
Einstieg in die Data Science Pipeline – Meine zweite Praxisphase
Im Folgenden werde ich einen kleinen Einblick in die Welt der Data Science geben. Dabei stelle ich das Projekt meiner zweiten Praxisphase vor, mit dem äußerst langen Titel: Evaluierung & Dokumentation der Data Science Pipeline (mit Fokus auf den Data-Engineering-Kreislauf). Mittels Data Science können tiefere Erkenntnisse aus Massendaten gewonnen werden. Hierbei werden Methoden aus der Statistik, Mathematik und Informatik angewandt. In meinem Projekt habe ich mich insbesondere auf das Analysieren und Aufbereiten von Rohdaten fokussiert, dem sogenannten Data Engineering. Dies bildet den Ausgangspunkt eines jeden Data-Science-Projekts.
Was euch erwartet:
- Mein Praxisprojekt: Evaluierung & Dokumentation der Data Science Pipeline (mit Fokus auf den Data-Engineering-Kreislauf)
- Die Data Science Pipeline
- Das Data Engineering
- Umsetzung und aufgekommene Probleme
- Zusammenfassung
Mein Praxisprojekt: Evaluierung & Dokumentation der Data Science Pipeline (mit Fokus auf den Data-Engineering-Kreislauf)
Mein Praxisprojekt kann entsprechend dem Titel in zwei Hauptaufgaben unterteilt werden, der Evaluation und der Dokumentation. Im Evaluationsteil habe ich verschiedene Data-Engineering-Tools anhand eines Showcases miteinander verglichen (dazu später mehr). Im Dokumentationsteil war das Ziel, meine Erkenntnisse festzuhalten, welche aus der Evaluierung und Recherche resultierten, beispielsweise in einem Blogartikel wie diesem hier.
In einem Praxisprojekt lernt man häufig spannende neue Themengebiete kennen, deshalb steht zu Beginn vor allem eines an: Recherche. Bevor ich mich also auf den Teilbereich des Data Engineerings fokussierte, musste ich mir einen Überblick verschaffen. Dies tat ich mit verschieden Onlinequellen (Oreilly Learning, OpenHPI & Coursera). Darüber hinaus konnte ich von der vorhandenen Expertise aus dem eigenen Hause und verschiedenen Big-Data-Seminaren der ORDIX AG profitieren. Meine daraus gewonnen Erkenntnisse dokumentierte ich unter anderem in einer lebhaften Mindmap, welche auch zukünftigen Studierenden bei der Einarbeit in die Thematik helfen sollte.
Die Data Science Pipeline
Im Laufe meiner Recherche stellte ich fest, dass die Vorgehensweise eines Data Scientists gewissermaßen einem iterativen Kreislauf folgt. Es existiert eine Vielzahl von Darstellungen dieser sogenannten Data Science Pipeline (DSP). Die Darstellungen variieren vor allem in den Bezeichnungen und ihrer Granularität.
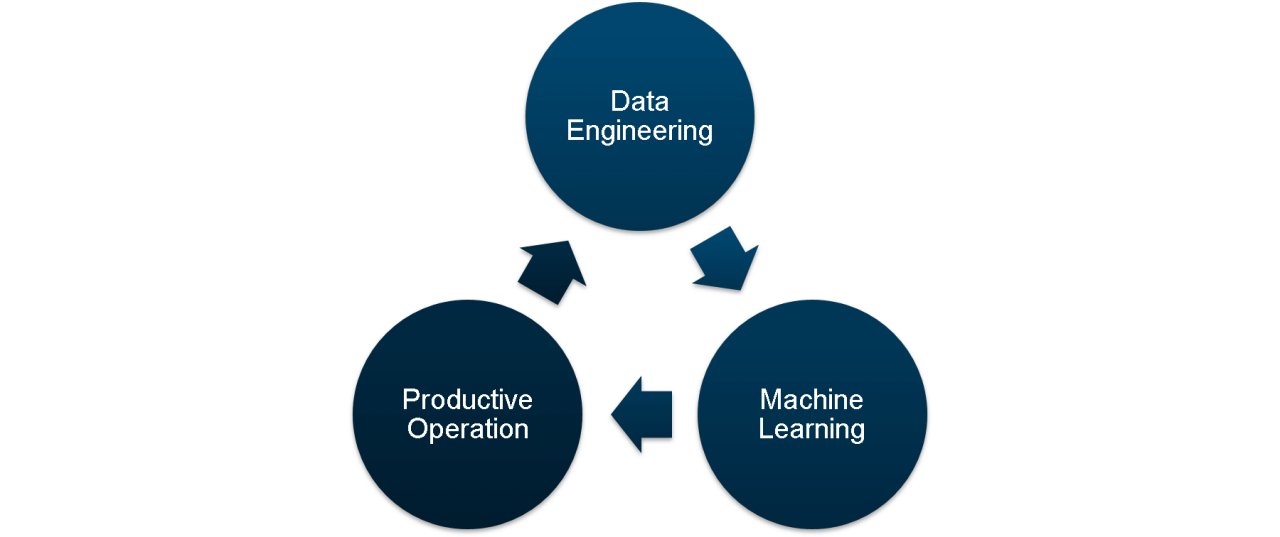
Die DSP ist in der obigen Abbildung dargestellt. Im ersten Schritt, dem Data Engineering, werden Daten analysiert und vorverarbeitet. Dabei müssen gewisse Qualitätskriterien je nach den Voraussetzungen des Machine-Learning-Modells erfüllt sein. Diese vorverarbeiteten Daten werden anschließend im Machine Learning für das Generieren und Trainieren von Modellen verwendet. Diese Modelle können letztlich in der Productive Operation, also dem Produktivbetrieb, verwendet werden – vorausgesetzt die Ergebnisse der Modelle halten der gewünschten Genauigkeitskontrolle stand. Erkenntnisse aus der Productive Operation können dann wiederum in die nächste Iteration der DSP einfließen.
