
Data Governance #04 – Die Matrix (der Daten): Qualität ist das „A" und „O"
Zur Klärung der zentralen Begriffe haben wir ein Glossar zur Beitragsreihe Data Governance für Sie eingerichtet.
In den letzten Episoden haben wir die grundlegenden Konzepte von Data Governance, wie die Data Domain und den Data Catalog und die Bedeutung einer soliden Datenstrategie erörtert. Nun wird es „qualitativ hochwertiger": In dieser Episode dreht sich nämlich alles um die Datenqualität – ein entscheidendes Fundament für erfolgreiche Data Governance und die Grundlage jeder datengetriebenen Entscheidung. Wir erklären, warum Datenvalidierung eine Schlüsselrolle spielt und wie Sie sicherstellen können, dass Ihre Daten auch wirklich den Anforderungen entsprechen.
Die Bedeutung von Datenqualität
Stellen Sie sich vor, Sie möchten eine wichtige geschäftliche Entscheidung treffen – im Kontext der „Blockbuster Bytes AG" etwa die Erweiterung Ihres Filmportfolios oder die Planung der Anzahl an Kopien eines bestimmten Films, der in mehreren Filialen verfügbar sein soll. Vielleicht möchten Sie auch ein KI-Modell trainieren, um vorherzusagen, wie gut sich ein neuer Film verkaufen wird und basierend darauf die optimale Verfügbarkeit in den Filialen bestimmen.
Sie nehmen Ihre Daten aus der „Blockbuster Bytes AG"-Datenbank, analysieren sie und treffen Ihre Entscheidung. Aber was, wenn die zugrunde liegenden Daten ungenau oder fehlerhaft sind? Ein Fehler in den Leihdatensätzen – etwa ein falscher Verleihzeitpunkt oder eine fehlerhafte Kunden-ID – könnte dazu führen, dass Sie die falsche Entscheidung treffen. Das könnte dazu führen, dass Sie zu viele oder zu wenige Kopien eines Films vorhalten und somit Einnahmen verpassen oder unnötige Lagerkosten verursachen.
Datenqualität ist also nicht nur eine technische Notwendigkeit, sondern ein strategischer Vorteil. Unternehmen, die ihre Daten effektiv validieren und pflegen, haben nicht nur verlässliche Informationen, sondern auch einen Wettbewerbsvorteil. Datenqualität umfasst eine Reihe von Eigenschaften, die sicherstellen, dass die Daten ihren Zweck erfüllen:
• Genauigkeit: Die Daten müssen korrekt sein.
• Vollständigkeit: Es dürfen keine wichtigen Informationen fehlen.
• Konsistenz: Daten müssen widerspruchsfrei sein und in allen Systemen übereinstimmen.
• Aktualität: Die Daten müssen auf dem neuesten Stand sein.
• Zugänglichkeit: Daten müssen einfach und schnell zugänglich sein, wenn sie benötigt werden.
Die Datenvalidierung stellt sicher, dass diese Eigenschaften erhalten bleiben. Sie ist der Schlüssel zur Erkennung und Korrektur von Datenfehlern, bevor sie zu Problemen führen.
Datenqualität ist mehr als Technik
Datenqualität ist nicht nur eine technische Herausforderung, sondern auch eine Frage von Prozessen, Rollen und der Unternehmenskultur. Auf der einen Seite lässt sich Datenqualität durch Technologie sicherstellen – etwa durch Constraints im Datenmodell, die gewährleisten, dass nur gültige und vollständige Daten in die Datenbank aufgenommen werden. Solche technischen Maßnahmen, wie etwa Not Null- und Unique-Constraints, sorgen dafür, dass Daten konsistent bleiben und Fehler in der Erfassung sofort auffallen.
Auf der anderen Seite muss Datenqualität auch durch strukturierte Prozesse und klare Rollen innerhalb der Organisation sichergestellt werden. Hier kommen Data Governance-Rollen wie der Data Steward ins Spiel. Ein Data Steward ist dafür verantwortlich, dass die Datenqualität kontinuierlich überwacht und verbessert wird. Diese Rolle stellt sicher, dass Daten korrekt, vollständig und konsistent sind und unterstützt die Entwicklung und Umsetzung von Datenrichtlinien.
