
Machen Sie sich keinen Kopf: Datenbankbetrieb mit Hilfe von künstlicher Intelligenz
Unsere Oracle-Expert:innen analysieren tagtäglich den Betrieb von Datenbanksystemen und helfen unseren Kunden bei Performance-Problemen. Oftmals stellt sich heraus, dass sich die gefühlt spontan auftretenden Probleme doch im Vorfeld angekündigt haben. Jedoch ist es in vielen Fällen nicht ganz trivial diese „Vorzeichen" zu erkennen.
Aus diesem Grund entstand die Idee, die technischen Meta-Daten der Datenbanken mit modernen Methoden des Data Analytics und Artificial Intelligence (AI) zu untersuchen, um nach solchen Hinweisen Ausschau zu halten.
Ist das nicht ein Bisschen zu künstlich? AIOps
Der Einsatz von AI zur Unterstützung des IT-Monitorings und der Automatisierung hat sich unter dem Schlagwort „AIOps" etabliert. Dabei werden sowohl historische als auch Echtzeit-Daten genutzt, um Zusammenhänge nachzuweisen und prekäre Situationen der Systeme zu erkennen, sodass proaktiv eine Alarmierung der zuständigen Mitarbeitenden möglich ist, oder sogar, falls möglich und sinnvoll, um automatisch Gegenmaßnahmen einzuleiten.
Bei den Daten, die zur Untersuchung verwendet wurden, handelt es sich um automatisiert bereitgestellte (Performance)-Metriken des Datenbanksystems selbst, die hochfrequent als Zeitreihen gespeichert und analysiert wurden. Diese zeichnet aus, dass sie diverse Messwerte enthalten, die nach zeitlichem Auftreten sortiert sind.
Wer wird denn so neugierig sein? Explorative Datenanalyse (EDA)
Der erste Schritt bei der Analyse durch die Data Scientists stellt die Explorative Datenanalyse (EDA) dar.
Bevor die Daten einer EDA unterzogen werden können, müssen sie vorbereitet werden. Bei der Integration der Daten werden Informationen aus verschiedenen Subsystemen der zu untersuchenden Datenbank-Engine zusammengeführt. Die in den Daten jeweils enthaltenen Zeitstempel werden genutzt, um die Informationen aus verschiedenen Quellen zu einem zeitkonsistentem Gesamtdatensatz zu integrieren. Bei der Aufbereitung der Daten werden unterschiedliche Transformationen angewendet. Teils werden die Werte, ohne Berücksichtigung des zeitlichen Zusammenhangs, mittels einer mathematischen Funktion abgebildet, um zu große Wertebereiche zu stauchen. Andere Transformationen nutzen ein Zeitfenster, das über den zeitlichen Verlauf der Daten bewegt wird, um beispielsweise eine Glättung durchzuführen. Der so errechnete gleitende Mittelwert beseitigt störende Schwankungen, kann aber auch zu Fehlinterpretationen führen.
Mit den aufbereiteten Daten können dann weitere Untersuchungen durchgeführt werden. Mittels der Zeitreihendekomposition wird der Verlauf eines Wertes in drei Komponenten zerlegt. Das Ergebnis dieses Vorgangs sind der Trend, die Saisonalität, sowie nicht durch erstere erklärbare Restschwankungen, die sogenannten Residuen. Bei der Saisonalität handelt es sich um ein zyklisch wiederkehrendes Muster, wie es durch die Urlaubszeit oder Wochenenden für gewöhnlich an vielen Stellen erkennbar ist.
