
Ein Twitter-Bot mit Apache NiFi? Ja, das geht!
Ist eine Anwendung unter einer Open-Source-Lizenz veröffentlicht, wird gerne darauf verwiesen, dass jeder mit entwickeln kann und fehlende Features selbst implementiert werden können. So auch bei Apache NiFi. Fehlt ein Prozessor oder eine Funktion, können diese ohne Probleme nachträglich hinzugefügt werden.
Soweit die Theorie, doch wie sieht das in der Praxis aus? Gibt es weitere Prozessoren? Lohnt es sich, diese hinzuzufügen? Die Antwort lautet: Ja! Wie mithilfe von zusätzlichen Prozessoren in Apache NiFi ein Twitter-Bot entsteht, möchte ich nun zeigen.Von der Quelle aus ...
Zunächst müssen wir uns überlegen, wie wir an die Information kommen, dass ein neuer Blogartikel über NiFi veröffentlicht wurde. Alle Blogartikel über Apache NiFi werden bei ORDIX unter der Kategorie "nifi" geführt und liegen gesammelt unter der URL https://blog.ordix.de/categories/nifi. Kommt ein neuer Artikel hinzu, ist er automatisch dort zu finden. Zusätzlich gibt es die Möglichkeit, die Seite als RSS-Feed zu abonnieren. Ein RSS-Feed ist eine XML-Struktur und lässt sich in unserem Fall über den Link https://blog.ordix.de/categories/nifi?format=feed&type=rss ansehen. Die XML-Datei besteht im Wesentlichen aus einigen Meta-Informationen wie Titel, Beschreibung, URL und Sprache. Zusätzlich findet sich für jeden Blogartikel ein Item.
<item> <title>Joins über mehrere Datenbanksysteme - Was kann Apache NiFis LookUp-Prozessor?</title> <link>https://blog.ordix.de/was-kann-apache-nifis-lookup-prozessor</link> <guid isPermaLink="true">https://blog.ordix.de/was-kann-apache-nifis-lookup-prozessor</guid> <description><![CDATA[<p>Datenquellen wachsen und vermehren sich ständig, egal ob im Internet oder im eigenen Unternehmen. Daten fallen an verschiedenen Stellen und in verschiedenen Formaten an. Um diese Daten sinnvoll zu nut...</p>]]></description> <category>Data Management</category> <pubDate>Wed, 04 May 2022 09:00:51 +0200</pubDate> <enclosure url="https://blog.ordix.de/images/easyblog_articles/918/titelbild-was-kann-apache-nifis-lookup-prozessor-data-dataflow.jpg" length="292140" type="image/jpeg"/> </item>
Jedes Item hat dabei sieben Attribute:
- Title
- Link
- Guid isPermaLink
- Description
- Category
- PubDate
- Enclosure url
in den (Daten)Fluss ...
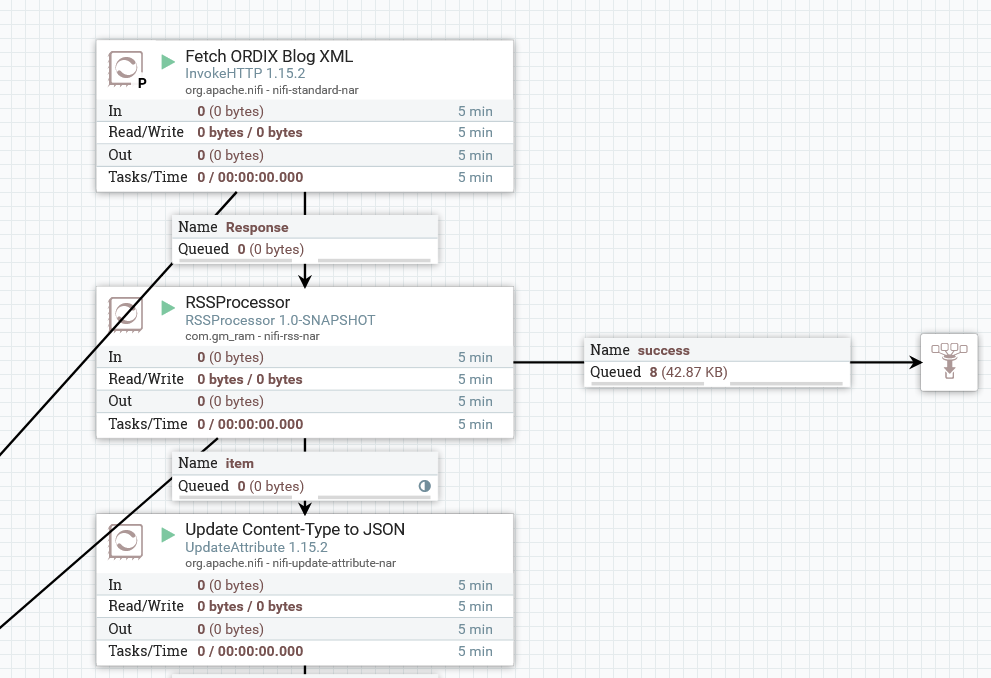
Mit dem bekannten InvokeHTTP-Prozessor können wir über einen GET-Aufruf auf die RSS-URL die gesamte XML-Datei laden. Diese leiten wir über die "Response" Verbindung in den neu hinzugefügten Prozessor "RSSProcessor". Dieser wandelt die gesamte XML-Datei so um, dass für jedes Item – also jeden Blogartikel – ein FlowFile entsteht. Der Inhalt des FlowFiles ist nun nicht mehr XML, sondern im JSON-Format. Der InvokeHTTP Prozessor läuft einmal am Tag um 9 Uhr vormittags. Wie Sie diese Einstellung vornehmen können, haben wir in unserem Blogartikel "Scheduling" beschrieben.
