
Data Governance #06 – Die Brücken am Fluss oder was ist eigentlich Data Lineage?
Zur Klärung der zentralen Begriffe haben wir ein Glossar zur Beitragsreihe Data Governance für Sie eingerichtet.
In der letzten Episode haben wir die Bedeutung von Data Products herausgestellt. Im heutigen Beitrag widmen wir uns einem weiteren zentralen Element moderner Data Governance: Data Lineage.
Im Kontext der Data Governance ist es entscheidend, den Weg von Daten nachvollziehen zu können. Wie wird eine Information in einem System erfasst, verarbeitet und genutzt? Welche Datenquellen fließen zusammen, um eine Entscheidung zu treffen? Welche Prozesse und Transformationen durchlaufen die Daten, bevor sie den/die Endnutzer:in erreichen? Die Fähigkeit, diese Fragen zu beantworten, wird als Data Lineage bezeichnet und ist ein Schlüsselprinzip innerhalb einer effektiven Data Governance.
Data Lineage beschreibt die Herkunft und die Reise von Daten durch verschiedene Systeme, Datenbanken, Tabellen und Prozesse. Es geht darum, alle Schritte transparent und nachvollziehbar zu dokumentieren, die Daten von ihrer Erfassung bis zu ihrer Nutzung im Reporting, in der Analyse oder in Entscheidungen durchlaufen. Das ermöglicht nicht nur eine bessere Kontrolle und Qualitätssicherung der Daten, sondern auch eine effiziente Problemlösung und ein besseres Verständnis von Datenströmen in einer Organisation.
Die Bedeutung von Data Lineage in der Praxis wird besonders deutlich, wenn man sich vor Augen führt, dass in modernen Unternehmen Daten aus unterschiedlichsten Quellen stammen – von internen Transaktionsdaten über Daten von Partnerunternehmen bis hin zu öffentlich zugänglichen Daten. Die Herausforderung besteht darin, diese heterogenen Datenquellen zu einem kohärenten Ganzen zusammenzuführen und zu verstehen, wie sie in das übergeordnete Geschäftsmodell integriert werden.
Beispiel 1: Hackerangriff auf ein Quellsystem und Auswirkungen auf nachfolgende Systeme und Datenprodukte
Stellen wir uns vor, ein:e Hacker:in hat Zugriff auf das Quellsystem der sakila-Datenbank und manipuliert die Daten in der „rental"-Tabelle. Diese Tabelle enthält Informationen zu ausgeliehenen Filmen, einschließlich der Mietdaten, Kunden und dem Status der Ausleihe.
Auswirkungen auf nachfolgende Systeme:
Ein Data Product, das auf den Daten aus der rental-Tabelle basiert, wie zum Beispiel ein Bericht über die meist ausgeliehenen Filme (siehe vorherige Beispiele), wird durch diese Manipulation beeinflusst. Der/die Hacker:in hat möglicherweise Mietdaten verändert, hinzugefügt oder gelöscht, was dazu führt, dass die berechneten Metriken (z. B. die Anzahl der Ausleihen) verfälscht werden. Da der Datenfluss von der rental-Tabelle zu nachgelagerten Produkten wie Dashboards, Management-Reports oder Analysen führt, können diese Datenprodukte falsche oder ungenaue Informationen liefern.
Ein Management-Report, der regelmäßig die meist ausgeliehenen Filme anzeigt (basierend auf den Daten aus der rental-Tabelle), könnte falsche Empfehlungen oder Marketingentscheidungen nach sich ziehen. Wenn das Management daraufhin falsche Entscheidungen trifft (z. B. in Bezug auf Filmbestände oder Marketingaktionen), kann dies schwerwiegende Auswirkungen auf die Geschäftsstrategie haben.
Beispiel 2: Data Scientist möchte Datenqualität vor dem Modellieren sicherstellen und Datenflüsse zurückverfolgen
Ein Data Scientist, der auf die sakila-Datenbank zugreift, möchte ein Machine Learning-Modell entwickeln, um Vorhersagen über die Ausleihgewohnheiten von Kunden zu treffen. Dazu möchte er mehrere Data Products verwenden, die auf verschiedenen Tabellen basieren, wie z. B. „film", „inventory" und „rental" (siehe Beispiel aus dem letzten Blog-Beitrag). Bevor er mit dem Modellieren und Trainieren beginnt, möchte er jedoch sicherstellen, dass die verwendeten Daten von hoher Qualität sind.
Beispiel 3: BI Analyst stellt im Data Warehouse unplausible Daten fest
Ein BI Analyst erstellt ein Dashboard zu den beliebtesten Film-Genres in Anhängigkeit der Lokation/Region des Verleihs. Dazu nutzt er unter anderem in seinem PostgreSQL Data Warehouse-Server (movie_DWH) eine Tabelle „film_list". Er hat über „Crosschecks" festgestellt, dass Filmtitel mehrfach anlegt wurden (mit unterschiedlichen Primärschlüsseln). Er möchte nun analysieren, wie die Daten in sein Data Warehouse gelangen.
