
Datenmigration nach Exasol: Welche Migrationsmöglichkeiten gibt es? – Teil 1: Exasol-SQL-Statements
Exasol ist eine relationale Datenbank, die für schnelle Datenanalysen optimiert ist. Durch die In-Memory-Verarbeitung ist die Exasol-Datenbank hochperformant und wird als schnellste Analytics Database der Welt beworben. In den TPC-H-Benchmarks erreicht die Exasol-Datenbank seit Jahren Platz 1. Daher lohnt es sich, eine Datenmigration nach Exasol in Betracht zu ziehen. Doch welche Möglichkeiten gibt es, Daten in die Exasol-Datenbank zu importieren?
Durch Exasol-spezifische SQL-Statements können Daten aus verschiedenen Quellen ohne zusätzliche Tools importiert werden. Einige dieser Wege zur Datenmigration werden in diesem Teil des Blogartikels vorgestellt. In einem zweiten Teil werden die Migrationswege mithilfe von ETL-Tools betrachtet.
Ausgangssituation
In unserem Beispiel liegen Daten in verschiedenen Quellen vor, die nach Exasol überführt werden sollen. Dazu gehören lokale CSV-Dateien, Daten in einer PostgreSQL-Datenbank und Daten aus einer Hadoop-Umgebung. In der Hadoop-Umgebung liegen die Daten in verschiedenen Dateiformaten im HDFS vor. Möchten Sie selbst einige Migrationsmöglichkeiten ausprobieren, können Sie sich die kostenlose Exasol-Community-Edition von hier herunterladen.
Import einer lokalen CSV-Datei
Exasol bietet die Möglichkeit, eine CSV-Datei mittels eines einfachen IMPORT-Statements aus dem lokalen Speicher in die Datenbank zu importieren.
Dafür muss zunächst die Tabelle mit der entsprechenden Struktur in der Exasol-Datenbank angelegt werden. Ist die Tabelle erstellt, kann das IMPORT-Statement ausgeführt werden. Dieses ist wie folgt aufgebaut:
IMPORT INTO <Zieltabelle> FROM LOCAL CSV FILE '/Pfad/zur/Datei.csv' <Optionen>;
Mithilfe der Optionen können beispielsweise Trennzeichen für die Spalten und Zeilen angegeben werden. Ein vollständiges IMPORT-Statement könnte dann wie folgt aussehen:
IMPORT INTO ordix.CSV_TABELLE FROM LOCAL CSV FILE ‘C:\Users\ordix\CSV_TABELLE.csv‘ ROW SEPARATOR = ‚CRLF‘ COLUMN SEPARATOR = ‘|‘;
Wird eine CSV-Datei in die Exasol-Datenbank importiert, muss die geringe Fehlertoleranz beachtet werden. Stimmen Datentypen oder die Anzahl der Spalten in CSV-Datei und Tabelle nicht überein, wird eine Fehlermeldung ausgegeben und die Daten werden nicht importiert.
Exasol bietet darüber hinaus die Möglichkeit, CSV-Dateien von anderen Servern zu importieren.
Import aus fremden Datenbanken
Exasol bietet ebenfalls die Möglichkeit an, eine Verbindung zu einer anderen Datenbank herzustellen und die gewünschten Daten unmittelbar aus dieser Datenbank zu importieren. Im folgenden Abschnitt wird dieses Migrationsverfahren am Beispiel einer PostgreSQL-Datenbank erläutert.
Zunächst muss der JDBC-Treiber der Quelldatenbank in der EXAoperation-Weboberfläche hinzugefügt werden.