Schauen wir uns diese „Aufgabenteilung" (technische vs organisatorische Qualitätssicherung) mal beispielhaft an der Tabelle „customer" an.
mysql> desc customer; +-------------+-------------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type | Null | Key | Default | Extra | +-------------+-------------------+------+-----+-------------------+-----------------------------------------------+ | customer_id | smallint unsigned | NO | PRI | NULL | auto_increment | | store_id | tinyint unsigned | NO | MUL | NULL | | | first_name | varchar(45) | NO | | NULL | | | last_name | varchar(45) | NO | MUL | NULL | | | email | varchar(50) | YES | | NULL | | | address_id | smallint unsigned | NO | MUL | NULL | | | active | tinyint(1) | NO | | 1 | | | create_date | datetime | NO | | NULL | | | last_update | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP | +-------------+-------------------+------+-----+-------------------+-----------------------------------------------+ 9 rows in set (0.00 sec)
Technisch wird hier bereits gewährleistet, dass Kundendaten halbwegs vollständig (also Felder dürfen nicht leer gelassen werden) erfasst werden. In der heutigen Zeit (wir sind hier ja im Zeitalter von Videotheken unterwegs 😉), sollte wahrscheinlich auch das Feld „email" einen „NOT NULL"-Constraint bekommen. Im Datenmodell gibt es also nicht mehr viel besser zu machen.