Ein FlowFile hat den folgenden Inhalt:
{
"publicationDate" : "Wed May 04 09:00:51 CEST 2022",
"author" : "",
"title" : "Joins über mehrere Datenbanksysteme - Was kann Apache NiFis LookUp-Prozessor?",
"description" : "<p>Datenquellen wachsen und vermehren sich ständig, egal ob im Internet oder im eigenen Unternehmen. Daten fallen an verschiedenen Stellen und in verschiedenen Formaten an. Um diese Daten sinnvoll zu nut...</p>",
"url" : "https://blog.ordix.de/was-kann-apache-nifis-lookup-prozessor",
"feedTitle" : "NiFi",
"feedUrl" : "https://blog.ordix.de/categories/nifi"
}
Es finden sich alle Attribute der XML-Struktur nun als JSON wieder. Damit lässt sich im folgenden Flow leichter arbeiten.
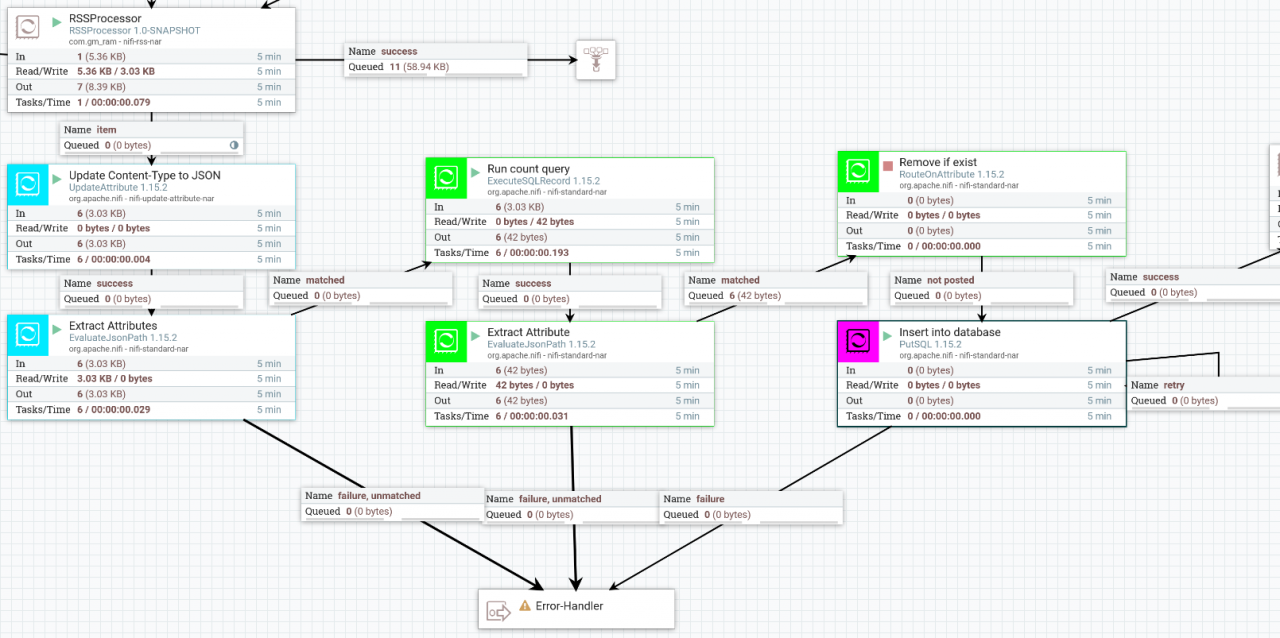
Nachdem "RSSProcessor" gelangen die FlowFiles in die beiden türkisen Prozessoren. Zunächst wird der Content-Type auf JSON geändert.