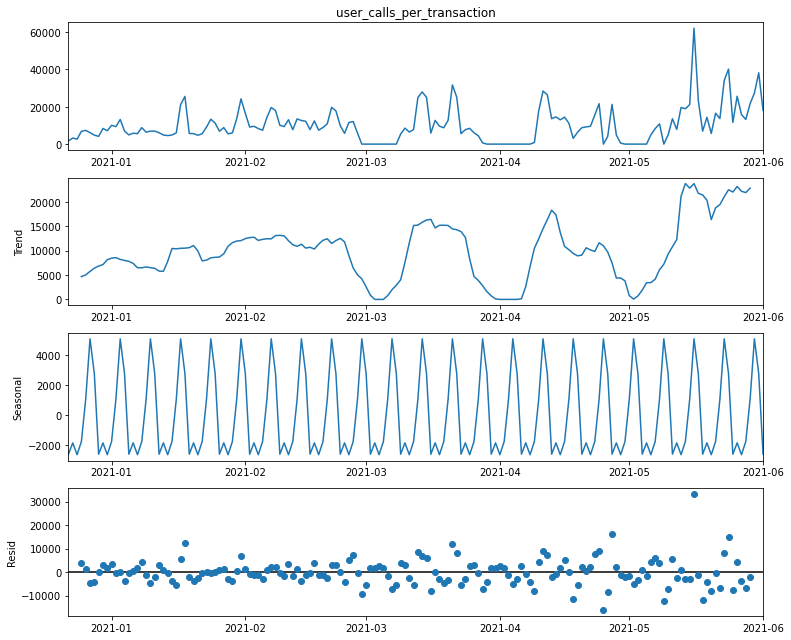
Das Beispiel oben stellt die Zerlegung der Zeitreihe nachvollziehbar dar: Das erste Diagramm zeigt die Originaldaten. Darunter ist der Trend, der die zum jeweiligen Zeitpunkt vorhandene Tendenz des Messwertes abbildet. Trotz Lücken in der Zeitreihe ist hier ein steigender Trend zu erkennen. Im dritten Plot ist die Saisonalität dargestellt, die einen gleichförmigen, zyklischen Verlauf aufzeigt. In diesem Beispiel deutet der Plot auf eine wöchentliche Saisonalität hin. Die unterste Darstellung zeigt die Residuen. Dies sind die Abweichungen des originalen Verlaufs, die durch Trend und Saisonalität nicht zu erklären sind.
So können aus den Daten Signale extrahiert werden, um im weiteren Schlussfolgerungen abzuleiten. Dem Aufspüren von Zusammenhängen verschiedener Signale kommt eine große Bedeutung zu. Man spricht hier von den Korrelationen zweier oder mehrerer Werte. Diese Korrelationen können aus inhaltlicher, fachlicher Sicht bekannt sein. Andere noch unbekannte Zusammenhänge können so aber auch gefunden werden. Diese Erkenntnisse ermöglichen die Entwicklung von Methoden, mittels derer kritische Zustände schon potentiell frühzeitig erkannt werden können.
Nun aber schnell: Oracle-Performance
Der Nutzen von EDA wird im Folgenden an einem interessanten Beispiel einer Analyse von Oracle-Performance-Daten verdeutlicht. Aufgetretene Performance-Probleme in einer Oracle-Datenbank konnten hier mit den standardmäßig verfügbaren Möglichkeiten nicht effizient analysiert werden.
Die Nutzenden klagten über teilweise sehr lange Wartezeiten bei der Arbeit mir ihrer Applikation.
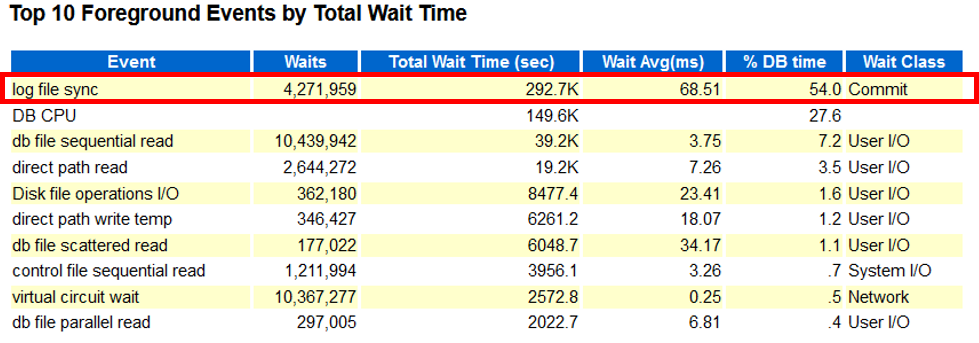
Der Auszug aus dem Oracle-eigenem AWR-Report zeigt hohe Werte für Commit (log file sync). Dennoch konnte mit den vorliegenden Informationen der Grund für die von den Benutzern reklamierten langen Wartezeiten nicht befriedigend erklärt werden.
Zahlen lügen nicht: Erkenntnisse
Durch eine EDA der Performance-Werte, die in verschiedenen Oracle-Views (systemeigene Messewerte der Oracle-Datenbank) verfügbar sind, wie z.B. v$sysstat, v$system_event und in diesem Fall v$iostat_function, konnte eine stichhaltige Hypothese für den Grund des Problems aufgestellt werden, die sich später bestätigte.