Vorgehen des BI Analysten:
Der Analyse nutzt die Data Lineage Funktion von OpenMetaData und sucht nach seiner Tabelle.
Da er sowohl den Namen seiner Tabelle als auch den seines Systems kennt, ist das Finden des Objektes kein Problem.
Im nächsten Schritt, schaut er sich den Reiter „Data Lineage" für sein Objekt näher an.
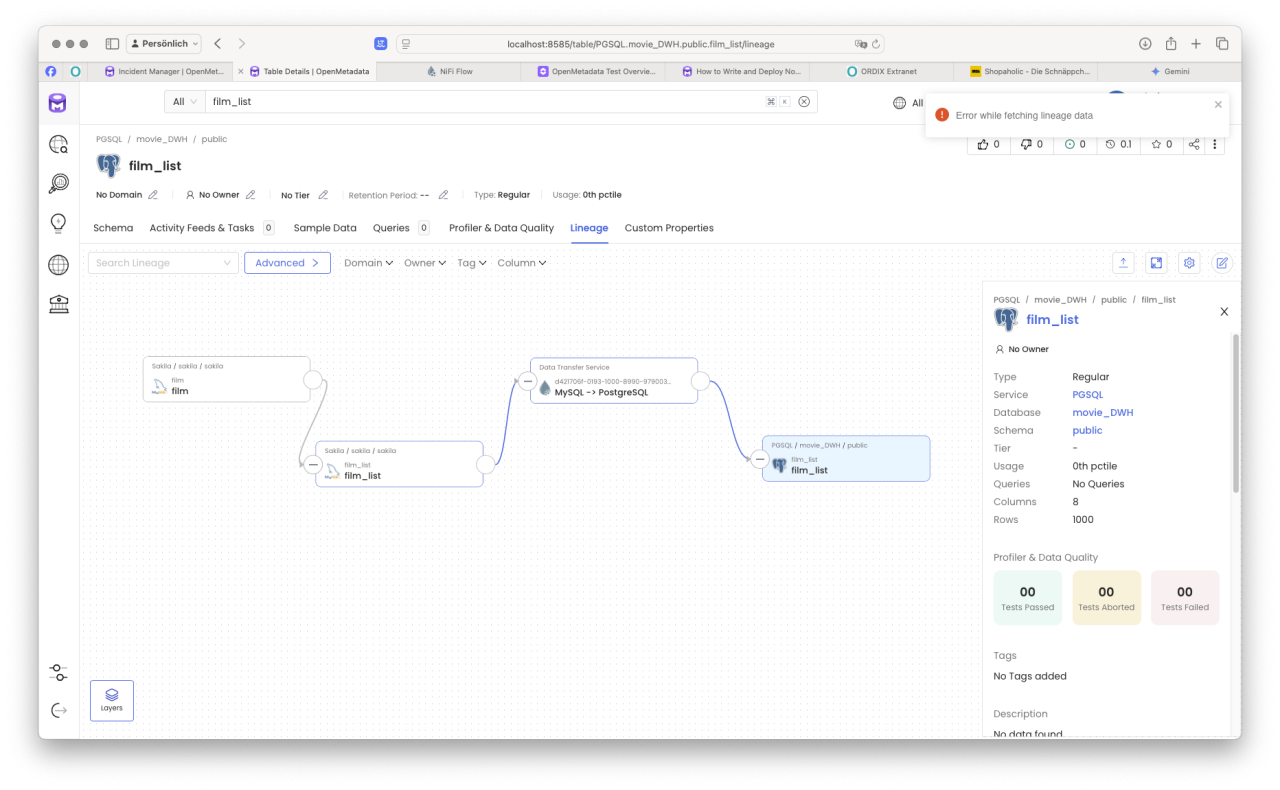
Der Fluss der Daten ist für den BI Analysten jetzt klar. Natürlich kann er sich über „Drill-Down"-Funktionalitäten über die in der Kette befindlichen Elemente informieren. Wichtig ist natürlich, dass in jeder Ebene die Metadaten von den verantwortlichen Personen sauber erfasst und gepflegt wurden.
