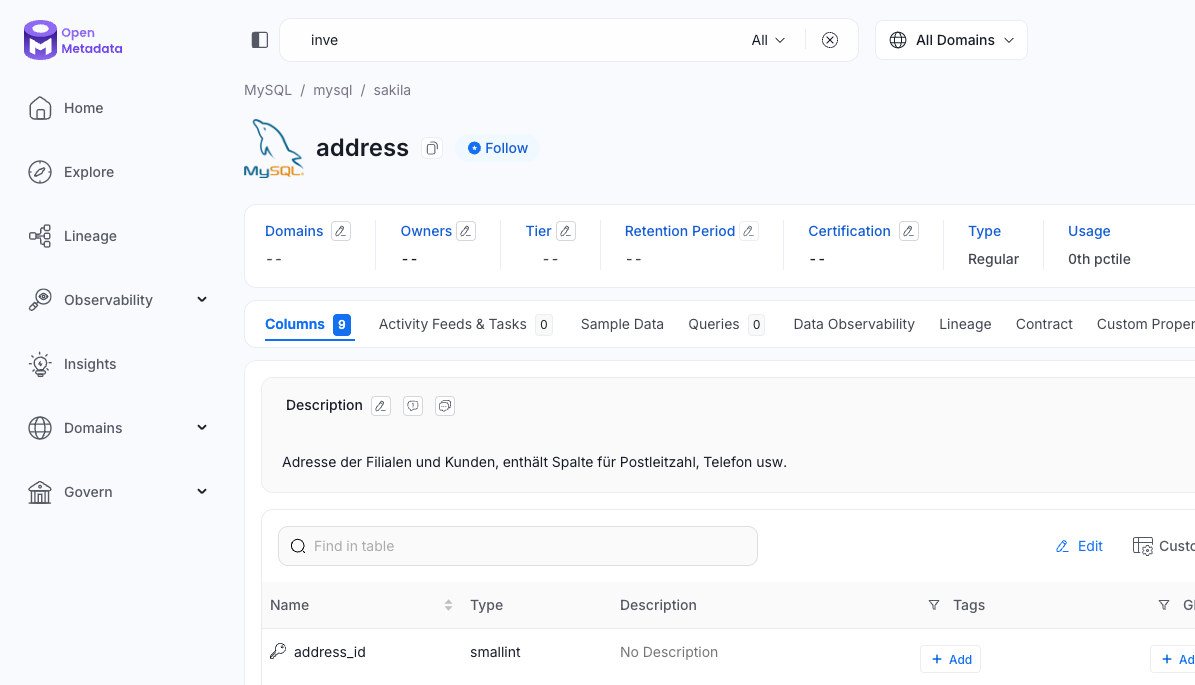
Wie sieht das Ergebnis im Datenkatalog aus?
Fazit
Es ist beeindruckend zu sehen, wie aktiv an OpenMetadata und LM Studio gearbeitet wird. Der Einsatz von KI-Modellen und die Integration in einfach zu nutzende Tools ermöglichen es, zeitintensive Arbeiten in wenigen Minuten produktiv zu erledigen – selbst auf meinem MacBook. Mit einem leistungsstärkeren Setup ließen sich die Möglichkeiten noch deutlich erweitern.
P.S. Ex Machina (2014); https://www.imdb.com/de/title/tt0470752/
Ab hier beginnt der Beitrag in seiner ursprünglichen Form vom 09.09.2025
Für wen ist das relevant?
Dieser Beitrag richtet sich an Data Stewards, Governance-Verantwortliche und KI-Interessierte, die verstehen wollen, wie moderne Metadateninfrastrukturen mit KI interagieren – und wie sich daraus neue Möglichkeiten für Automatisierung, Transparenz und Verantwortung ergeben.
Die Ausgangslage
In der Welt der Data Governance ist Kontext alles. Wer Daten verstehen, verantwortungsvoll nutzen und strategisch einsetzen will, braucht mehr als nur Tabellen und Dashboards – er braucht Metadaten, die nicht nur dokumentieren, sondern kommunizieren. Dies hilft vor allem auch den Data Scientists oder BI-Expert:innen, die auf der Suche nach relevanten und qualitativ hochwertigen Daten sind.
