
Daten mit Format – Lösungen zur Datenablage in Hadoop
Durch das verteilte Dateisystem HDFS ermöglicht Hadoop die zuverlässige Ablage großer Datenmengen sowie die effiziente Abfrage der Daten durch paralleles Auslesen. Damit Hadoop selbst und andere Applikationen aus dem Big-Data-Umfeld von diesen Vorteilen profitieren können, müssen die verwendeten Dateiformate bestimmte Anforderungen erfüllen. Im Rahmen des Artikels wird anhand vier prominenter Dateiformate beleuchtet, wie diese Anforderungen auf unterschiedliche Art und Weise umgesetzt werden und welche Vor- und Nachteile die jeweilige Lösung mit sich bringt.
Hadoops Anforderungen
Im Big-Data-Umfeld hat sich Apache Hadoop in den vergangenen Jahren als eine zentrale Komponente etabliert. Einer der Gründe für die hohe Bedeutung ist das in Hadoop enthaltene verteilte Dateisystem HDFS (Hadoop Distributed Filesystem) zur Ablage und Nutzung großer Datenmengen innerhalb eines Clusters von Servern (Knoten). Durch die Aufteilung der zu speichernden Daten in HDFS-Blöcke sowie deren Verteilung und Replikation im Cluster wird sowohl eine hohe Verfügbarkeit als auch ein effizienter Zugriff auf die Daten ermöglicht. Andere Applikationen aus dem Big-Data-Umfeld, die Daten zwecks Weiterverarbeitung aus dem HDFS auslesen oder es als Ablage für ihre erzeugten Daten verwenden, profitieren von der verteilten und redundanten Speicherung in zweierlei Hinsicht:
•Durch die Aufteilung der Daten in HDFS-Blöcke können diese parallel verarbeitet werden, wodurch eine schnellere Verarbeitung selbst größerer Datenmengen ermöglicht wird. Zusätzlich kann die resultierende Last auf mehrere Knoten innerhalb des Clusters verteilt werden.
•Tasks und Jobs einer Applikation können im Cluster auf die Knoten verteilt werden, auf denen die notwendigen Daten liegen. Durch diese standortbewusste (engl. locality-aware) Datenverarbeitung wird weistestgehend vermieden, dass größere Mengen an Daten über das Netzwerk ausgetauscht werden müssen.
Da Hadoop, analog zu einem nativen Dateisystem, keine Vorgaben hinsichtlich des Dateiformats macht, bleibt es dem Nutzer überlassen, welche Daten er in welchem Format speichert. Gerade bei der Speicherung von zu verarbeitenden Daten ist es daher unerlässlich, dass diese in einem Format abgelegt werden, welches eine Aufteilung der Daten für die parallele und lokale Verarbeitung ermöglicht.
Neben der Aufteilung der Daten spielt auch deren Komprimierung eine wichtige Rolle. Durch die Komprimierung der Daten wird der Datenaustausch über das Netzwerk innerhalb eines Clusters minimiert und die Dauer lesender und schreibender Festplattenzugriffe reduziert. Gerade bei großen Datenmengen erweisen sich diese Operationen als äußerst zeitintensiv [Q1]. Als positiver Nebeneffekt benötigen die Daten zusätzlich weniger Speicherplatz im Cluster.
Anhand der skizzierten Anforderungen sollte ein ideales Dateiformat daher eine Komprimierung der Daten und deren Aufteilung in mehrere HDFS-Blöcke ermöglichen. Da ein Großteil der von Hadoop unterstützten Komprimierungsalgorithmen keine Aufteilung der Daten zur verteilten Speicherung erlaubt bzw. nur unter erheblichem Aufwand ermöglicht [Q2], wurden neue Dateiformate entwickelt, um beiden Anforderungen Rechnung zu tragen. Im Folgenden wird daher ein Überblick über prominente Dateiformate im Big-Data-Umfeld mit dem Fokus auf Hadoop gegeben. Als Grundlage werden zunächst einfache Textdateien beschrieben. Darauf aufbauend werdenSequenceFile-Dateien [Q3] als dedizierte Lösung für den Einsatz in Hadoop betrachtet. Abschließend werden mit Avro [Q4] und Parquet [Q5] stellvertretend zwei neuere Formate vorgestellt, welche die bisher betrachteten Ansätze beispielsweise hinsichtlich Einsatzmöglichkeiten und bereitgestellter Funktionalität übertreffen.
