
ELK Stack: Volltextsuche und Logarchivierung - Elasticsearch & Co
Elasticsearch
In jedem Unternehmen wächst die Zahl der produzierten Daten. Gerade Logdaten werden, aufgrund ihrer Menge oder ihrer geringen Werthaltigkeit, oft nur für kurze Zeit oder auch gar nicht aufbewahrt. Genau zu diesem Zweck wurde Elasticsearch von der Firma Elastic als Open-Source-Projekt entworfen. Es bietet eine vergleichsweise günstige Möglichkeit, Daten im JSON-Format zu speichern und in einer Volltextsuche für die verschiedensten Anwendungen zur Verfügung zu stellen.
Elasticsearch positioniert sich seit einigen Jahren erfolgreich als Alternative zu der ebenfalls auf Lucene basierenden Suchmaschine Apache Solr. Grund für den Erfolg von Elasticsearch dürften unter anderem folgende Eigenschaften sein: Elasticsearch bietet eine Hochverfügbarkeit durch ein relativ einfaches Clustering-Modell. Es kann, aufgrund seiner guten Lastverteilung und der Möglichkeit, jederzeit neue Knoten hinzuzufügen, sehr gut skalieren. Zudem ist es fast schemalos, dokumentenorientiert, bietet eine REST- sowie Java-API und kann in bestehende Umgebungen integriert werden. Auch unter hoher Änderungslast finden Dokumente schnellen Eingang in die Suche. Elasticsearch selbst spricht sogar von einer Echtzeitsuche. Darüber hinaus ist Elasticsearch sehr einfach in der Handhabung: Benötigt werden lediglich ein aktuelles JDK, cURL und ein Texteditor.
Speicherung
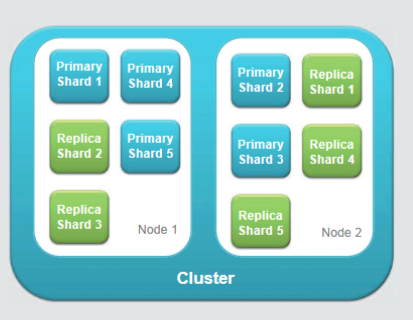
Elasticsearch verfolgt einen dokumentenzentrierten Ansatz, d. h. sämtliche Daten werden im verbreiteten JSON-Formatübergeben und gespeichert. Die interne Ablage der Datenerfolgt in Indizes. Ein Index bildet dabei einen sowohl physischen als auch logischen Namensraum. Er kann hierbei mehrere unterschiedliche Dokumente aufnehmen und besteht selbst auch aus einem oder mehreren Dokumententypen. Die Unterteilung in mehrere Typen ermöglicht eine bessere Durchsuchbarkeit des Indexes (s.u.). Die physische Speicherung eines Indexes erfolgt in mehrerenPrimary Shards. Diese wiederum stellen einzelne Lucene-Instanzen dar. Die Aufteilung der Indexes in mehrere Shards dient der Lastverteilung: Zur physischen Lastverteilung können die einzelnen Shards auch auf mehrere Knoten eines Elasticsearch-Clusters verteilt werden. Aus den Primary Shards können darüber hinaus Replica Shards erzeugt werden. Diese sind eine Kopie ihres jeweiligen Primary Shards und befinden sich auf anderen Knoten des Clusters. Sie bieten Schutz vor Daten verlust, ermöglichen eine Hochverfügbarkeit und dienen zur Optimierung von Suchanfragen. Die Knoten eines Clusters haben als Konfigurationseinstellung immer denselben Clusternamen (Standard: „Elasticsearch"). Daher können mehrere Cluster nebeneinander im selben Netzwerk betrieben werden.
Cluster-Ansatz
Ein Elasticsearch-Cluster ist nach dem Master-Slave-Prinzip aufgebaut. Grundsätzlich kann jeder Knoten des Clusters beide Rollen annehmen. Beim Start führt jeder Knoten einen Discovery-Prozess durch und sucht nach anderen Knoten im gleichen Netzwerk. Die Knoten handeln den Master-Knoten selbst aus. Fällt dieser aus oder ist zeitweise nicht erreichbar, wählt man aus ihrer Mitte einen neuen Master-Knoten.
Installation
Die Installation eines Elasticsearch-Knotens ist einfach. Das Installationspaket muss lediglich entpackt werden und der Knoten über den Befehl ./bin/elasticsearch-fgestartet werden. Elasticsearch verfolgt einen Zero-Konfiguration-Ansatz. Alle möglichen Einstellungen sind bereits mit sinnvollen Standardwerten vorbelegt.