KI kann dabei unterstützen, Metadaten nicht nur zugänglich, sondern auch dialogfähig zu machen. Viele Hersteller von Datenkatalogen integrieren derzeit KI-Funktionalitäten in ihre Produkte – von Collibra über Informatica bis hin zu Open-Source-Lösungen wie OpenMetadata. Die Richtung ist klar: natürlichsprachliche Interaktion, automatisierte Klassifizierung, intelligente Lineage und kontextbezogene Empfehlungen.
Was ist MCP?
Das Model Context Protocol (MCP) ist eine standardisierte Schnittstelle, über die Large Language Models (LLMs) mit Daten- und Metadatenquellen kommunizieren können. Es definiert:
- Welche Informationen ein Modell anfragen darf
- Wie diese Informationen strukturiert zurückgegeben werden
- Wie die Interaktion dokumentiert und versioniert wird
Kurz gesagt: MCP macht Metadaten KI-kompatibel und KI Governance-fähig.
Hands-on: KI trifft OpenMetadata
In dieser Blogreihe haben wir bereits mehrfach im Kontext unserer Demoumgebung (der Blockbuster Bytes AG) mit OpenMetadata gearbeitet. Auch diesmal nutzen wir das Tool, um die Möglichkeiten von MCP exemplarisch zu demonstrieren.
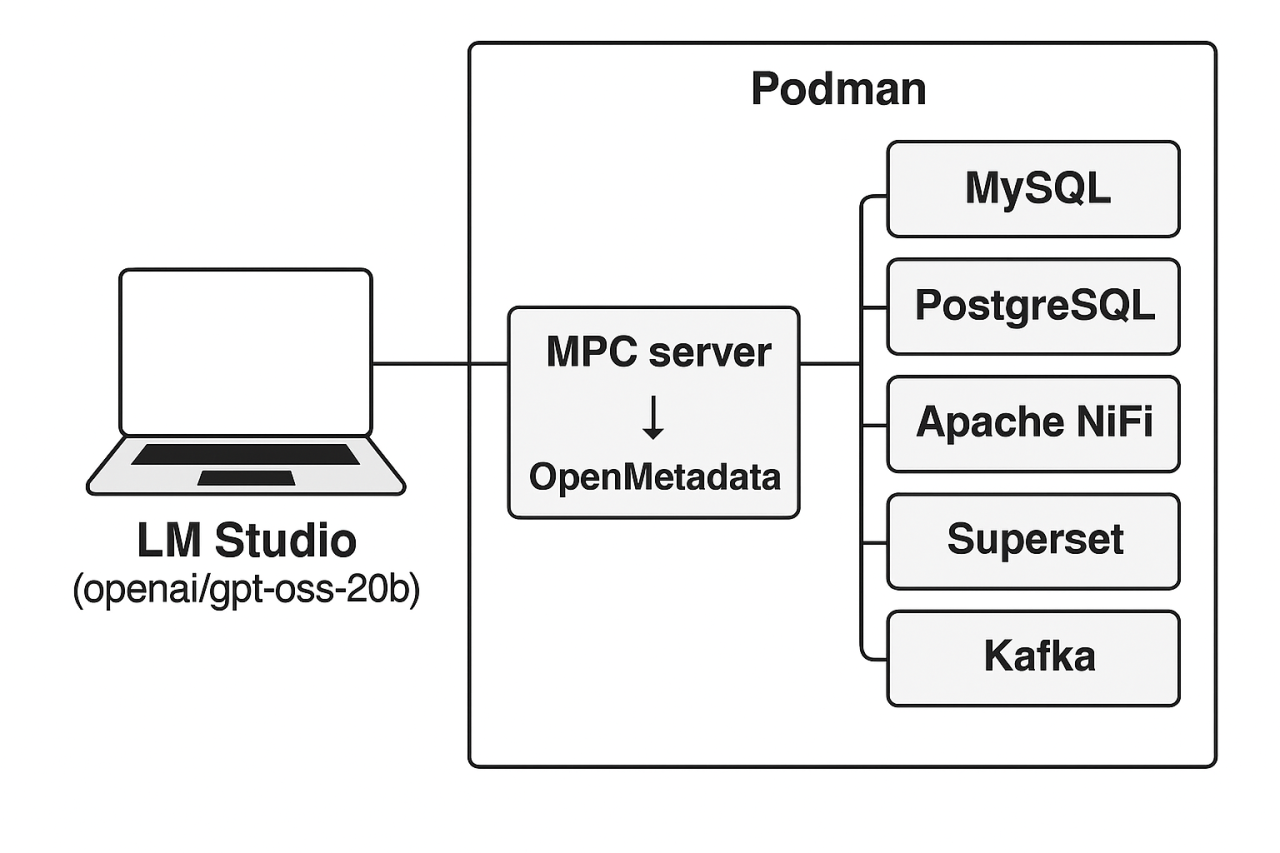
