
Data Governance #05 – Shopaholic oder warum Data Products doch glücklich machen
Zur Klärung der zentralen Begriffe haben wir ein Glossar zur Beitragsreihe Data Governance für Sie eingerichtet.
In der letzten Episode haben wir die Grundlagen der Data Governance beleuchtet und dabei die Bedeutung von Data Domains, Data Catalogs und einer soliden Datenstrategie hervorgehoben.
In diesem Beitrag stellen wir Ihnen Data Products, als eine zentrale Komponente moderner Data Governance vor. Sie ermöglichen es Organisationen, datenbasierte Mehrwerte (Produkte) effizient bereitzustellen. Doch was ist ein Data Product genau? Wie wird es in der Praxis definiert und umgesetzt? Und wie können wir anhand der sakila-Datenbank exemplarisch einfache Data Products entwickeln? In diesem Beitrag werden wir diesen Fragen nachgehen.
Was sind Data Products?
Ein Data Product ist eine strukturierte, wiederverwendbare und dokumentierte Bereitstellung von Daten oder Datenservices, die bestimmte Geschäftsanforderungen adressieren. Es geht darum, Daten wie ein Produkt zu behandeln:
- Klarer Zweck: Es hat eine eindeutige Zielgruppe und eine definierte Anwendung.
- Qualitätssicherung: Es unterliegt klaren Standards für Datenqualität und Aktualität.
- Nutzerzentriert: Es ist leicht konsumierbar und gut dokumentiert.
- Sicherheit: Zugriff und Nutzung werden kontrolliert.
In der Praxis kann ein Data Product eine aggregierte Tabelle oder View, ein Datenfeed, ein Dashboard oder sogar ein API-Endpunkt sein, über den Geschäftsdaten zugänglich gemacht werden. Bevor wir zu den Data Products kommen, sollten wir vorher noch etwas anderes betrachten: Data Literacy & Culture!
Können und Kultur!
Data Culture beschreibt die Haltung und das Verhalten innerhalb einer Organisation im Umgang mit Daten. In einer starken Data Culture werden Daten als wertvolle Ressource wahrgenommen, die strategische Entscheidungen untermauern. Eine solche Kultur sorgt dafür, dass Teams bereichsübergreifend zusammenarbeiten und Daten nicht als isolierte IT-Thematik betrachten, sondern als Basis für Innovation und Wachstum.
Data Literacy, also die Fähigkeit, Daten zu verstehen, zu interpretieren und sinnvoll anzuwenden, ist der Schlüssel, um eine Data Culture lebendig zu machen. Ohne diese Kompetenz fällt es den Mitarbeitenden schwer, die Möglichkeiten von Datenprodukten zu erkennen, geschweige denn, sie in der Praxis zu nutzen. Data Literacy befähigt Teams, Datenfragen zu stellen, Analysen zu interpretieren und datengetriebene Entscheidungen zu treffen.
Nur wenn beide Elemente – Kultur und Kompetenz – vorhanden sind, können Data Products erfolgreich eingeführt und genutzt werden. Sie schaffen die Grundlage, um Datenprodukte nicht nur technisch bereitzustellen, sondern sie auch zielgerichtet einzusetzen und nachhaltig weiterzuentwickeln.
Data Products und die sakila-Datenbank
Die sakila-Datenbank ist ein Beispiel für eine relationale Datenbank, die Daten über einen fiktiven Filmverleih enthält. Wie haben das Datenmodell (ERM) in den vorherigen Blog-Teilen vorgestellt. Mit Tabellen wie film, rental, customer und payment eignet sie sich hervorragend, um typische Herausforderungen bei der Erstellung von Data Products zu veranschaulichen.
Wir möchten exemplarisch das folgende Datenprodukt bereitstellen:
Top-Performer-Filme
Ein Data Product, das regelmäßig aktualisierte Informationen über die am häufigsten ausgeliehenen Filme liefert.
Entwicklung eines Data Products: Top-Performer-Filme
Geschäftsanforderung: Das Management möchte die meist ausgeliehenen Filme kennen, um gezielt Marketingaktionen zu planen.