Diese befinden sich in der im YAML-Format geschriebenen Konfigurationsdatei config/elasticsearch.yml.
Vor dem Start des Knotens empfiehlt es sich, den Cluster-Namen anzupassen, um den neuen Knoten nicht versehentlich in das falsche Cluster einzuhängen. Nach dem Start ist der Knoten über den Port 9200 erreichbar. Sollen dem Cluster weitere Knoten hinzugefügt werden, muss darauf geachtet werden, dass diese sich im selben Netzwerk und unter demselben Clusternamen befinden.
Dokumente laden und ändern
Wenn das Cluster läuft, können nun die ersten JSON-Dokumente übergeben und gespeichert werden. Die Übergabe der Dokumente kann entweder per HTTP-Put oder HTTP-Post erfolgen. Abbildung 1 zeigt die Übertragung von Adressinformationen der ORDIX AG in Form eines JSON-Dokumentes an den Elasticsearch-Knoten „es1.ordix.de". Dieses Dokument soll dort, wie an der URL zu erkennen, in dem Index „customers" als Doku-mententyp „company" abgelegt werden. Jeder Knoten des Elasticsearch-Clusters kann dazu über eine REST-konforme URL angesprochen werden. Es ist nicht nötig, den Master-Knoten anzusprechen. Elasticsearch quittiert jeden Aufruf mit einem JSON-Dokument. Dieses beinhaltet in diesem Fall eine Information über den Erfolg der Operation, den verwendeten Index sowie die ID und Version des betroffenen Dokuments.
In Abbildung 1 wurde ein Dokument ohne ID übermittelt. Daher generiert Elasticsearch selbst eine neue, eindeutige Dokumenten-ID. Unter Angabe der ID ist es möglich, ein Dokument zu überschreiben, zu lesen oder zu löschen. Dazu muss das Dokument allerdings per HTTP-Put und nicht, wie im vorigen Beispiel, per HTTP-Post übergeben werden.
Ist bereits ein Dokument mit dieser ID im Elasticsearch-Cluster vorhanden, wird das bestehende Dokument überschrieben und die Versionsnummer inkrementiert. Abbildung 2 zeigt, wie ein Dokument überschrieben, gelesen oder gelöscht werden kann.
url -X POST http://es1.ordix.de:9200/customers/compa-
ny -d '{
"name": "ORDIX AG",
"street": „Westernmauer 12-16",
"city" : "Paderborn",
"zipcode" : 33098,
"country" : „Deutschland",
"ceo" : "Wolfgang Kögler"
}’
{
"ok" : true,
"_index" : "customers",
"_type" : "company",
"_id" : "RGaH58ppD-Xj_gdkZ34tx3",
"_version": 1
}
Abb. 1: Übertragung eines JSON-Dokuments mit entsprechender Antwort
//Überschreiben
curl -X PUT http://es1.ordix.de:9200/customers/compa-
ny/RGaH58ppD-Xj_gdkZ34tx3 -d '{
"name": "ORDIX AG",
"street": "Karl-Schurz-Str. 19A",
"city" : "Paderborn",
"zipcode" : 33100,
"country" : "Deutschland",
"ceo" : "Wolfgang Kögler"
}’
//lesen
curl -X GET http://localhost:9200/addresses/
german/1234?pretty
//löschen
curl -X DELETE http://localhost:9200/addresses/
german/1234?pretty
Abb. 2: Ändern, lesen und löschen eines JSON-Dokuments
Schemafreiheit
Auch wenn Elasticsearch von außen betrachtet schemafrei erscheint, ist es dies nicht wirklich. Bei der Übergabe von Dokumenten müssen keine Datentypen o. Ä. definiert werden. Diese werden automatisch aus den übergebenen Dokumenten abgeleitet: Ein aus Zeichen bestehendes Feld wird als String interpretiert, Zahlen deuten auf numerische Werte hin und für Datumsangaben stehen einige Grundformate zur Verfügung. Das Schema eines Dokumententyps kann, wie in Abbildung 3 gezeigt, auch abgefragt werden.
curl -X GET http://es1.ordix.de:9200/customers/
company/_mapping?pretty
{
"company" : {
"properties" : {
"name" : { "type" : "string" },
"street" : { "type" : "string" },
"city" : { "type" : "string" },
"zipcode" : { "type" : "long" },
"ceo" : { "type" : "string" }
}
}
}
Abb. 3: Abfrage von Schemainformationen
Suchen und finden
Hauptaufgabe einer Suchmaschine wie Elasticsearch ist das Suchen und Finden von Dokumenten. Diese bietet dazu eine eigene Abfragesprache: die Elasticsearch Query DSL. Diese Sprache bietet neben einfachen auch sehr komplexe Abfragen mit boolschen Operatoren, Gruppierungen oder Hierarchien.