Unser Setup (Abb. 1) läuft lokal auf einem MacBook. In einer Podman-Umgebung sind neben OpenMetadata weitere Systeme integriert: MySQL, PostgreSQL, Apache NiFi, Superset und Kafka. Diese containerisierte Welt ist symbolisiert die Dateninfrastruktur unserer Laborumgebung. Zusätzlich läuft LM Studio mit einem lokal ausgeführten Modell (openai/gpt-oss-20b), das speziell für den Einsatz externer Tools wie OpenMetadata trainiert wurde. LM Studio wurde so konfiguriert, dass unser Sprachmodell mit dem MCP-Server unseres Datenkatalogs (OpenMetadata) kommunizieren kann und darf (siehe rechter Rand Abb. 2).
Was bringt das konkret?
Wir können mit unseren nun Daten natürlichsprachliche Abfragen durchführen. Stellen wir uns einmal exemplarisch Fragen wie:
- „Welche Tabellen enthalten DSGVO-relevante (bei uns heißt das Label: PII sensitive) Daten?“
- „Wer ist Owner der Datenquelle customer?“
- „Werden Daten von customer von anderen Datenquellen/-punkten verwendet?“
Die Antworten kommen jetzt direkt aus dem Metadatenkatalog – angereichert mit Lineage, Klassifizierung und Verantwortlichkeiten. Je besser unsere Metadaten beschrieben sind, umso besser sind die Ergebnisse der KI.
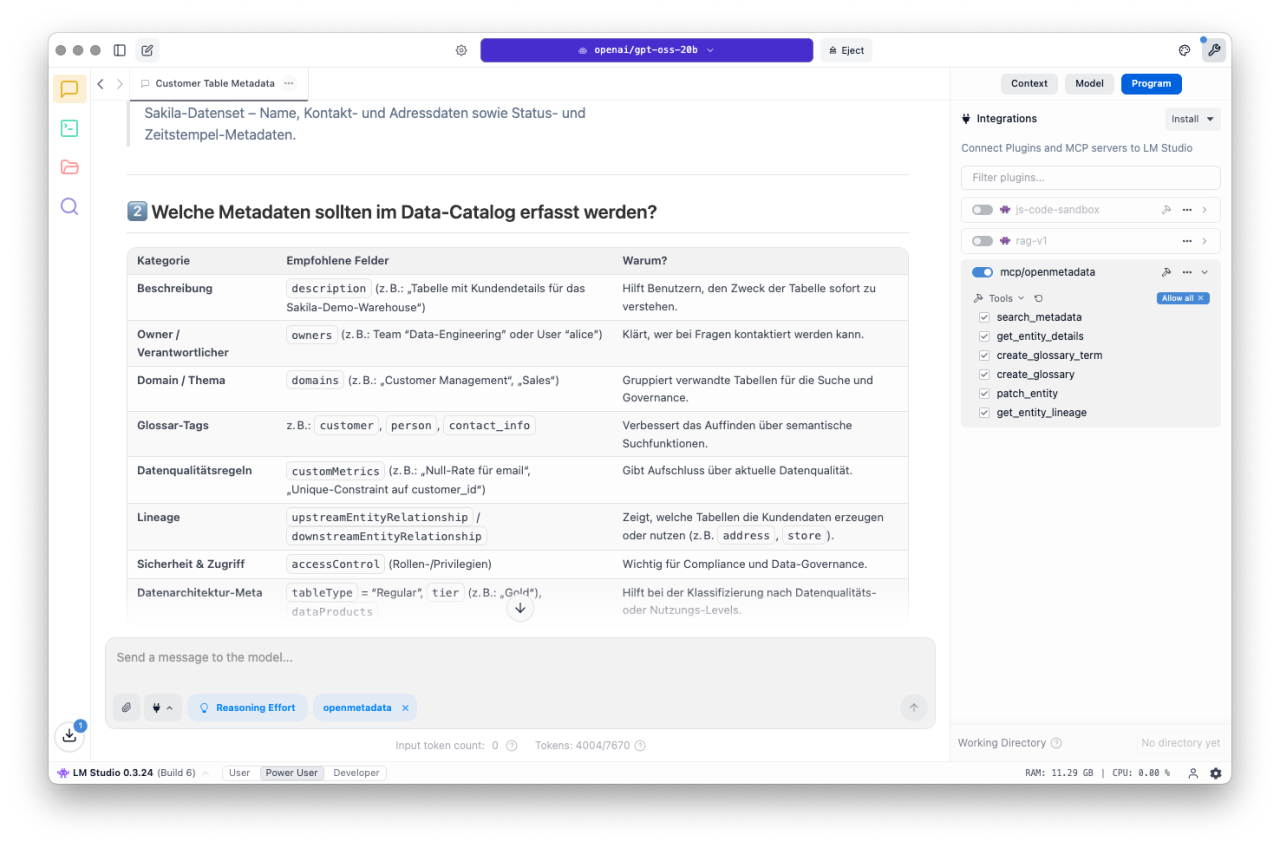
In den folgenden Beispielen chatten wir mit unserem OpenMetadata-Datenkatalog.
Im ersten Beispiel wollen wir wissen, welche Pipeline(s) (Lineage-Beziehungen) in unserer Blockbuster Bytes AG (Domaine Bbytes) aktiv sind. Die Datenströme sollten grafisch (ASCII) dargestellt werden. Zusätzlich wollen wir wissen, ob eine Ziel-Tabelle der gefundenen Lineage-Beziehungen unsere PII Standard ordnungsgemäß implementiert hat.