Textdateien
Textdateien stellen eine einfache Möglichkeit dar, um Daten in Hadoop abzulegen. Neben unstrukturierten und semistrukturierten Daten werden Textdateien häufig dazu verwendet, strukturierte Daten in Hadoop zu speichern. Dabei wird ein Datensatz innerhalb der Textdatei üblicherweise durch eine Zeile repräsentiert. Die Daten der vorhandenen Spalten innerhalb einer Zeile werden wiederum durch Trennzeichen identifiziert, z. B. durch Kommas bei CSV-Dateien. Aufgrund der beschriebenen Anordnung der Daten spricht man bei Textdateien auch von einem zeilenorientierten Datenformat.
Ein großer Vorteil gerade von flachen Textdateien, bei denen auf eine Verschachtelung der Daten wie z. B. in JSON- oder XML-Dateien verzichtet wird, resultiert aus der Simplizität sowie dem einfachen Lesen und Schreiben von Daten. Aufgrund dessen können Textdateien in mehrere HDFS-Blöcke aufgeteilt und im Cluster für eine parallele Verarbeitung verteilt werden.
Die großen Nachteile des Formats treten jedoch bei der Kodierung und Komprimierung der Daten innerhalb einerTextdatei auf. Hinsichtlich der Kodierung müssen die als Text gespeicherten Daten zur weiteren Verarbeitung immer in ihre eigentlichen Datentypen konvertiert werden. Ebenso verbraucht die Darstellung als Text gerade bei größeren Zahlen mehr Speicherplatz als bei einer binären Darstellung. Für eine Komprimierung der Textdateien muss ein Verfahren gewählt werden, welches das Lesen der komprimierten Daten auch noch nach deren Unterteilung in HDFS-Blöcke ermöglicht. Als ein mögliches Komprimierungsverfahren bietet sich hier vor allem bzip2 an. Jedoch wird die Funktionalität des Lesens komprimierter und geteilter Daten durch eine rechenaufwendige und langsame Komprimierung sowie Dekomprimierung erkauft [Q1].
SequenceFile
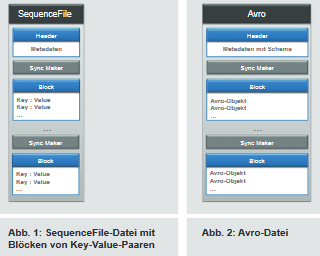
SequenceFile [Q3] ist ein Dateiformat, welches speziell für die Nutzung mit MapReduce entwickelt wurde, um den oben beschriebenen Nachteilen von Textdateien entgegenzuwirken. Als eines der ältesten binären Dateiformate für Hadoop [Q2] erlauben SequenceFile-Dateien, die enthaltenen Daten zu komprimieren und gleichzeitig in mehrere HDFS-Blöcke aufzuteilen.
Innerhalb einer SequenceFile-Datei werden die Daten als binär kodierte Key-Value-Paare abgelegt. Zur Serialisierung der Datentypen und -strukturen wird auf die in Hadoop existierenden Verfahren zurückgegriffen. Neben der Speicherung von Daten als Key-Value-Paare kann eine SequenceFile-Datei auch als Container für kleinere Dateien (z. B. Textdateien) dienen. Diese Funktionalität ist für das Zusammenfassen mehrerer kleinerer Dateien zu einer größeren sinnvoll, da Hadoop vor allem für die Arbeit mit einer geringeren Anzahl an größeren Dateien ausgelegt wurde [Q2].