Abbildung 4 zeigt die einfachste Form einer Abfrage: die Suche nach einem konkreten Term, der genau so in dem zu findenden Dokument vorhanden sein muss. Das dort dargestellte Ergebnis teilt sich in einen Header, der allgemeine Informationen zur Suchanfrage liefert, und die dazu gefundenen Dokumente.
Eine Volltextsuche macht jedoch nur Sinn, wenn eine Suchanfrage auch bei sehr unscharfen Anfragen gute Ergebnisse liefert. Dafür steht u. a. die match-Query zur Verfügung. Abbildung 5 zeigt eine Suchanfrage nach dem String „Ordix". Das Ergebnis liefert zudem ein Dokument zu „ORDIX AG". Daneben besitzt die Elasticsearch Query DSL noch viele weitere interessante Features, deren Er-klärung den Rahmen dieses Artikels sprengen würde. Auf der Elasticsearch-Webseite befindet sich ein sehr gutes Tutorial zum Erlernen der Sprache. So ist es z. B. mög-lich, die Fähigkeiten durch eigene Skripte (Funktionen) zu erweitern oder den Dokumenten eine „Time to live" (TTL) mitzugeben.
curl -X GET http://es1.ordix.de:9200/customers/compa
-
ny/_search -d '{
"query" : {
"term" : {
"city" : "Paderborn"
}
}'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.30531824,
"hits" : [ {
"_index" : "customers",
"_type" : "company",
"_id" : "RGaH58ppD-Xj_gdkZ34tx3",
"_score" : 0.30531824, "_source" : {
"name": "ORDIX AG",
"street": "Karl-Schurz-Str. 19A",
"city" : "Paderborn",
"zipcode" : 33100,
"country" : „Deutschland",
"ceo“ : "Wolfgang Kögler"
}
} ]
}
}
Abb. 4: Suche und Ergebnis
curl -X GET http://es1.ordix.de:9200/customers/compa
-
ny/_search?pretty -d '{
"fields" : ["name", "city"],
"query" : {
"match" : {
"name" : "Odix"
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.002537901,
"hits" : [ {
"_index" : "customers",
"_type" : "company",
"_id" : "RGaH58ppD-Xj_gdkZ34tx3",
"_score" : 0.002537901,
"fields" : {
"name" : "ORDIX AG",
"city" : "Paderborn"
}
} ]
}
}
Abb. 5: Volltextsuche mit unscharfem Suchbegriff
Logstash
Logstash ist ebenfalls ein von der Firma Elastic entwickeltes Werkzeug, um Logdaten in JSON-Dokumente umzuwandeln und in einem Elasticsearch-Cluster zur Verfügung zu stellen. In seiner Grundfunktion ist es eine netzwerkfähige Pipe mit verschiedenen Filtermöglichkeiten. Seine Aufgabe ist es, Meldungen aus verschiedenen Inputs (Dateien, log4j u.a.) zu empfangen, zu filtern und an einen oder mehrere Outputs weiterzuleiten.
Logstash selbst hat keine Möglichkeit, Daten zu speichern.Es ist dazu ausgelegt, die Daten in Elasticsearch abzulegen. Zur kurz fristigen Speicherung der Daten ist es jedoch möglich, diese in einer Redis-Datenbank zwischenzuspeichern, beispielsweise für den Fall einer kurzzeitigen Nichterreichbarkeit oder Überlastung des Elasticsearch-Clusters. So kann der Datenfluss entkoppelt und ein Datenverlust vermieden werden. Die Handhabung ist auch hier sehr einfach. Alle benötigten Informationen zu Quellen, Zielen und Informationen zum Parsen der Daten müssen in einer Konfigurationsdatei erfasst werden. Anschließend kann Logstash ebenso einfach wie Elasticsearch installiert und gestartet werden.