Geben und Nehmen?
Unser Setup kann jedoch nicht nur genutzt werden, um Informationen über unsere Daten und Metadaten zu erhalten. Die KI lässt sich auch nutzen, um unsere Inhalte besser zu beschreiben und/oder zu kontrollieren. Dazu versuchen wir im zweiten Beispiel eine vorhandene Tabelle (die Zieltabelle aus dem ersten Beispiel) besser zu dokumentieren. Wir wollen also neue/bessere Metadaten mittels KI erzeugen.
Unsere Frage an das Modell lautet: „Ist die Tabelle „customer“ in der PostgreSQL Datenbank optimal dokumentiert?“ Das Ergebnis sehen wir im Video. Einige Spalten sollten als „PII sensitive“ eingestuft werden.
Eigentlich sollten die vorgeschlagenen Änderungen (PII Informationen) direkt über die Methode „patch_entity“ durch das LLM korrigiert werden können. Allerdings scheint es hier im Zusammenspiel zwischen LM Studio und dem MCP Server syntaktische Probleme zu geben (Die Vermutung: zu viele Maskierungen von Sonderzeichen innerhalb des JSON Dokumentes?!).
Wir bauen daher einen „manuellen“ Workaround, um diese Informationen verarbeiten zu können und übergeben die Änderungen als JSON-Information über einen API-Call. Den JSON-Code selbst lassen wir uns natürlich vom Sprachmodell generieren.