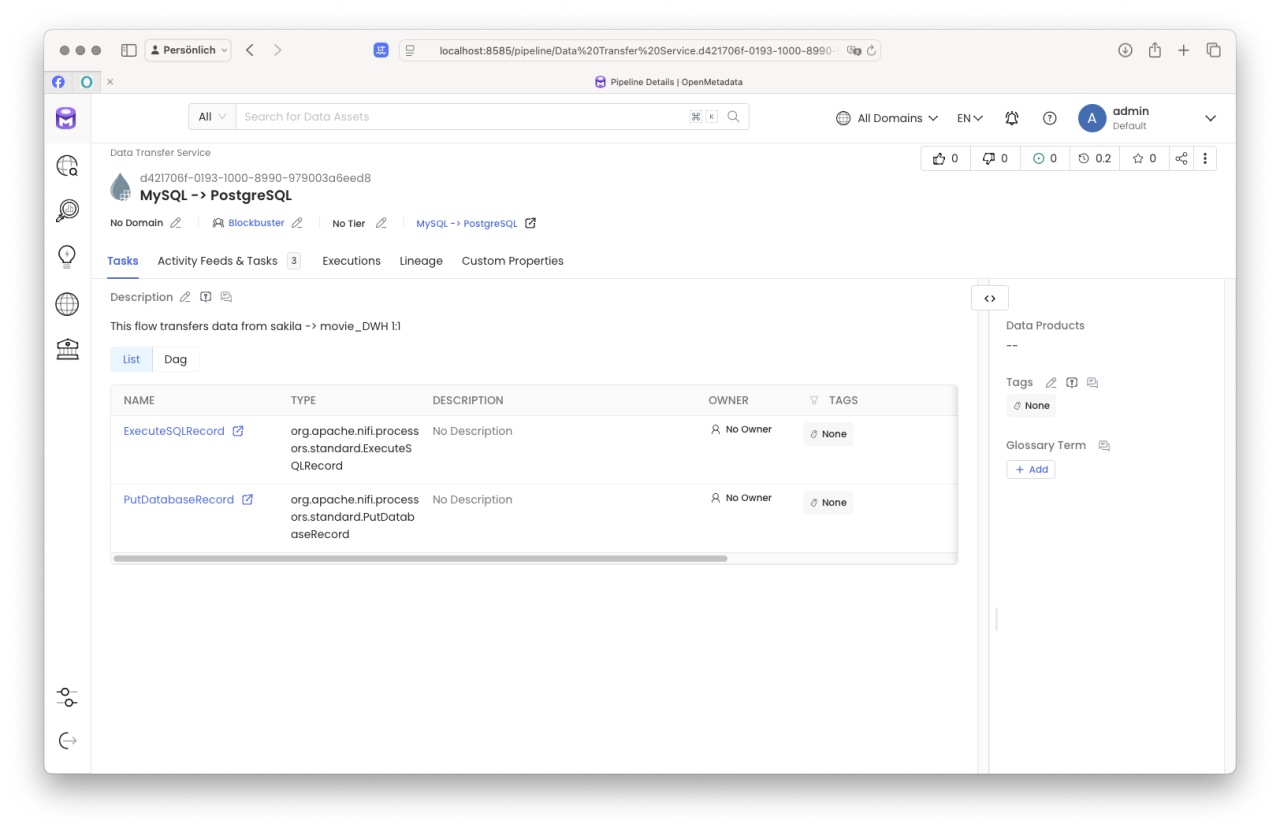
So kann sich unser BI Analyst Ebene für Ebene bis zur Wurzel seines Datenstroms vorarbeiten und sofern für die Analyse notwendig, Rücksprache mit den Verantwortlichen halten. Im einfachsten Fall jedoch informiert er den Data Product Owner oder zuständigen Data Steward, damit er sich dieses Problems annimmt und wartet auf eine Lösung.
Fazit
Data Lineage ist ein unverzichtbares Werkzeug für eine effektive Data Governance. Es ermöglicht, den Ursprung und die Transformation von Daten über alle Systeme und Datenprodukte hinweg nachzuvollziehen und sorgt so für Transparenz und Qualitätssicherung. In allen genannten Beispielen – sei es bei der Aufdeckung von Hackerangriffen, der Sicherstellung von Datenqualität für Machine Learning-Modelle oder der Lösung von Inkonsistenzen im BI-Dashboard – zeigt sich die zentrale Bedeutung der Nachverfolgbarkeit von Datenflüssen für das Vertrauen in Daten und die Entscheidungsfindung in modernen Organisationen.
Übrigens: Die Wahl eines Datenintegrationstools, welches Lineage Informationen bereitstellt oder sich in einen Datenkatalog (Data Catalog) einfach integrieren kann, spart einige Arbeit.
P.S. Die Brücken am Fluss (1995); https://www.imdb.com/de/title/tt0112579/?ref_=fn_all_ttl_1
Seminarempfehlungen
MYSQL ADMINISTRATION DB-MY-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenIT-ORGANISATION UND IT-GOVERNANCE - OPTIMIERUNG IHRER IT-ORGANISATION PM-28
Mehr erfahrenPrincipal Consultant bei ORDIX
Kommentare