
Dataproc, eine skalierbare Hadoop-Distribution in der Google Cloud
Dieser Artikel macht den Aufbau eines Dataproc Clusters in der GCP (Google Cloud Platform) verständlich und ermöglicht es dem Leser ein eigenes Dataproc Cluster in der GCP zu erstellen.
Was ist Dataproc?
Dataproc bietet eine vollständig verwaltete Plattform zur Verarbeitung großer Datenmengen, die in der GCP gehostet wird und eine nahtlose Integration mit anderen GCP-Services wie BigQuery, Cloud Storage und Stackdriver ermöglicht.
Des Weiteren ist Dataproc eine leistungsstarke Möglichkeit, Daten in Echtzeit zu verarbeiten und schnell zu analysieren. Durch die Bereitstellung von Apache Hadoop und Spark bietet Dataproc Nutzern eine Vielzahl von Tools und Bibliotheken, die speziell für die Verarbeitung großer Datenmengen entwickelt wurden. Damit können Benutzer schnell und einfach auf Daten zugreifen, sie verarbeiten und analysieren, ohne sich Gedanken über die zugrunde liegende Infrastruktur machen zu müssen.
Eine der größten Stärken von Dataproc ist die Skalierbarkeit. Die Plattform kann schnell auf sich ändernde Anforderungen reagieren und mehr Rechenleistung nutzen, wenn es erforderlich ist. Mit Dataproc können Benutzer ihre Hadoop-Cluster schnell und einfach einrichten, verwalten und skalieren. Eine Möglichkeit, dies selbst auszutesten, finden Sie am Ende des Artikels.
Dataproc stellt Hadoop entweder über ein Cluster aus virtuellen Maschinen (VM) oder ein Kubernetes-Cluster zur Verfügung. In diesem Blogartikel liegt der Fokus auf dem Aufbau eines Dataproc-Clusters mit VMs.
Woraus besteht ein Dataproc Cluster?
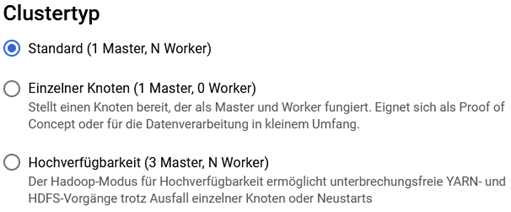
Ein Dataproc Cluster, der aus virtuellen Maschinen besteht, kann entweder eine oder drei Master-Nodes haben. Mit einer dreifachen Master-Node-Konfiguration wird die Hochverfügbarkeit des HDFS- und des YARN-Dienstes gewährleistet. Die Ausfallsicherheit des Clusters bleibt jedoch eingeschränkt, da sich alle Nodes in demselben Rechenzentrum befinden.
Zusätzlich zu den Master-Nodes besteht ein typischer Dataproc Cluster aus mindestens einem primären Worker. Diese Nodes sind normale Compute Engine-VMs. Es besteht auch die Möglichkeit, keine Worker-Nodes zu verwenden, indem die Variable "allow.zero.workers" auf "true" gesetzt wird.
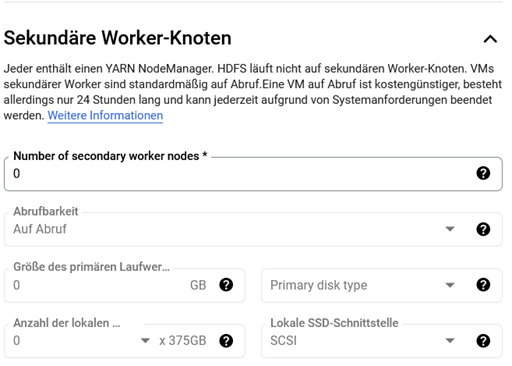
Neben den primären können auch sekundäre Worker enthalten sein, die jedoch im Vergleich zu den primären Workern einige Einschränkungen haben. Beispielsweise sind sie nicht in der Lage, Daten zu speichern. Der Nutzen sekundärer Worker liegt in der Skalierung von CPU und Arbeitsspeicher, ohne eben den Festplattenspeicher zu skalieren. Aufgrund der Einschränkungen darf ein Cluster nicht ausschließlich aus sekundären Workern bestehen. Diese basieren immer auf demselben Maschinentyp wie die primären Worker und verfügen über ein Bootlaufwerk von maximal 100 GB. Wenn das Bootlaufwerk der primären Worker kleiner als 100 GB ist, verfügen auch die sekundären Worker über ein Laufwerk dieser Größe. Der Speicherplatz des Bootlaufwerks kann vom HDFS nicht genutzt werden, da der Dataproc Cluster diesen nur zum lokalen Caching verwendet.
Wie skaliere ich einen Dataproc Cluster?