Eine SequenceFile-Datei selbst besteht aus einem Headerund den eigentlichen Daten, die entweder als Records aus einzelnen Key-Value-Paaren oder als Blöcke be stehend aus mehreren Key-Value-Paaren gespeichert werden (siehe Abbildung 1). Um eine Mehrdeutigkeit des Begriffs Blocks zu vermeiden, wird ein Block im Kontext des betrachteten Dateiformats als Block bezeichnet. Für einen Block im HDFS wird weiterhin der Begriff HDFS-Block verwendet. Welches Verfahren zur Ablage der Key-Value-Paare innerhalb der Datei gewählt wird, richtet sich nach dem verwendeten Komprimierungsverfahren. Für den Fall, dass die Daten komprimiert werden sollen, kann zwischen der separaten Komprimierung eines jeden Records oder der Komprimierung eines kompletten Blocks gewählt werden.
Wie in Abbildung 1 dargestellt, werden zwischen einer gegebenen Anzahl von Records oder zwei Blöcken zusätzlich Sync- Marker gesetzt. Durch die Verwendung von Sync Markern können die Daten zwischen zwei Sync Markern (entweder mehrere Records oder ein Block) unabhängig von den restlichen Records und Blöcken komprimiert werden, da Anfang und Ende der Daten gekennzeichnet sind. Parallel dazu wird durch diese Markierung eine Aufteilung einer SequenceFile-Datei in mehrere HDFS-Blöcke ermöglicht, da nun nicht mehr die gesamte Datei, sondern nur noch Abschnitte komprimiert werden.
Wie bereits erwähnt, wurden SequenceFile-Dateien mit einem Fokus auf MapReduce-Jobs entwickelt. Ebenso wird für die Serialisierung der Daten ausschließlich auf die in Hadoop vorhandenen Verfahren zurückgegriffen, wodurch der Einsatz vor allem auf MapReduce-Jobs sowie Hadoop beschränkt ist. Vor diesem Hintergrund wurde mit Avro ein unabhängiges Dateiformat entwickelt, welches auch außerhalb von Hadoop eingesetzt werden kann und darüber hinaus den Zugriff aus unterschiedlichen Programmiersprachen ermöglicht.
Avro
Apache Avro [Q4] ist ein Serialisierungssystem, welches auf einem sprachenunabhängigen Schema basiert. Dieses Schema wird dazu verwendet, Datentypen und -strukturen zu definieren, welche im Rahmen der Serialisierung und Deserialisierung in Byte-Streams übersetzt werden und umgekehrt. Durch die sprachenunabhängige Definition des Schemas kann diese Übersetzung in einer beliebigen Programmiersprache geschehen. Serialisierung und Deserialisierung spielen einerseits bei der Interprozesskommunikation im Rahmen sogenannter Remote Procedure Calls (RPCs), aber auch in verteilten Systemen bei der Übertragung von Daten über das Netzwerk eine wichtige Rolle. Während Avro für beide Anwendungsfälle eingesetzt werden kann, beschränkt sich dieser Artikel auf den Einsatz von Avro in verteilten Systemen und beschreibt die Nutzung als Dateiformat in Hadoop.
Das Schema von Avro zur Beschreibung der Daten ist üblicherweise in JSON beschrieben. Darüber hinaus gibt es die Möglichkeit, das Schema mit der eigenen Interface Description Language zu definieren. Eine große Stärke des dabei generierten Schemas ist neben der Sprachenneutralität vor allem die Eigenschaft der Schema-Evolution. Das bedeutet, dass nach der initialen Definition des Schemas neue Datenfelder hinzugefügt bzw. obsolete Datenfelder ignoriert werden können. In letzterem Fall spricht man auch von einer Projektion, da die Anzahl der Datenfelder reduziert wird (Projektion eines höher dimensionalen Raums auf einen Raum mit weniger Dimensionen). Damit ermöglicht Avro, dass sich die zu schreibenden und lesenden Daten über den Lauf der Zeit ändern können, während der Code zur Analyse der Daten nicht angepasst werden muss. Innerhalb der Avro-Datei wird das Schema immer im Header der Datei abgelegt (siehe Abbildung 2), wodurch die Datei selbsterklärend ist. Das heißt, dass ohne vorherige Kenntnisse über das Schema die Daten dennoch gelesen und verarbeitet werden können.