Die Änderung der Content-Type, oder manchmal auch Mime-Type des FlowFiles hat keinen fachlichen Nutzen. Dadurch lässt sich der Inhalt des FlowFiles aber in NiFi formatiert darstellen, was das Debugging erleichtert!
Danach werden die Attribute "title", "publicationDate" und "url" aus dem Inhalt des FlowFiles (JSON) in FlowFile-Attribute überführt. Auf FlowFile-Attribute kann deutlich schneller und einfacher zugegriffen werden als auf den Inhalt eines FlowFiles.
über Umwege ...
Die grün markierten Prozessoren bilden die Logik so, dass kein Blogartikel zweimal gepostet wird. Dafür wird im Hintergrund eine MySQL-Datenbank genutzt. Diese enthält eine Tabelle, in der alle bisher geposteten Artikel gespeichert sind. Mit dem ersten Prozessor wird eine dynamische SQL-Abfrage erstellt, die prüft, wie viele Einträge die Tabelle für den jeweiligen Titel hat.
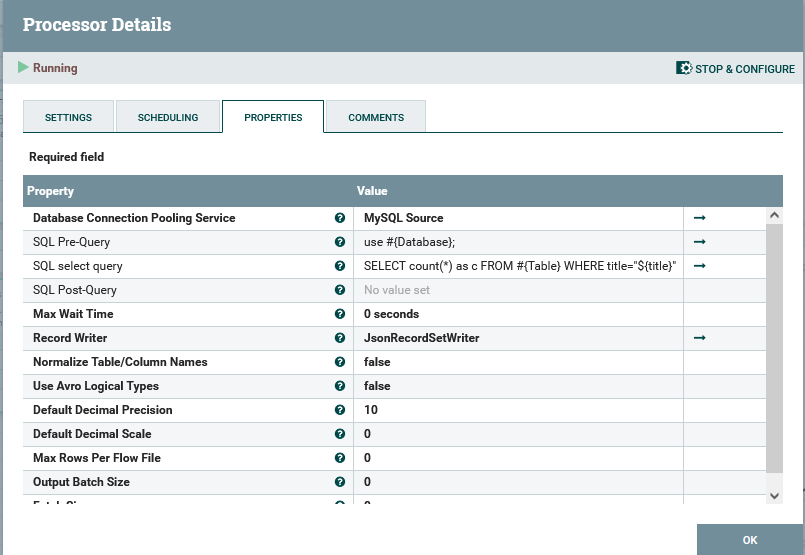
Die Erstellung der Abfrage entsteht in der Property "SQL SELECT Query" und lautet: SELECT count(*) as c FROM #{Table} WHERE title="${title}"
Die Werte für die Tabelle stammen aus einem Parameter Context und der Titel in der WHERE-Bedingung wird durch das jeweilige Attribut des FlowFiles ersetzt.
Das Ergebnis dieser Abfrage wird wiederum in den Inhalt des FlowFiles, ebenfalls im JSON-Format geschrieben und enthält nur das Attribut "c" und den entsprechenden Wert. Wurde ein Blogartikel schon gepostet, lautet der Inhalt:
{
“c”: 1
}
Im zweiten grünen Prozessor, dem „Extract Attribute“-Prozessor wird dieses JSON-Attribut wieder als FlowFile-Attribut aufgenommen, um es im dritten Prozessor, dem „Remove if exists“ Prozessor zu routen. Nur wenn der Wert von c null (0) ist, der Titel also noch nicht in der Datenbank vorkommt, soll das FlowFile über die Verbindung "not posted" geroutet werden. In jedem anderen Fall wird es gelöscht.
Der pinke Prozessor (PutSQL) erzeugt erneut ein dynamisches SQL-Insert-Statement und fügt so einen neuen Titel in der Datenbank ein. Dadurch wird der "count" beim nächsten Mal nicht mehr "Null", sondern "Eins" sein und das FlowFile wird beim Routen gelöscht.
... zu Twitter!
Nun stehen wir vor der letzten Herausforderung: Wie können wir etwas auf Twitter posten?
