
Profilieren statt ignorieren: Die PostgreSQL Extension „pg_profile“
Beim Betrieb von Datenbanken geht es oft um die Frage nach der Performance. Anwender beschweren sich über spontan auftretende „Langläufer“ oder die CPU des Servers „läuft gerade mal wieder heiß“. Nun ist der DBA gefordert und muss schnell Auskunft darüber geben, was auf der Datenbank im monierten Zeitraum „los war“. Ein sehr nützliches Mittel, um Antworten geben zu können, ist „pg_profile“.
Vorbereitung ist alles
Die Extension „pg_profile“ sammelt Metriken zu bestimmten Zeitpunkten (auch „samples“ genannt). Über zwei gewählte Zeitpunkte kann dann ein Report generiert werden, der Auskunft darüber gibt, wie sich das System zwischen diesen Messzeitpunkten verhalten hat. Damit die Extension genutzt werden kann, muss sie natürlich zuerst „installiert“ werden. „pg_profile“ ist zusätzlich abhängig von einigen anderen Erweiterungen:
Innerhalb unseres PostgreSQL-Testclusters haben wir die Datenbank „example“ angelegt und dort die folgenden Extensions installiert:
psql example -c "select * from pg_extension;" oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition -------+--------------------+----------+--------------+----------------+------------+-----------+-------------- 13743 | plpgsql | 10 | 11 | f | 1.0 | | 16500 | pg_stat_statements | 10 | 2200 | t | 1.9 | | 16525 | dblink | 10 | 2200 | t | 1.2 | | 16571 | pg_profile | 10 | 2200 | f | 0.3.6 | |
Für die nachfolgenden (Code-)Beispiele haben wir innerhalb dieser DB mit dem Werkzeug „pgbench" ein kleines Datenmodell erzeugt:
pgbench -i -s 50 example
Zu einem späteren Zeitpunkt werden wir mit diesem Benchmark-Tool auch Last auf dem Cluster erzeugen.
Zusätzlich sind einige Parameter für den Einsatz der Erweiterung zu setzen, bzw. zu überprüfen. Die folgenden Einstellungen sollten so gegeben sein:
track_activities = on track_counts = on track_io_timing = on track_wal_io_timing = on track_functions = all
Auch die Extension an sich kann konfiguriert werden. So kann z.B. die „Retention“ (also wie lange Daten aufgehoben werden), oder wie umfangreich (z.B. wie viele Statements sollten pro Kategorie dargestellt werden) diese sein soll, eingestellt werden. Für diesen Blog-Beitrag konzentrieren wir uns auf die „Werkseinstellungen“. Detaillierte Informationen können der Dokumentation entnommen werden: https://github.com/zubkov-andrei/pg_profile/blob/master/doc/pg_profile.md
Bitte recht freundlich …
Nachdem die vorbereitenden Tätigkeiten abgeschlossen sind, ist es an der Zeit den ersten „Schnappschuss“ von Daten zu nehmen. Dafür wird die Funktion „take_sample()“ bereitgestellt.
example=# select take_sample();
take_sample
------------------------
(local,OK,00:00:00.44)
(1 row)
Um einen Überblick über die bereits erstellten Messzeitpunkte zu erhalten, gibt es eine weitere Funktion:
example=# SELECT * from show_samples();
sample | sample_time | sizes_collected | dbstats_reset | clustats_reset | archstats_reset
--------+------------------------+-----------------+---------------+----------------+-----------------
1 | 2022-05-03 15:21:50+00 | t | | |
...