Die eigentlichen Daten werden in einer Avro-Datei als Sequenz von Datensätzen, sogenannten Avro-Objekten, gespeichert. Innerhalb eines Avro-Objekts sind die Daten zeilenorientiert angeordnet und binär kodiert. Die Avro-Objekte werden wiederum in einem Block zusammengefasst. Wie in Abbildung 2 dargestellt, besteht eine Avro-Datei in der Regel aus mehreren Blöcken, die durch eindeutige Sync Marker voneinander getrennt werden. Wie bei einer SequenceFile-Datei ist es daher möglich, die Daten innerhalb eines Blocks bei Bedarf zu komprimieren, während durch die Sync Marker sicher gestellt wird, dass eine Avro-Datei mit ihren Blöcken in mehrere HDFS-Blöcke unterteilt werden kann. Durch die Möglichkeit der Komprimierung der Daten bei gleichzeitigem Splitten der Datei ist Avro ebenfalls für den Einsatz in Hadoop geeignet, im Gegensatz zu SequenceFile-Dateien aber nicht darauf beschränkt. Aktuell unterstützt Avro als Komprimierungsverfahren Snappy [Q6] und Deflate [Q7].
Parquet
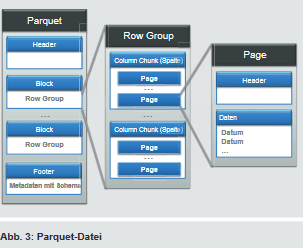
Parquet ist für ein breites Anwendungsspektrum entwickelt worden und nicht nur auf die Nutzung in Hadoop beschränkt. Dementsprechend werden die Metadaten zur Beschreibung des Dateiformats sowie der vorhandenen Daten wie bei Avro in einem sprachenneutralen Schema definiert. Als spaltenbasiertes Dateiformat ermöglicht Parquet auch die spaltenorientierte Darstellung verschachtelter Datenstrukturen, wie sie z. B. bei der Verwendung und Schachtelung von Maps entsteht. Zur Transformation in eine spaltenorientierte Darstellung greift Parquet auf die Algorithmen von Dremel zurück, welches ein von Google entwickeltes Framework zur Datenabfrage aus verschachtelten Datenstrukturen ist [Q8]. Durch diese Algorithmen können die Daten aller Datenfelder innerhalb einer geschachtelten Datenstruktur in einer eigenen Spalte abgespeichert werden. Somit ist anschließend beispielsweise das getrennte Einlesen von Keys und Values einer Map möglich.
Die eigentliche Parquet-Datei besteht aus einem Header, gefolgt von mehreren Blöcken mit den Daten und einem abschließenden Footer (siehe Abbildung 3). Durch die Speicherung des Schemas innerhalb der Datei sind die Daten wie bei Avro selbsterklärend, jedoch legt Parquet das Schema als Teil der allgemeinen Metadaten im Footer der Datei ab. Durch die Ablage im Footer wird sichergestellt, dass die Metadaten erst geschrieben werden, nachdem alle Daten innerhalb der Blöcke gespeichert wurden. Folglich sind Anfang und Ende eines jeden Blocks bekannt und werden in den Metadaten abgespeichert. Aufgrund dieser Informationen ist es im Gegensatz zu Avro und Sequence-File-Dateien nicht notwendig, Markierungen zwischen die einzelnen Blöcke zur Synchronisation zu schreiben. Da die Position von jedem Block aufgrund der Metadaten ermittelt werden kann, ist es möglich, eine Parquet-Datei auch ohne Markierungen in mehrere HDFS-Blöcke aufzuteilen. Zur Identifikation der einzelnen Blöcke muss daher zunächst immer das Ende einer Parquet-Datei gelesen werden, bevor auf die Daten zugegriffen werden kann.