Stellen wir uns jetzt aber einmal vor, dass wir regelmäßig Gutscheine per Post an unsere Kunden versenden. Ein Teil der Gutscheine kommt wie ein Boomerang zurück, da die Adressat:innen unbekannt verzogen sind (in Deutschland liegt diese Quote bei ca. 5 - 10%).
Organisatorisch können wir nun sicherstellen, dass ein entsprechender Prozess die Nachverfolgung und Pflege der Adressdaten übernimmt. Bei Erfolg werden die Daten aktualisiert, bei Misserfolg wird der Datensatz von „active = 1" auf „active = 0" gesetzt. Doch wie lassen sich solche organisatorischen Qualitätsanforderungen systematisch umsetzen?
In OpenMetadata können solche Bedingungen direkt an Tabellen oder Spalten geknüpft werden. Exemplarisch möchten wir sicherstellen, dass weniger als 100 unserer Kunden in der Datenbank den Status „inaktiv" haben. Dazu definieren wir spezifische Regeln.
Hierzu verwenden wir ein einfaches SQL-Statement, das einen Integer-Wert zurückgibt (dieser repräsentiert die Anzahl inaktiver Kunden). Zusätzlich legen wir einen Schwellenwert von 100 fest. Wird dieser Schwellenwert überschritten, generiert das System automatisch einen Incident, der eine Eskalation des Problems anstößt.
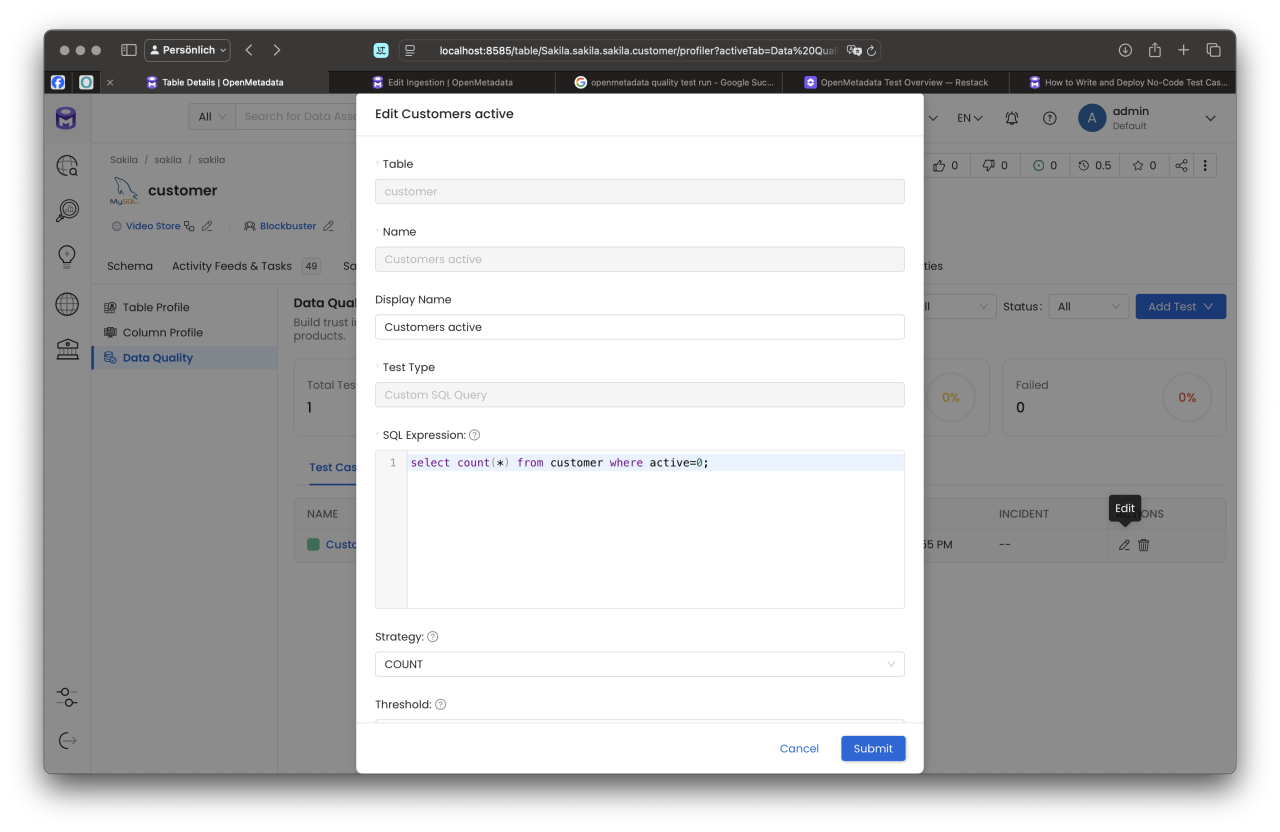
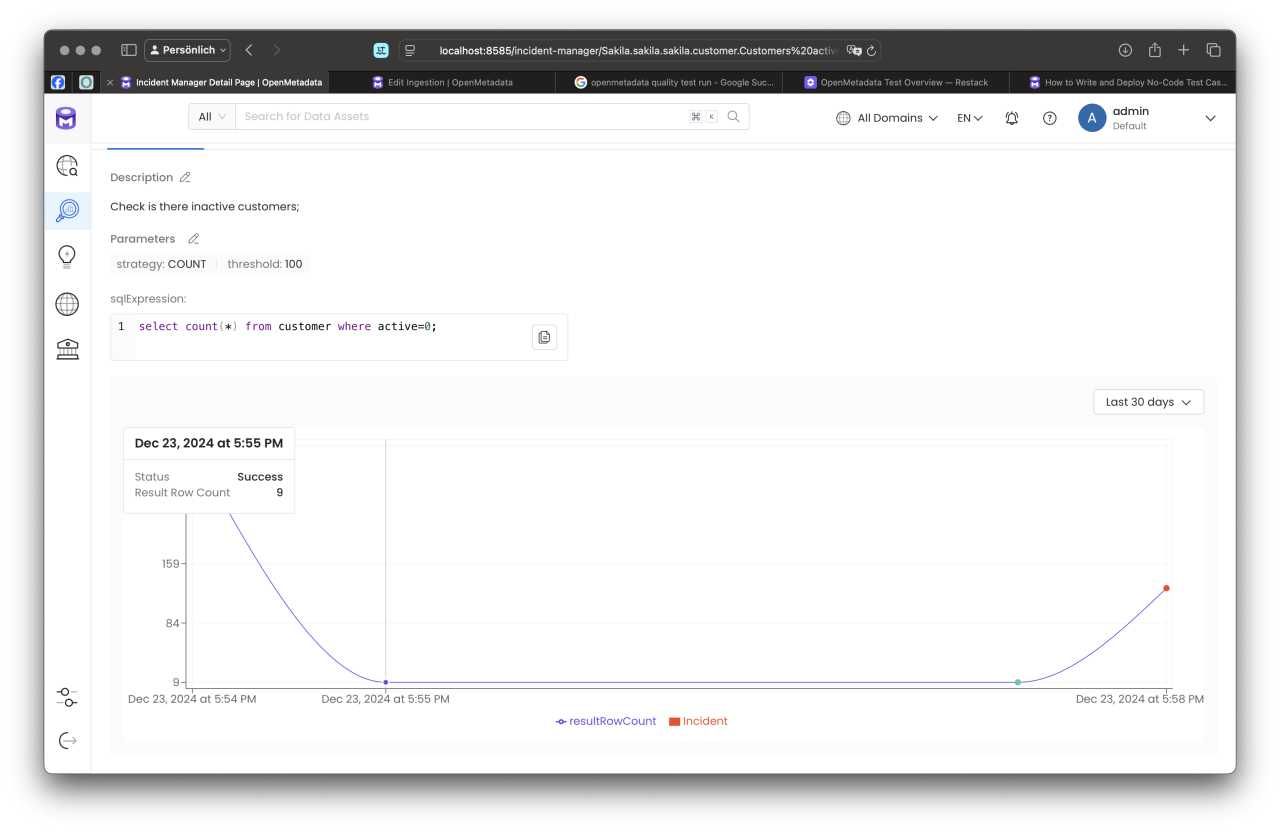
Die Incidents können außerdem Verantwortlichen zugeordnet werden, beispielsweise über die Data Domain oder Subdomain, damit sich die zuständigen Teams direkt um die Lösung kümmern können. Diese strukturierte Herangehensweise gewährleistet eine proaktive und nachvollziehbare Sicherstellung der Datenqualität.