input {
file {
path => ["/log/spring.log"]
start_position => beginning
type => „spring_log“
}
}
filter {
multiline {
pattern => "((^\s*)[a-z\$\.A-
Z\.]*Exception.+)|((^\s*)at .+)"
what => "previous"
}
grok {
match => [ "message",
"^(?[0-9]{4}\-[0-9]{2}\-[0-9]{2})
%{TIME:time}
(?:\s*)
(?[A-Z]+)
%{NUMBER:pid}
(?\[.*\])
(?:\-\-\-)
(?[0-9a-z\$A-Z\[\]/\.]*)
(?:\s*:)
(?(.|\s)+)"]
}
kv {}
}
output {
elasticsearch {
host => es1.ordix.de
index => "logs"
}
}
Abb. 6: Logstash-Konfigurationsdatei
Logstash-Filter
Die Filterfunktionen in Logstash dienen in erster Linie dem Aufbau des JSON-Dokuments und nicht dazu, Daten herauszufiltern. Zum Beispiel kann die Zeile einer Logdateimehrere Informationen beinhalten, wie den Rechnernamen, Zeitstempel, Messagetyp Error oder Debug. Durch die Verwendung von Filterfunktionen können diese Informationen extrahiert und in dem zu generierenden JSON-Dokument in eigenen Feldern abgelegt werden.
Zu den bekanntesten Filterfunktionen gehört der Grok-Filter. Mit diesem Filter werden Daten mithilfe regulärer Ausdrücke durchsucht, wohingegen der Multiline-Filter mehrere Zeilen einer Logdatei zu einem JSON-Dokument zusammenführt und so einen Stacktrace in einem JSON-Dokument abbildet. Daneben gibt es noch weitere Filter, wie z. B. Geo-IP. Dieser kann IP-Adressen um Geoinformationen ergänzen, um so die Herkunft der Besucher einer Webseite festzustellen. Es besteht auch die Möglichkeit, alle Filter hinterein ander zu verwenden und somit zu kombinieren. Abbildung 6 zeigt das Beispiel einer Logstash-Konfigurationsdatei. Diese Datei teilt sich in drei Blöcke: Input, Filter und Output. Der Input-Block definiert die Datenquelle, in diesem Fall eine Datei. Im Filter-Block wird zunächst ein Multiline-Filter verwendet, um beispielhaft den mehrere Zeilen umfassenden Stacktrace eines Spring-Logs in einem JSON-Dokument zusammenzufassen.
Im sich anschließenden Grok-Filter werden nun aus diesen Informationen der Zeitstempel und die Prozess-ID extrahiert. Im Output-Block wird als Ziel das Elasticsearch-Cluster angegeben. Logstash erstellt standardmäßig jeden Tag einen neuen Index mit einem konfigurierbaren Prefix (standardmäßig "logstash_"), gefolgt von dem Erstellungsdatum.
Kibana
Kibana ist die dritte Komponente des ELK Stacks. Im Kern ist es eine Javascript-basierte Weboberfläche, welche auf ein Elasticsearch-Cluster per Webinterface zugreifen kann. Kibana dient der visuellen Darstellung von Abfragen des Elasticsearch-Clusters in Form von Tabellen, Säulen- oder Tortendiagrammen. Kibana bietet die Möglichkeit, die in Elasticsearch gespeicherten Daten anzuschauen und einfache Anfragen ohne Kenntnisse der Elasticsearch Query DSL „zusammenzuklicken".
Fazit
Glossar
DSL
Domain Specific Language (anwendungsspezifische Sprache)
YAML
Eine an XML angelehnte, vereinfachte Auszeichnungssprache
REST
Representational State Transfer, ein Programmierparadigma für verteilte Systeme
HTTP-Put
Request-Methode des Hyptertext Transfer Protokolls
HTTP-Get
Request-Methode des Hyptertext Transfer Protokolls
Redis
In-Memory NoSQL-Datenbank in der Form Key-Value Stores
TTL
Time to Live. Gültigkeitsdauer oder auch Aufbewahrungszeit von Daten
Links/Quellen
[1] Internetseite Elastic https://www.elastic.co/de/
[Q1] Produktseite Elasticsearch https://www.elastic.co/de/products/elasticsearch


Isabell Rosenblatt hat noch keine Informationen über sich angegeben
Kommentare 1
Ein sehr guter Post, der alles ausreichend zusammen fasst. Das Speichern, Organisieren und Abrufen von Dokumenten alleine reicht heute nicht aus, um dauerhaft wettbewerbsfähig zu bleiben. Nur wer Dokumentinhalte technologisch erschließt, kann Inhaltsdaten zu verwertbaren Geschäftsinformationen umwandeln. Deshalb eine gute Lösung ist die Nutzung von virtuellen Datenräume. Anstieg der Quantität von Computerbetrug und damit einige Raub von vertraulichen und anderen Aussagen sowie Werkstoffpleitee, was nur mit IDeals vermieden werden kann.