Im Standardrepertoire der NiFi-Prozessoren findet sich nur ein "GetTwitter"-Prozessor. Damit lassen sich Tweets konsumieren und weiterverarbeiten. Hier könnten wir sicherlich mit dem "InvokeHTTP"-Prozessor und einigen POST-Funktionen gegen die Twitter-API einen Tweet erzeugen, allerdings hilft erneut eine schnelle Google-Suche. Ebenfalls auf GitHub gibt es das Projekt "NiFi PutTwitter Processor".
Der letzte Commit war 2018, also vor vier Jahren. Entsprechend skeptisch probierte ich die bereits verfügbare NAR-Datei aus.
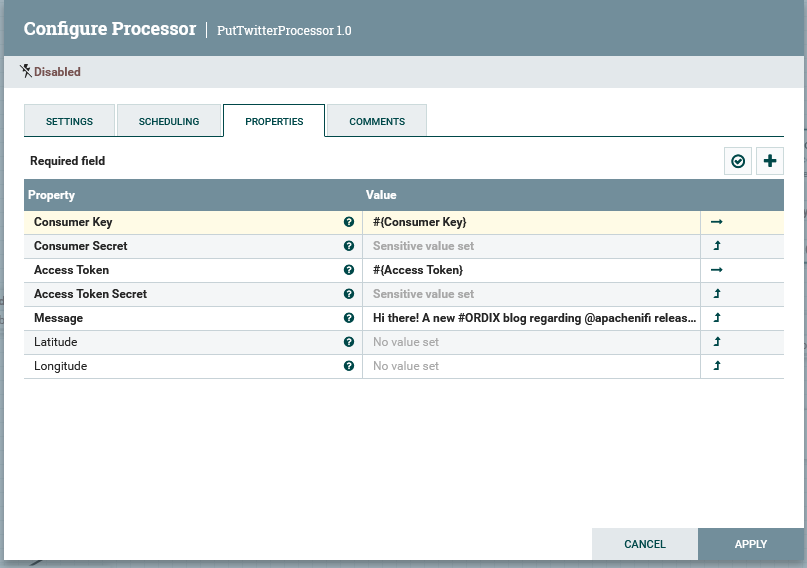
Viel Konfiguration lässt der "neue" Prozessor nicht zu. Es werden alle vier Access Keys und Tokens von Twitter benötigt. Diese lassen sich über einen Entwickler-Twitteraccount generieren. Dazu kann man eine "Message" eintragen.
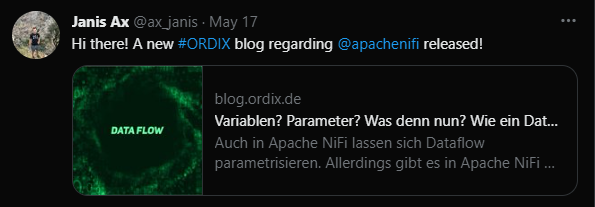
Die "Message" ist der später lesbare Teil des Tweets. Wir haben uns für folgenden Text entschieden:
Hi there! A new #ORDIX blog regarding @apachenifi released!
${url}
Die URL wird dabei dynamisch aus den FlowFile-Attributen geladen.
Mehr Konfiguration benötigt es allerdings nicht, denn der Prozessor funktionierte sofort und auf Twitter ist das gewünschte Ergebnis zu sehen:
Und nun?
Mit diesem Beispiel will ich zeigen, wie mächtig ein Open-Source-Projekt sein kann. Durch den Einsatz von zwei aus der Community entwickelten Prozessoren, konnten wir innerhalb kürzester Zeit einen Twitter-Bot entwickeln. Das kann eine Menge Arbeit sparen. Es ist sicherlich möglich dasselbe mit den hauseigenen Prozessoren zu entwickeln, allerdings benötigten wir hier nur neun Prozessoren.
In Summe können wir damit nun beliebige RSS-Feeds anbinden und wenn dort neue Artikel erscheinen, wird dies auf Twitter gepostet.
Den ganzen Flow finden Sie auf GitHub zum Ausprobieren.
Haben Sie Fragen rund um Apache NiFi? Sprechen Sie uns gerne an!
Seminarempfehlungen
APACHE NIFI GRUNDLAGEN DB-BIG-07
Zum SeminarAPACHE NIFI GRUNDLAGEN - KOSTENLOSES WEBINAR W-NIFI-01
Zum Seminar
MeetUp: Apache NiFi Germany
Tipp: Für den fachlichen Austausch empfehlen wir außerdem die MeetUp-Gruppe „Apache NiFi Germany“:
Senior Consultant bei ORDIX
Kommentare