Das Data Engineering
Das Data Engineering bildet das Fundament eines jeden Data-Science-Projektes und ist zudem der zeitaufwändigste Schritt der DSP. Ist dieser hohe Zeitaufwand gerechtfertigt? Ein beliebtes Sprichwort aus der Data Science lautet: Garbage In, Garbage Out. Dieses beschreibt unter anderem, dass die Ergebnisse von Machine-Learning-Modellen stark mit der zugrundeliegenden Datenqualität zusammenhängen. Folglich ist eine gewissenhafte Datenvorverarbeitung ausschlaggebend für den Erfolg eines Data-Science-Projektes, weshalb der hohe Zeitaufwand gerechtfertigt ist.
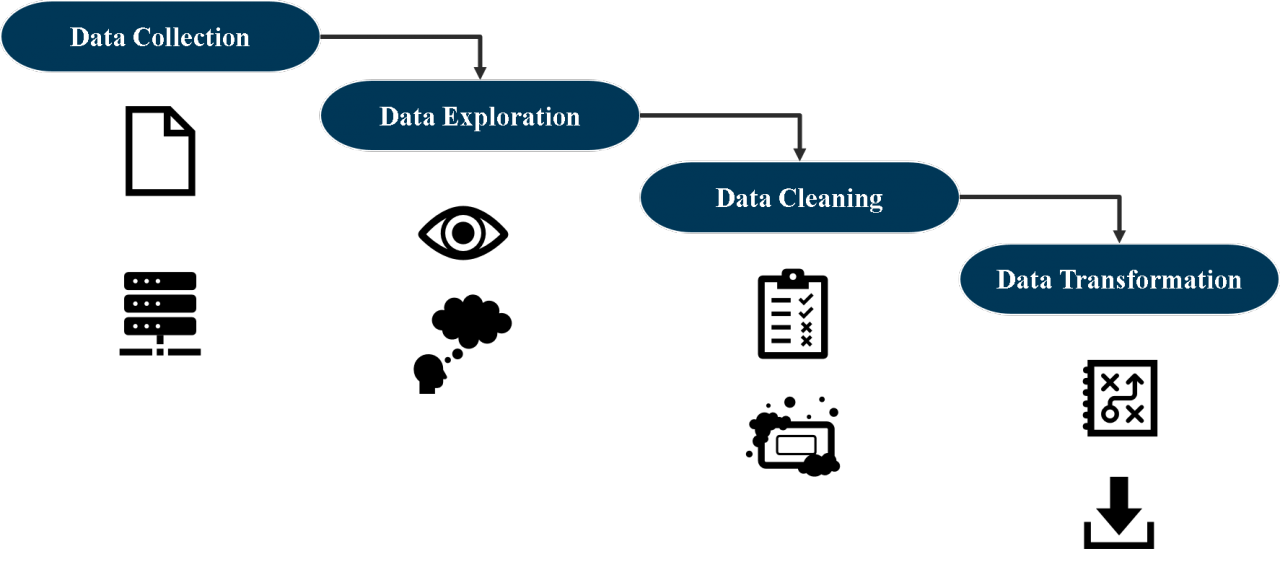
Grundsätzlich lässt sich das Data Engineering erneut in vier Teilschritte untergliedern.
Schritt 1: Daten Sammeln
Zuerst müssen in der Data Collection die benötigten Daten gesammelt werden. Dabei werden sowohl strukturierte als auch unstrukturierte Daten aus verschiedenen Quellen wie Datenbanken, APIs oder Textdateien zusammengeführt. Vorteilhaft ist es, diese Rohdaten aus verschiedenen Quellen in einem sogenannten Hadoop Data Lake zu bündeln. Damit können Problematiken der Zugänglichkeit und Datenintegration angegangen werden.