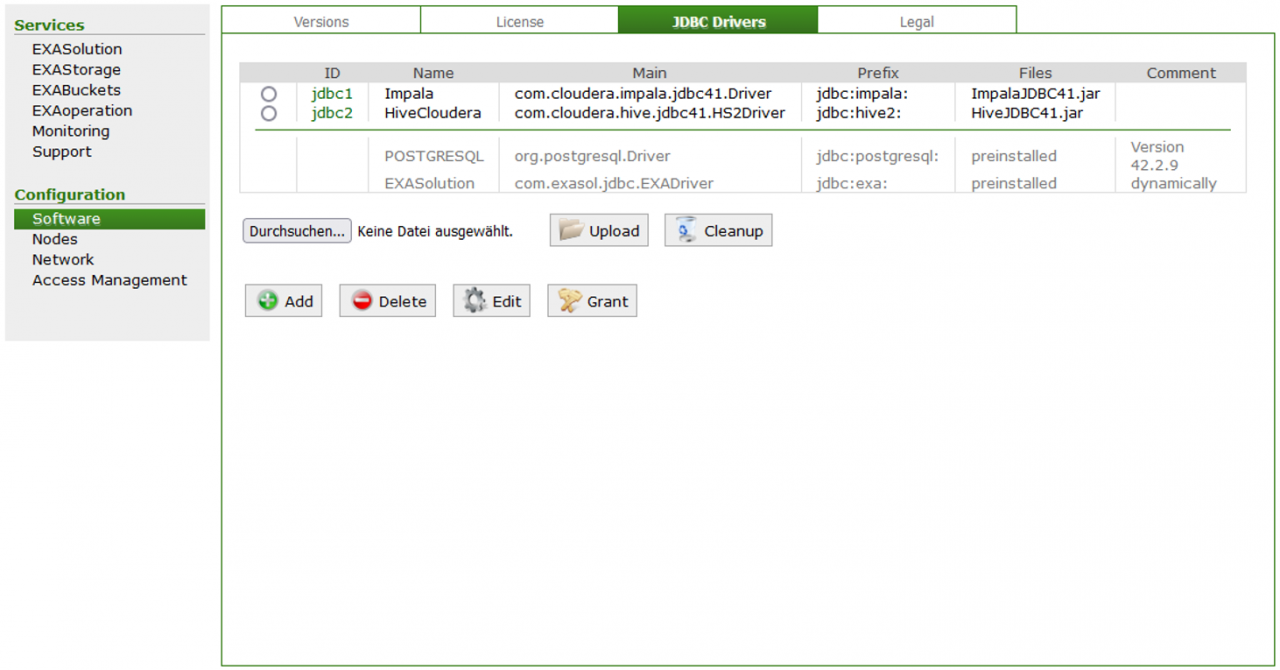
Dann kann eine Verbindung zu der Quelldatenbank angelegt werden. Dafür wird folgendes Statement verwendet:
CREATE OR REPLACE CONNECTION <Verbindungsname> TO ‘<Connection-URL>‘ USER ‘<username>‘ IDENTIFIED BY ‘<password>‘;
Ein vollständiges Statement für Import aus einer PostgreSQL-Datenbank sieht wie folgt aus:
CREATE OR REPLACE CONNECTION JDBC_POSTGRESQL TO ‘jdbc:postgresql://192.168.56.100:5432/my_db‘ USER ‘<username>‘ IDENTIFIED BY ‘<password>‘;
Um sicherzustellen, dass die Verbindung erfolgreich hergestellt werden kann und Daten aus der Quelldatenbank importiert werden können, sollte die Verbindung mit folgendem Statement getestet werden:
SELECT * FROM (IMPORT FROM JDBC AT JDBC_POSTGRESQL STATEMENT ‘select ‘‘Connection works‘‘ ‘ );
Sobald erfolgreich eine Verbindung aufgebaut wurde, können Daten mithilfe des IMPORT-Statements aus der Quelldatenbank importiert werden.
IMPORT INTO <Zieltabelle> FROM JDBC AT <Verbindungsname> TABLE <Quelltabelle>;
Ein vollständiges IMPORT-Statement sieht wie folgt aus:
IMPORT INTO exasolschema.tabelle1 FROM JDBC AT JDBC_POSTGRESQL TABLE postgresschema.tabelle1;
Hierbei ist zu beachten, dass die Zieltabelle bereits in Exasol erstellt sein muss. Dieses Verfahren steht für alle Datenbanken mit JDBC-Treiber zur Verfügung, so z.B. auch für Microsoft SQL-Server, MySQL oder Hive.
Im Gegensatz zum Import der CSV-Datei ist Exasol bei diesem Importverfahren deutlich fehlertoleranter. Beim Import wird hier nicht auf die Spaltennamen, sondern auf den Spaltenindex geachtet. Dadurch müssen die Spaltennamen für den Import nicht zwingend übereinstimmen. Auch die Datentypen können teilweise in Quell- und Zieldatenbank abweichen. Trotzdem ist ein Import möglich, beispielsweise bei Date- und Timestamp-Formaten. Ist der Datentyp der Zielspalte zu kurz, beispielsweise bei einem VARCHAR, wird eine Fehlermeldung ausgegeben und die Daten werden nicht importiert. Auch Differenzen in der Anzahl der Spalten führen zu Fehlermeldungen.
Import mit einem virtuellen Schema
Es besteht zudem die Möglichkeit, ein virtuelles Schema anzulegen und die Daten darüber zu importieren. Virtuelle Schemata ermöglichen den Zugriff auf externe Datenquellen durch SQL-Befehle. Dafür wird der Inhalt der externen Datenquelle in virtuellen Tabellen abgebildet. Diese virtuellen Tabellen können wie normale Exasol-Tabellen durch SQL-Statements abgefragt werden.
Um ein virtuelles Schema zu erstellen, muss zunächst der JDBC-Treiber der Datenquelle in EXAoperation und in BucketFS, das Dateisystem von Exasol, hochgeladen werden. Zudem muss eine „virtual schema jar“-Datei der Quelldatenbank in BucketFS hochgeladen werden.