Hier kommt die Rolle des Data Stewards ins Spiel. Der Data Steward ist verantwortlich für die kontinuierliche Überwachung und Pflege der Datenqualität über den rein technischen Rahmen hinaus. In diesem Fall würde der Data Steward:
1. Daten überwachen: Er/sie stellt sicher, dass bei Rückläufern von Post-Mailings, wie den Gutscheinen, eine Nachverfolgung der fehlerhaften Adressen erfolgt.
2. Prozessdefinition: Der Data Steward würde den Prozess definieren, wie mit Rückläufern umgegangen wird – zum Beispiel, dass fehlerhafte Adressen in eine Liste aufgenommen werden, die dann überprüft und ggf. aktualisiert wird.
3. Datenpflege sicherstellen: Bei erfolgreicher Nachverfolgung und Adressaktualisierung würde der Data Steward dafür sorgen, dass die Adressen in der Tabelle „customer" aktualisiert werden und dass die entsprechenden Felder wieder auf den neuesten Stand gebracht werden (z. B. Aktivierung von „active = 1").
4. Deaktivierung von Kunden: Wenn eine Adresse nicht mehr gültig und keine Nachverfolgung möglich ist, könnte der Data Steward den entsprechenden Kundendatensatz auf „active = 0" setzen, um sicherzustellen, dass keine weiteren Postsendungen an diese Adresse gehen.
5. Zusammenarbeit mit Fachabteilungen: Der Data Steward würde außerdem mit anderen Abteilungen (z. B. Marketing und Kundenservice) zusammenarbeiten, um sicherzustellen, dass die Datenqualität kontinuierlich überwacht und verbessert wird.
Durch diesen organisatorischen Prozess, der über die rein technischen Maßnahmen hinausgeht, stellt der Data Steward sicher, dass das Unternehmen eine möglichst hohe Datenqualität erreicht, die für effektive Geschäftsentscheidungen und die Kundenbindung unerlässlich ist.
Aber all das ist nur dann erfolgreich, wenn eine starke Data Culture vorhanden ist – eine Kultur, in der Daten als wertvolle Ressource anerkannt und gepflegt werden. In einer solchen Kultur ist es selbstverständlich, dass alle Beteiligten, sei es aus der IT, den Fachabteilungen oder dem Management, Verantwortung für die Qualität der Daten übernehmen. Nur durch eine gemeinsame Verpflichtung zu Datenqualität, die durch Prozesse und Technologie unterstützt wird, können Unternehmen die Grundlage für fundierte Entscheidungen und langfristigen Erfolg schaffen.
Die Rolle der Datenvalidierung in der Data Governance
Datenvalidierung ist der Prozess, durch den überprüft wird, ob die in einer Datenbank gespeicherten Informationen den festgelegten Standards entsprechen. Sie hilft dabei, Datenfehler zu verhindern, die die Qualität der gesamten Datenbasis beeinträchtigen könnten. Ohne diese Validierungsprozesse würde eine Data Governance-Strategie keine Grundlage haben, um auf verlässliche Daten zurückzugreifen.
Ein Beispiel aus der Blockbuster Bytes AG, unserer fiktiven Unternehmensumgebung, könnte folgendermaßen aussehen:
Nehmen wir an, Blockbuster Bytes verwendet eine MySQL-Datenbank für die Verwaltung von Filmdaten und Kundentransaktionen. Wenn in der Filmdatenbank die Informationen zu Filmtiteln oder Verleihvorgängen unvollständig oder falsch sind, können falsche Berechnungen von Mietpreismodellen und eine schlechte Benutzererfahrung die Folge sein. Um dies zu vermeiden, würde die Datenvalidierung zum Beispiel sicherstellen, dass:
- Alle Filmtitel korrekt eingegeben werden.
- Keine ungültigen Zeichen in Filmdaten oder in den Feldern für Filmkategorien existieren.
- Es keine Duplikate von Filminformationen gibt.
- Verleihvorgänge nur dann bearbeitet werden können, wenn die richtigen Daten über den Lagerbestand verfügbar sind.