1. Definition des Data Products
- Zielgruppe: Marketing-Team
- Funktion: eine aggregierte Liste der Filme mit den meisten Ausleihen in den letzten 30 Tagen
- Format: Tabelle oder Dashboard
- Aktualisierung: wöchentlich
2. SQL-Implementierung
Das folgende SQL-Statement generiert die Liste der Top-Performer-Filme:
SELECT f.film_id, f.title, COUNT(r.rental_id) AS rental_count FROM film f JOIN inventory i ON f.film_id = i.film_id JOIN rental r ON i.inventory_id = r.inventory_id WHERE r.rental_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY) GROUP BY f.film_id, f.title ORDER BY rental_count DESC LIMIT 10;
Ergebnis: Dieses Data Product liefert eine Liste der Top 10 Filme basierend auf den Ausleihzahlen der letzten 30 Tage.
3. Dokumentation und Bereitstellung
Das Data Product wird dokumentiert:
- Zweck: Top-Performer-Filme für Marketing
- Aktualisierungshäufigkeit: wöchentlich
- Quellen: Tabellen film, inventory, rental
- Qualitätskontrollen: Datenvalidierung für fehlende Werte und Dubletten
Im nächsten Schritt implementieren wir das SQL-Statement als View in unserer Quell-Datenbank:
CREATE VIEW prod_top_performer AS
SELECT
f.film_id, f.title, COUNT(r.rental_id) AS rental_count
FROM
film f
JOIN
inventory i ON f.film_id = i.film_id
JOIN
rental r ON i.inventory_id = r.inventory_id
WHERE
r.rental_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