Schritt 2: Data Exploration
Sind die Daten gesammelt, kann die Data Exploration beginnen. In diesem Schritt geht es darum, ein Verständnis für die vorhandenen Daten zu bekommen. Neben den Statistik- und Informatikkenntnissen ist nämlich das Domänenwissen eines Data Scientists, also Fachwissen in dem jeweiligen Anwendungsbereich, von hoher Bedeutung. Die Daten müssen inhaltlich verstanden werden, um sinnvolle Analysen auf ihnen durchzuführen. In der Data Exploration werden vor allem visuelle Darstellungen und Kennzahlen zur Erforschung der Daten verwendet.
Schritt 3: Data Cleaning
Im Data Cleaning werden Ausreißer, fehlende oder fehlerhafte Daten lokalisiert und behandelt, da diese qualitätsmindernd sein können. Bei einer gründlichen Data Exploration sollten einem dabei schon viele dieser qualitätsmindernden Attribute bekannt sein. Das Data Cleaning kann teils komplexe Verfahren und Entscheidungen erfordern. So können Problematiken, wie das Ersetzen von fehlenden Daten, auf den ersten Blick trivial wirken. Eine kritische Betrachtung zeigt jedoch, dass man äußerst durchdacht agieren muss, um dabei Verzerrungen zu vermeiden. So könnte eine Mittelwertimputation von einem Attribut Vermögen verzerrend wirken, wenn im Datensatz viele Ausreißer vorliegen z.B. durch Milliardäre. Hier wäre eine Medianimputation oder andere komplexere Verfahren zu bevorzugen.
Schritt 4: Data Transformation
Umsetzung, Tools und aufgekommene Probleme
Nachdem ein gewisses Verständnis über die DSP und das Data Engineering im Speziellen vermittelt wurde, kommen wir zum Evaluationsteil meiner Praxisphase. Die Evaluation bezieht sich auf den Vergleich verschiedener Tools, welche für das Data Engineering genutzt werden können. Dabei habe ich verschiedene Python-Bibliotheken (NumPy, Pandas, Matplotlib, Scikit-learn), Apache Spark, Apache Nifi und Talend untersucht. Das detaillierte Ergebnis dieses Vergleichs werde ich wiederum in einem weiteren Blogartikel teilen.

Die Evaluation der verschiedenen Tools erfolgte anhand der Durchführung eines Showcases. In diesem Showcase durchliefen Wetterdaten des Deutschen Wetterdienstes die beschriebenen Schritte des Data Engineerings und wurden in ein vorher definiertes Zielformat überführt. Somit habe ich mit allen Tools den gleichen Showcase durchgespielt und konnte daraus die jeweiligen Vor- und Nachteile ableiten.
Das größte Problem am Projekt war, dass die Daten des Deutschen Wetterdienstes schon in sehr hoher Qualität vorlagen. Im Normalfall wäre das natürlich wünschenswert, jedoch findet man solch eine Datenqualität nur selten zu Beginn eines Data-Science-Projektes vor. Somit wäre für den Vergleich verschiedener Tools eine geringere Datenqualität von Vorteil gewesen. Als Lösung habe ich die Einfachheit des Showcases durch einen erhöhten Umfang der untersuchten Tools kompensiert. Dies hat mir die Möglichkeit gegeben, mehr Recherche und Diversität in meine Evaluation einzubringen.
Zusammenfassung
Mein Praxisprojekt in Kurzform: Der offizielle Titel lautet Evaluierung & Dokumentation der Data Science Pipeline (mit Fokus auf den Data Engineering Kreislauf). Die Data Science Pipeline beschreibt die iterative Arbeitsweise eines Data Scientists. Das Data Engineering beschreibt dabei den ersten Schritt dieser Pipeline. Dabei werden die Daten für spätere Machine Learning Algorithmen vorbereitet. In meiner Praxisphase habe ich verschiedene Data-Engineering-Tools miteinander verglichen. Darunter fallen verschiedene Python Bibliotheken, Apache Spark, Apache Nifi und Talend. Mit all diesen Tools habe ich den gleichen Showcase bearbeitet. Dabei habe ich Wetterdaten in ein gewünschtes Format gebracht. In diesem Artikel bin ich auf die einzelnen Schritte der Data Science Pipeline und im Detail auf die des Data Engineerings eingegangen. Die Ergebnisse des Tool-Vergleichs kann man in einem zukünftigen Blogartikel von mir nachlesen.
Falls Ihr Euch weitere Praxisphasen bei der ORDIX AG ansehen wollt, dann werft doch einen Blick in einen Blogartikel von Simon oder von Pascal. Ihr könnt Euch ein Praktikum oder Studium bei uns vorstellen? Dann bewerbt Euch doch direkt hier, wir freuen uns auf Eure Bewerbung.
Kommentare