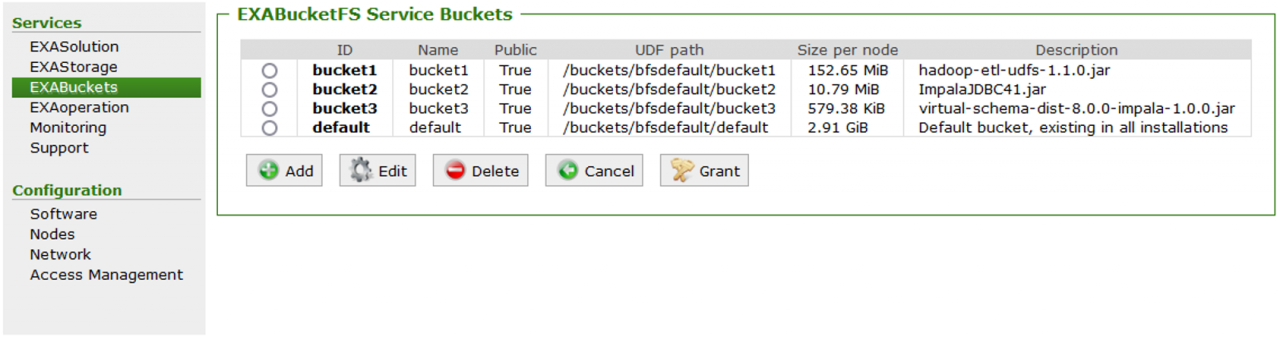
Danach kann mit der Installation des Adapter-Skriptes begonnen werden. Hierfür muss zunächst ein Schema angelegt werden, in welchem das Adapter-Skript installiert werden soll. Dann wird das Adapter-Skript mit folgendem Befehl installiert:
--/ CREATE JAVA ADAPTER SCRIPT <SCHEMA_FOR_VS_SCRIPT>.JDBC_ADAPTER_SCRIPT AS %scriptclass com.exasol.adapter.RequestDispatcher; %jar /buckets/your-bucket-fs/your-bucket/virtual-schema-dist-<version>-<dialect>- <version>.jar; %jar /buckets/your-bucket-fs/your-bucket/<JDBC driver>.jar; /
Ist das Adapter-Skript erstellt, muss eine JDBC-Verbindung angelegt werden. Das Statement ist identisch zum Statement im vorangegangenen Abschnitt zum Import aus einer anderen Datenbank.
Nun wird das virtuelle Schema erstellt. Hierfür wird das folgende Statement verwendet:
CREATE VIRTUAL SCHEMA VS_TEST USING <SCHEMA_FOR_VS_SCRIPT>.JDBC_ADAPTER_SCRIPT WITH CONNECTION_NAME = 'JDBC_CONNECTION' SCHEMA_NAME = '<SCHEMA_NAME>';
Mit Exasol-SQL-Statements können die Daten jetzt verarbeitet werden. Dabei verhalten sich die virtuellen Tabellen wie normale Exasol-Tabellen. Mit folgendem SQL-Statement werden Daten beispielsweise in die Exasol-Datenbank geladen:
CREATE TABLE materialized_schema.my_table AS SELECT * FROM virtual_schema.my_table;
Virtuelle Tabellen werden mit dem SELECT-Statement selektiert. Auch ein Join zwischen einer Exasol-Tabelle und einer virtuellen Tabelle ist möglich.
Import aus Hadoop
Sollen Dateien aus dem HDFS in die Exasol-Datenbank importiert werden, werden Hadoop-ETL-UDF-Skripte benötigt. UDF-Skripte sind User-Defined-Functions, welche selbst programmiert werden. Exasol stellt die Hadoop-ETL-UDFs zum Import aus dem HDFS auf GitHub zur Verfügung. Nach der Installation der Skripte ist es möglich, die Dateien aus dem HDFS mithilfe eines IMPORT-Statements in die Exasol-Datenbank zu laden.
Weitere Informationen zur Installation und Verwendung der Hadoop-ETL-UDFs gibt es in der Exasol Dokumentation und dem GitHub-Repository.
Ausblick
Die Datenmigration in eine Exasol-Datenbank ist mithilfe der Exasol-Import-Statements unkompliziert und mit wenig Aufwand umsetzbar. Migrationsmöglichkeiten mithilfe von ETL-Tools werden im bald erscheinenden zweiten Teil des Blogartikels vorgestellt. Dabei werden Apache NiFi, Talend Open Studio for Data Integration und Talend Open Studio for Big Data betrachtet.
Seminarempfehlungen
HADOOP GRUNDLAGEN HADOOP-01
Zum SeminarHADOOP ADMINISTRATION HADOOP-02
Zum SeminarDATA WAREHOUSE GRUNDLAGEN DB-DB-03
Zum SeminarJunior Consultant bie ORDIX
Kommentare