Ein Block einer Parquet-Datei besteht aus einer einzigen sogenannten Row Group. Entsprechend des Namens umfasst eine Row Group eine variable Anzahl von Zeilen inklusive der darin enthaltenen Daten. Diese Daten sind, wie in Abbildung 3 dargestellt, pro Spalte in einem Column Chunk gruppiert, sodass die Anzahl an Column Chunks mit der Anzahl an Spalten übereinstimmt. Ein Column Chunk ist zusätzlich nochmal in Pages unterteilt, um geschachtelte Datenstrukturen bei Bedarf zu „glätten" und spaltenorientiert abzuspeichern (siehe Abbildung 3). Die flachen, spaltenorientierten Daten innerhalb einer Page werden von Parquet in einem zweistufigen Verfahren komprimiert. In einem ersten Schritt wählt Parquet eine geeignete Kodierung zur Repräsentation der Daten (siehe [Q9] für verfügbare Kodierungen). In einem zweiten Schritt können die kodierten Daten zusätzlich komprimiert werden. Als mögliche Verfahren stehen in Parquet Snappy [Q6], gzip [Q10] und LZO [Q11] zur Komprimierung zur Verfügung. Innerhalb eines Column Chunks können dabei pro Page unterschiedliche Kodierungs- und Komprimierungsverfahren verwendet werden
Fazit
Im Rahmen dieses Artikels wurde neben gewöhnlichen Textdateien anhand drei prominenter Beispiele beleuchtet, wie sich die Dateiformate weiter entwickelt haben, um in Hadoop zum Einsatz zu kommen. Innerhalb der Betrachtung wurde deutlich, dass abgesehen von Textdateien alle drei Dateiformate die zu Beginn des Artikels identifizierten Anforderungen umsetzen. Durch die Teilbarkeit der Daten bei gleichzeitiger Komprimierung unterstützen die Formate die parallele und lokale Verarbeitung und reduzieren die Last auf das Netzwerk und die Festplatten des Clusters. Ebenso zeigt die Betrachtung, dass sich die Formate von dedizierten Lösungen zu generell einsetzbaren Dateiformaten entwickelt haben. Während bspw. SequenceFile-Dateien speziell für MapReduce-Jobs und Hadoop konzipiert wurden, zeichnen sich neuere Formate wie Avro oder Parquet durch ihre vielfältigen Einsatzmöglichkeiten sowie durch eine deutlich höhere Flexibilität und Funktionalität aus. Erwähnt sei hier der sprachenunabhängige Datenzugriff oder die Möglichkeit der Schema-Evolution, die eine Modifikation existierender Schemata über den Lauf der Zeit erlaubt.
Welches von den vorgestellten Dateiformaten letzten Endes das beste Format ist, lässt sich nicht pauschalisieren, da dies unter anderem von der Art der Analyse oder aber auch von der Unterstützung der genutzten Applikationen abhängt. So sollte beispielsweise bei der Wahl des Dateiformats geprüft werden, ob das Dateiformat mit der gewählten Applikation und der zugrundeliegenden Programmiersprache gelesen und geschrieben werden kann. Ebenso ist zu berücksichtigen, ob die geplanten Analysen auf den Daten einzelner oder vieler Spalten operieren. Wie im Abschnitt zu Parquet erwähnt, bieten sich für Operationen auf wenigen Spalten spaltenorientierte Formate an, während zeilenorientiere Formate bei Operation über viele Spalten hinweg vorzuziehen sind.
Quellen
[Q1] Mark Grover et al.: „Hadoop Application Architectures"; 1. Auflage; Sebastopol: O'Reilly Media; 2015
[Q2] Tom White: „Hadoop: The Defi nitive Guide"; 4. Aufl age; Sebastopol: O'Reilly Media; 2015
[Q3] http://hadoop.apache.org/docs/current/api/index.html?org/apache/hadoop/io/SequenceFile.html
[Q4] https://avro.apache.org/
[Q5] https://parquet.apache.org/
[Q6] http://google.github.io/snappy/
[Q7] https://www.gnu.org/software/gzip/manual/gzip.html
[Q8] Sergey Melnik et al.: „Dremel: Interactive Analysis of Web-Scale Datasets"In: Proceedings of the VLDB Endowment. 3, 1-2, pp. 330-339
[Q9] https://github.com/Parquet/parquet-format/blob/master/Encodings.md
[Q10] http://www.gzip.org/
[Q11] https://de.wikipedia.org/wiki/Lempel-Ziv-Oberhumer
Kommentare