GROUP BY f.film_id , f.title
ORDER BY rental_count DESC
LIMIT 10;
OpenMetaData aktualisiert regelmäßig die Metadaten der angebundenen Systeme. Dies bedeutet mit dem nächsten „Refresh" (zur Info: dieser Vorgang wird in diesem Produkt „Ingestion" genannt) unserer sakila-Datenbank, steht das Objekt „prod_top_performer" zu weiteren Beschreibung (mit Metadaten) bereit.
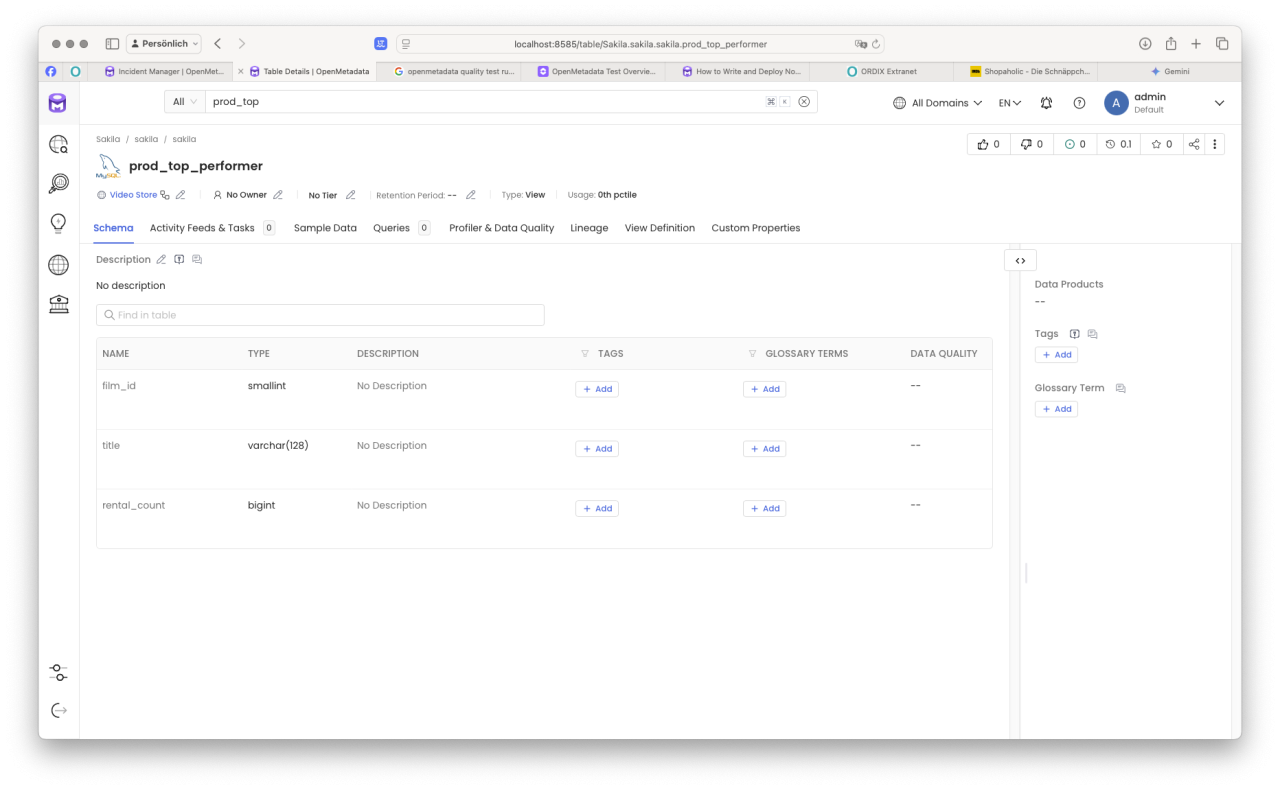
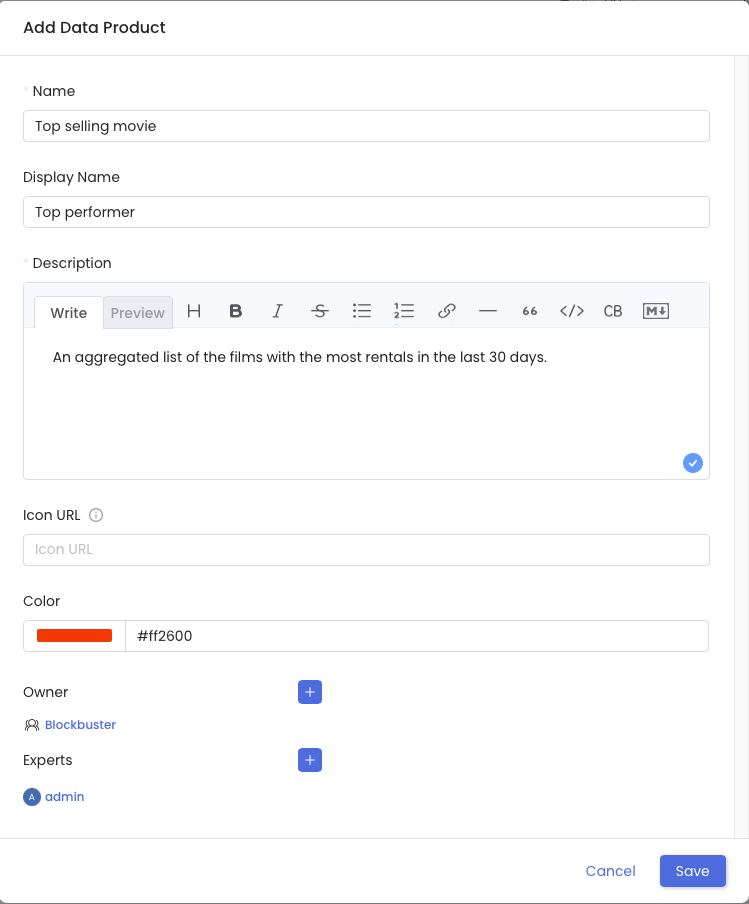
Nun ist es an der Zeit, diese wertvolle Information als Produkt zu beschreiben und „vermarkten"(!).
Dazu legen wir unser erstes Produkt an. Je besser wir das Produkt beschreiben, desto eher wird es gefunden. Wir halten an dieser Stelle die Beschreibung eher kurz 😉.
Die Datenqualität der Basisobjekte kann, wie bereits im letzten Teil (04) beschrieben, durch die Implementierung von „Data Quality"-Regeln optimiert und gewährleistet werden. In der letzten Episode haben wir eine Regel für die Tabelle „customer" definiert, die sicherstellt, dass die Mehrheit der Kunden als „aktiv" gekennzeichnet ist.
Ebenso können auch die zugrunde liegenden Assets eines Data Products, wie zum Beispiel die Tabellen „rental", „inventory" und „film", durch Data-Quality-Regeln überwacht und geprüft werden. Dies garantiert, dass die Daten, die in einem Data Product genutzt werden, den höchsten Qualitätsstandards entsprechen und zuverlässig sind.