12 | 2022-05-03 16:10:31+00 | t | | |
(12 rows)
Action bitte …
Nun werden wir ein kleines Lasttest-Szenario mit „pgbench“ aufbauen, welches wir im Nachgang auswerten wollen. Dazu werden wir vor und nach dem Test jeweils einen „Schnappschuss“ erstellen. Dazu haben wir hier ein sehr minimalistisches Skript entwickelt.
bash> cat bench.sh #!/bin/bash # # sample before benchmark psql -c "SELECT take_sample()" example psql -c "select 'ID before benchmark: ' as Msg, max(sample) as ID from (select * from show_samples() ) as tmp;" example # run benchmark pgbench --client=25 --jobs=25 --transactions=250 example # sample after benchmark psql -c "SELECT take_sample()" example psql -c "select 'ID after benchmark: ' as Msg, max(sample) as ID from (select * from show_samples() ) as tmp;" example
Vor und nach dem Test mit pgbench werden die IDs (Schnappschüsse) 13 und 14 erstellt.
postgres@707d93465897:~$ bash bench.sh
msg | id
-----------------------+----
ID before benchmark: | 13
(1 row)
pgbench (14.2 (Debian 14.2-1.pgdg110+1))
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 50
query mode: simple
number of clients: 25
number of threads: 25
number of transactions per client: 250
number of transactions actually processed: 6250/6250
latency average = 26.792 ms
initial connection time = 60.308 ms
tps = 933.099038 (without initial connection time)
msg | id
----------------------+----
ID after benchmark: | 14
(1 row)
Wer schreibt, der bleibt …?
Okay, die Daten sind gesammelt. Nun ist es an der Zeit den Report zu schreiben, bzw. zu erstellen. Auch für diesen Vorgang steht eine Funktion zur Verfügung.
psql -qtc "SELECT get_report(13,14, 'Blog Beispiel')" --output /tmp/report_postgres_13_14.html example
Wie an der Endung der Ausgabedatei unschwer zu erkennen ist, erfolgt der Report im HTML Format.
Der Report gliedert sich in unterschiedliche Teile und erinnert an das entsprechende Pendant von Oracle: AWR-Reports (Automatic Workload Repository). Die untenstehende Grafik zeigt einen Teil der unterschiedlichen Kategorien, die im Report enthalten sind. Neben allgemeinen Server-Statistiken, werden natürlich auch SQL Queries nach unterschiedlichen Kriterien (Ausführungszeit, I/O Aktivität, ….) analysiert. So lassen sich schnell problematische Statements nach verschiedenen kritischen Ressourcen (CPU, I/O, Sperren) identifizieren.

Die folgende Abbildung zeigt einen beispielhaften Report der Queries gemäß deren Ausführungszeiten analysiert:
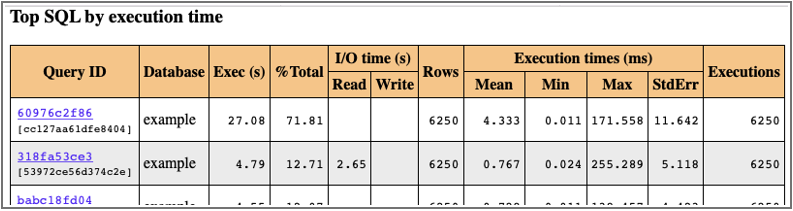
Wer schreibt, der bleibt …!
Aus unserer Sicht ist die Extension „pg_profile“ eigentlich ein „Muss“ auf produktiven Systemen. Der Mehrwert für Performance-Analysen (von „ad hoc“- über „Nachbetrachtungen“ bis Trendbewertungen / -beobachtungen) ist groß. Der „Overhead“ der Erweiterung ist gering (zumindest bei einem vernünftigen Intervall und mehr oder weniger „werkseitigen“ Einstellungen) und belastet den Cluster nicht sonderlich. Natürlich haben wir an dieser Stelle nur einen sehr kleinen Überblick über die Funktionalität und die Konfigurationsmöglichkeiten dieser Erweiterung geben können.
Seminarempfehlung
Sie haben Fragen rund um das Thema PostgreSQL und / oder das Thema Datenbank-Performance? Dann sprechen Sie uns an.
POSTGRESQL ADMINISTRATION DB-PG-01
Zum SeminarPrincipal Consultant bei ORDIX
Kommentare