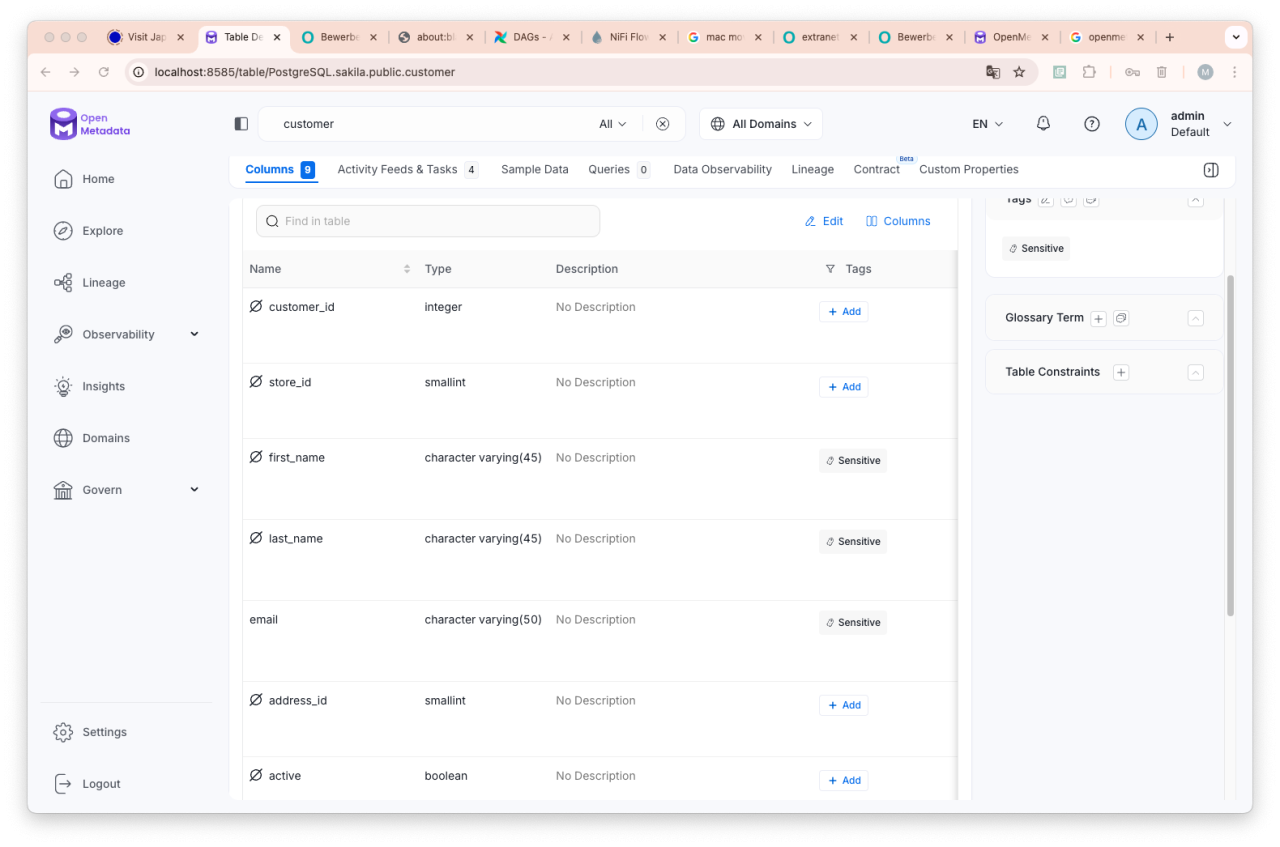
Wir nutzen die vom LLM erzeugten Information, um die Spalten 2, 3 und 4 (first_name, last_name, email) in der Tabelle „customer“ auf „PII.Sensitive“ zu setzen. Über ein Shell-Skript (siehe unten) generieren wir einen entsprechenden API-Call (curl-Kommando) und übergeben die Informationen an den Katalog:
bash> cat patch_customer.sh
# Setze deine Variablen
OM_HOST="http://localhost:8585" # Basis‑URL unseres OM‑Servers
TABLE_FQN="PostgreSQL.sakila.public.customer" # Fully Qualified Name der Tabelle
API_TOKEN="eyJra***********SWA" # OAuth / Bearer Token
# Patch‑Body – JSON‑Patch Information aus dem LLM
PATCH_BODY='[
{
"op": "add",
"path": "/columns/2/tags/-",
"value": {
"tagFQN": "PII.Sensitive",
"labelType": "Manual",
"state": "Confirmed",
"source": "Classification"
}
},
{
… <gekürzt> …
{
"op": "add",
"path": "/columns/4/tags/-",
"value": {
"tagFQN": "PII.Sensitive",
"labelType": "Manual",
"state": "Confirmed",
"source": "Classification"
}
}
]'
# Ausführen des API Aufrufes
curl -X PATCH \
"$OM_HOST/api/v1/tables/name/$TABLE_FQN" \
-H "Authorization: Bearer $API_TOKEN" \
-H "Content-Type: application/json-patch+json" \
-d "$PATCH_BODY"
Das Ergebnis ist wie erwartet. Die Spalten der Tabelle wurden als PII relevant eingestuft und dementsprechend geändert.