Wenn nun ein:e Benutzer:in nach bestimmten Daten sucht, so führt ihn die Suche, selbst wenn er lediglich die Basistabellen findet, auf die entsprechenden Datenprodukte. Dies fördert eine benutzerfreundliche Navigation und stellt sicher, dass Datenprodukte leicht zugänglich sind, auch wenn der/die Benutzer:in nur die zugrunde liegenden Tabellen entdeckt. Der genaue Umfang der Suchergebnisse hängt jedoch von den im System definierten Berechtigungen und der jeweiligen Konfiguration ab. Diese ermöglichen es, den Zugriff auf spezifische Datenprodukte und -assets auf Grundlage von Sicherheitsrichtlinien zu steuern und anzupassen.
Der Vollständigkeit halber sei erwähnt, dass wir für die Bereitstellung des Marketingreports Apache NiFi verwenden. Diese Information, wie wir die Daten bereitstellen, wird in einem weiteren Blogbeitrag wichtig werden.
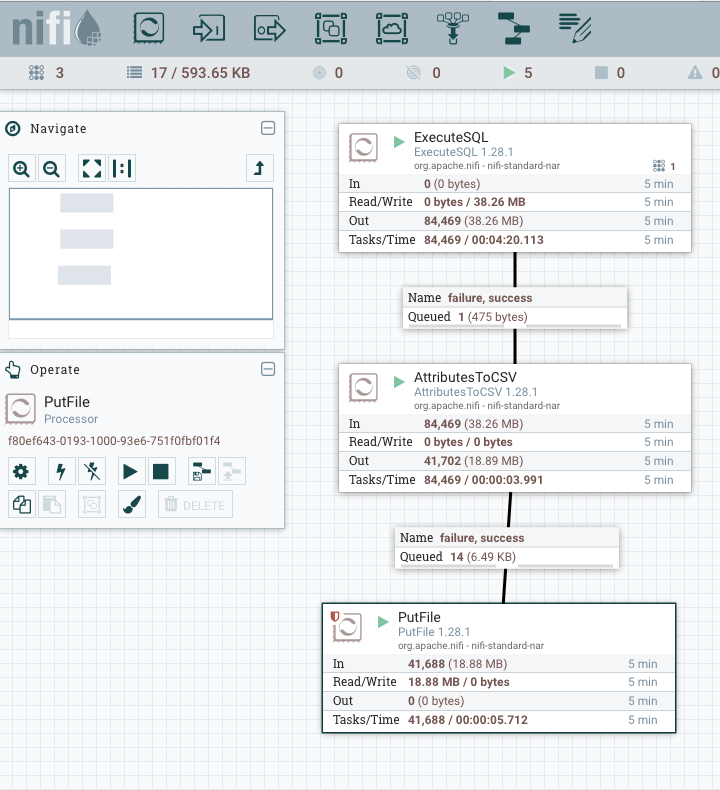
Fazit: Data Products als Brücke zwischen Daten und Business
Die Konzeption und Umsetzung von Data Products ist ein essenzieller Bestandteil moderner Data Governance. Sie übersetzen abstrakte Daten in konkrete Mehrwerte und schaffen eine solide Grundlage für datengetriebene Entscheidungen.
Die sakila-Datenbank hat uns dabei geholfen, ein einfaches Beispiel für die praktische Umsetzung zu illustrieren. In der Realität kann ein Data Product natürlich deutlich komplexer sein – von der Einbindung mehrerer Datenquellen bis zur Integration in Data Warehouses und BI-Tools. Doch der Ansatz bleibt gleich: klare Zielsetzung, saubere Daten, strukturierte Bereitstellung.
P.S. Shopaholic (2009); https://www.imdb.com/de/title/tt1093908/
Seminarempfehlungen
MYSQL ADMINISTRATION DB-MY-01
Mehr erfahrenDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Mehr erfahrenIT-ORGANISATION UND IT-GOVERNANCE - OPTIMIERUNG IHRER IT-ORGANISATION PM-28
Mehr erfahrenPrincipal Consultant bei ORDIX
Kommentare