Datenvalidierung sorgt so dafür, dass nur gute Daten in die Produktionssysteme gelangen. Sie ist ein fortlaufender Prozess, der mit jeder Datenänderung und -eingabe ausgeführt wird, um Fehler sofort zu erkennen und zu beheben.
Die Folgen von schlechter Datenqualität
Die Auswirkungen schlechter Datenqualität sind nicht zu unterschätzen. Eine unzureichende Datenvalidierung kann zu einer Vielzahl von Problemen führen, wie zum Beispiel:
- Fehlerhafte Analysen und Berichte: Wenn ungenaue Daten in Analyse-Tools gelangen, entstehen falsche Schlussfolgerungen und Geschäftsentscheidungen.
- Verpasste Geschäftsmöglichkeiten: Schlechte Datenqualität kann dazu führen, dass Chancen nicht rechtzeitig erkannt oder ineffizient genutzt werden.
- Compliance-Risiken: Besonders in regulierten Branchen (wie dem Bankenwesen oder dem Gesundheitswesen) kann die falsche Verarbeitung von Daten zu Compliance-Verstößen und rechtlichen Konsequenzen führen.
- Vermindertes Vertrauen der Stakeholder: Wenn Daten als unzuverlässig wahrgenommen werden, leidet nicht nur das Vertrauen der Entscheidungsträger im Unternehmen, sondern auch das Vertrauen von Partnern und Kunden.
In der Blockbuster Bytes AG könnte dies etwa dazu führen, dass falsche Verleihgebühren berechnet werden oder Kunden falsche Informationen über verfügbare Filme erhalten. Auf lange Sicht schadet das dem Image und den Geschäftsergebnissen des Unternehmens.
Best Practices für Datenvalidierung und -qualität
Um diese Probleme zu vermeiden, sind verschiedene Best Practices erforderlich:
1. Regelbasierte Validierung: Die Einführung von klaren Regeln für jede Datenkategorie (z. B. Kundeninformationen, Filme oder Transaktionen) sorgt dafür, dass alle Daten einer festgelegten Struktur folgen und Fehler direkt erkannt werden.
2. Automatisierte Validierungstools: Der Einsatz von Tools, die in Echtzeit Daten validieren (z. B. OpenMetadata), hilft, Fehler frühzeitig zu erkennen und automatisch zu korrigieren, bevor sie Auswirkungen auf andere Bereiche haben.
3. Datenqualitäts-Überwachungsprozesse: Ein kontinuierliches Monitoring stellt sicher, dass Fehler und Inkonsistenzen regelmäßig überprüft und behoben werden. Dies erfordert die Implementierung eines Dashboards, das die Qualität der Daten laufend überwacht und mit klaren KPIs visualisiert.
4. Datenbereinigung und -korrekturen: Wenn Fehler entdeckt werden, müssen systematische Bereinigungsprozesse implementiert werden, um fehlerhafte Daten zu korrigieren und den Datenbestand auf einen hohen Standard zu bringen.
5. Schulung und Sensibilisierung: Alle Mitarbeiter:innen, die mit Daten arbeiten – von der Dateneingabe bis hin zur Datenanalyse – müssen geschult werden, um die Bedeutung von Datenqualität zu verstehen und mit den richtigen Tools zu arbeiten.
Fazit: Datenqualität als Grundlage einer erfolgreichen Data Governance
Eine solide Datenqualitätsstrategie ist unverzichtbar für jede Data Governance-Initiative. Sie bildet das Fundament, auf dem die gesamte Datenstrategie aufgebaut ist. Die richtige Datenvalidierung hilft dabei, Fehler zu erkennen, bevor sie zu Problemen führen und stellt sicher, dass alle Beteiligten auf korrekte, vollständige und aktuelle Daten zugreifen können.
Für Unternehmen wie die Blockbuster Bytes AG kann dies bedeuten, dass Verleihvorgänge präzise abgewickelt und Filme korrekt kategorisiert werden. Für größere Unternehmen und komplexere Systeme ist die Bedeutung von Datenqualität noch größer – sie kann den Unterschied zwischen einem erfolgreichen Unternehmen und einem, das in der Datenflut untergeht, ausmachen.
P.S. The Matrix (1999); https://www.imdb.com/de/title/tt0133093/
Seminarempfehlungen
MYSQL ADMINISTRATION DB-MY-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenIT-ORGANISATION UND IT-GOVERNANCE - OPTIMIERUNG IHRER IT-ORGANISATION PM-28
Mehr erfahrenPrincipal Consultant bei ORDIX
Kommentare