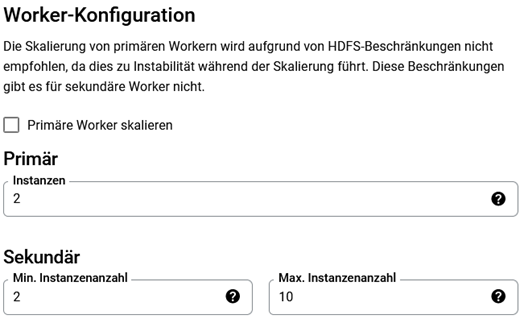
Sekundäre Worker sind besonders nützlich für die dynamische Skalierung des Clusters durch Skalierungsrichtlinien. Diese Richtlinien legen die minimale und maximale Anzahl von primären und sekundären Workern fest. Der ScaleUpFactor und ScaleDownFactor steuern die Skalierung innerhalb dieser Richtlinien. Beide Faktoren liegen zwischen null und eins. Je höher der Wert ist, desto schneller skaliert der Cluster.
Die Skalierung wird anhand der Auslastung des Arbeitsspeichers in YARN gestartet. Die Richtlinie überprüft in definierten Cooldown-Perioden den verfügbaren, zugewiesenen und reservierten Arbeitsspeicher in YARN. Wenn der ScaleDownFactor auf eins gesetzt wird, soll nach jeder Überprüfung und Skalierung möglichst wenig freier Arbeitsspeicher verfügbar sein. Sind beispielsweise fünf GB Arbeitsspeicher ungenutzt, werden laut Richtlinie so viele VMs entfernt, dass die gesamten fünf GB nicht mehr zur Verfügung stehen. Bei einem ScaleDownFactor von 0,5 würden lediglich VMs mit einer kumulierten Kapazität von 2,5 GB gelöscht. Das Gleiche gilt für den ScaleUpFactor und das Hinzufügen von VMs.
Welche zusätzlichen Komponenten bietet ein Dataproc Cluster?
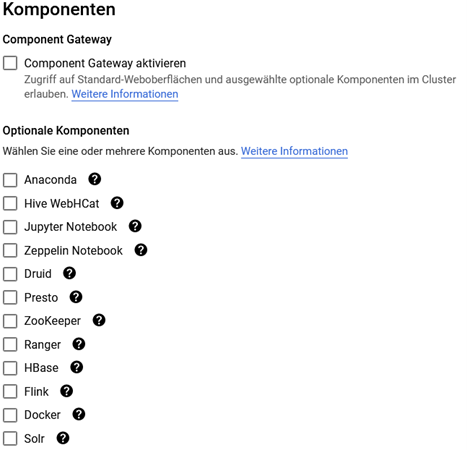
Es gibt mehrere optionale Komponenten, die bei der Erstellung eines Clusters ausgewählt werden können. ZooKeeper zum Beispiel ist ein Koordinationsservice für Hadoop und wird unter anderem zur Synchronisierung und Verwaltung von Service-Konfigurationen und -Informationen in hochverfügbaren Umgebungen genutzt.
Was sind Initialisierungsaktionen?

Dataproc ermöglicht außerdem das Definieren von Initialisierungsaktionen, die direkt nach der Bereitstellung des Clusters ausgeführt werden. Hierbei handelt es sich um Skripte zur Installation optionaler Dienste. Google bietet einige vordefinierte Skripte an, die verwendet werden können. Diese sind in den sogenannten Buckets abgelegt, aus denen der Cloud Storage besteht. Es wird empfohlen, diese Skripte aus dem jeweiligen öffentlichen Bucket in einen eigenen Bucket zu kopieren, um sicherzustellen, dass diese nicht verändert werden. Änderungen können dazu führen, dass der Cluster nicht mehr ordnungsgemäß startet.
Wie baue ich einen Beispielcluster auf?
Wenn Sie gerne eine Dataproc-Umgebung in der GCP aufbauen möchten, um Dataproc zu testen, können Sie hier ein Terraform-Skript für diesen Zweck finden:
https://gist.github.com/Dominik389/d4862b3d3bc95cc99d89d72e89d94bc5
Das Skript erstellt einen Dataproc Cluster mit zwei Worker-Nodes und einer Master-Node in der GCP. Der Cluster wird durch eine Skalierungsrichtlinie skaliert und enthält die optionalen Komponenten Zookeeper und HBase. Darüber hinaus wird Kafka mithilfe einer Initialisierungsaktion installiert. Das genaue Vorgehen ist in der Datei erläutert.
Fazit
Alles in allem ist Google Cloud Dataproc eine einfache Variante, einen individuellen Cluster mit Hadoop schnell aufzubauen. Dies eignet sich vor allem, um Tests und Anwendungen mit sehr volatilen Leistungsanforderungen auszuführen.
Seminarempfehlungen
HADOOP GRUNDLAGEN HADOOP-01
Zum SeminarCLOUD COMPUTING ESSENTIALS CLOUD-COMP
Zum SeminarJunior Consultant bei ORDIX
Kommentare