Natürlich sind auch andere, komplexere/umfangreichere Szenarien denkbar. Hier einige (fiktive) Beispiele, die sicherlich spannend wären.
- Welche Spalten unterhalb meiner Datenbank sakila (FQN: MySQL.default.sakila) sollten „PII sensitive sein“, sind es aber aktuell nicht? Passe dies bitte an.
- Gibt es Tabellen ohne Owner, die der Sub-Data-Domain BBytes.Filme zugeordnet werden sollten? Analysiere den Tabellennamen, die Spaltennamen und die Beschreibung des Objektes zur Klärung der Domain. Liefere eine Tabelle mit den Spalten, FQN, Tabellenname, Spaltennamen, Beschreibungen der betroffenen Tabellen.
- Welche Objekte sind in den letzten 24h im Katalog aufgenommen oder verändert worden?
Was sind die Grenzen?
Die Qualität der KI-Interaktion hängt entscheidend von der Vollständigkeit und Konsistenz der Metadaten ab. Fehlende Klassifizierungen, unklare Verantwortlichkeiten oder veraltete Lineage-Informationen führen schnell zu unbrauchbaren Antworten. Halluzinationen bei LLMs sind besonders bei offenen Fragen ohne klaren Kontext ein Risiko. Eine belastbare Governance-Struktur, kombiniert mit gezielter Steuerung der Sprachmodelle über Parameter wie z. B. Reasoning oder Temperature (vgl. ORDIX blog), schafft den notwendigen Rahmen.
Dieses Zusammenspiel lässt sich letztendlich als Henne-Ei-Problem beschreiben: Ohne hochwertige Metadaten kann die KI keine präzisen Informationen erzeugen, gleichzeitig kann KI helfen, bestehende Lücken zu schließen. Entscheidend ist ein initiales Mindestniveau an Governance und Datenqualität. Sobald diese Grundlage vorhanden ist, entsteht ein sich selbstverstärkender Zyklus – eine Aufwärtsspirale, die mit jeder zusätzlichen Information Effizienz und Qualität steigert.
Auch die Sprache spielt eine Rolle: Allgemeine Fragen wie „Was weißt du über die Tabelle 'customer'?“ liefern oft unbefriedigende Ergebnisse. Präzisere Formulierungen, z. B. über FQNs, erhöhen die Qualität erheblich, auch wenn sie weniger „natürlich“ klingen. Tests auf begrenzten Ressourcen (Macbook) mit vereinfachten Modellen legen nahe: Mit besserer Hardware und spezialisierteren Modellen sollten sowohl Performance als auch Ergebnisqualität deutlich steigen.
P.S. Ex Machina (2014); https://www.imdb.com/de/title/tt0470752/
Seminarempfehlungen
MYSQL ADMINISTRATION DB-MY-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenIT-ORGANISATION UND IT-GOVERNANCE - OPTIMIERUNG IHRER IT-ORGANISATION PM-28
Mehr erfahrenPrincipal Consultant bei ORDIX
Kommentare