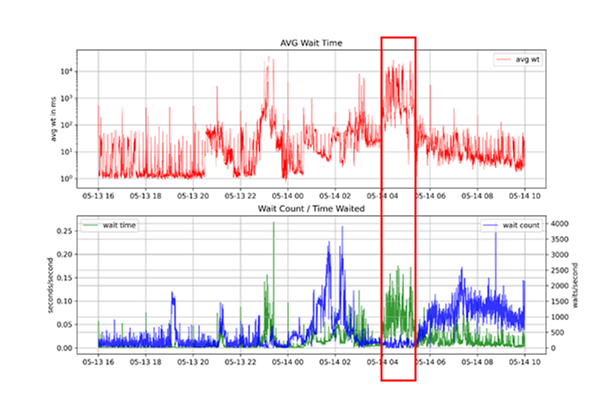
Die Darstellung der durchschnittlichen Wartezeiten für Commits (avg wt) zeigt stark schwankende Werte im Bereich von 1 – 50.000 ms (die Darstellung ist logarithmisch). Die hingegen im AWR-Report aufgelistete durchschnittliche Wartezeit von 68,51 ms über den Zeitraum von 16:00 – 10:00 Uhr ist in keiner Art und Weise hilfreich und zielführend.
Der Zeitraum, für den Leistungseinbuße gemeldet wurden, spiegelt sich in der Zeit von 4 bis 5:30 Uhr morgens, gut erkennbar in den Daten, wider. Um die Kausalität des Anstiegs der Wartezeiten zu bestimmen, müssen weitere Untersuchungen unternommen werden.
Der Gordische Knoten
Im besagten Zeitraum schnellt die Wartezeit hoch, obwohl die Anzahl der Waits sehr niedrig ist. Um zu verstehen, warum es zu diesem Performance-Problem kommt, müssen weitere Werte betrachtet werden, die im AWR nicht gezeigt werden. Die Untersuchung der Werte aus der v$iostat_function zeigt die Ursache für die erhöhten Wartezeiten. Der Log Writer muss große Mengen Redo schreiben (bis zu über 700MB/s). Warum die Wartezeiten nicht bereits im Vorfeld ansteigen, ist Gegenstand weiterer Untersuchungen.
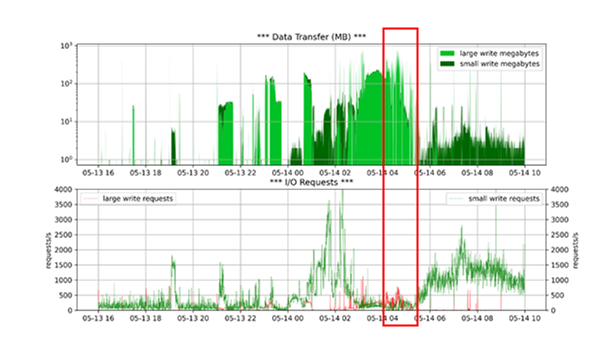
Die in roten Boxen markierten Verläufe zeigen eine Korrelation, die auf die oben beschriebene Kausalität hindeutet. Können diese Muster im Betrieb detektiert werden, so ist es möglich, frühzeitig Gegenmaßnahmen zu ergreifen, bevor der Kunde die Auswirkungen bemerken kann.
Genau hingeschaut
Erst mittels der hohen Abtastrate, die durch die eigenen Auswertungen, im Vergleich zu AWR möglich ist, können diese Zusammenhänge als Grund für die Störung ausgemacht werden. Die stark geglättete mittlere Wait Time, wie sie in Oracle-eigenen Reports verwendet wird, kann irreführende Eindrücke vermitteln, bzw. Ursachen unkenntlich machen.
Algorithmen sehen mehr
Aktuell werden Verfahren untersucht, mit denen eine solche Störung automatisch erkannt werden kann. Dafür geeignet sind Ansätze, die den zeitlichen Verlauf von Key-Performance-Indikatoren (KPI) vorhersagen können, als auch Algorithmen der Anomalie-Erkennung. Wir werden in folgenden Beiträgen davon berichten.
Wir helfen gerne
Sie haben Probleme beim Betrieb Ihrer Datenbanken oder möchten mehr über das Thema Performance-Monitoring und – Optimierung erfahren? Dann sprechen Sie uns an.
Falls Sie Interesse an einer Weiterbildung zu diesem Thema haben, bieten wir Ihnen die passenden Seminare:
Machine Learning Basics Seminar Oracle Tuning Seminar
Kommentare