
ELT vs. ETL in der Cloud (1/2): Datentransformation mit Azure Data Factory v2
Bei einem Data Warehouse ist eine der wichtigsten Komponenten die Beladung, ein Prozess, in dem selbst kleine Fehler eine große Menge an Daten unbrauchbar machen können. Oft wird der Prozess über SQL-Skripte, oder andere ELT-Lösungen abgebildet, allerdings sind diese durch ihre Natur größtenteils auf Server-interne Aktionen beschränkt. ETL-Werkzeuge schaffen hier Abhilfe, da sie (fast immer) sämtliche Transformationen außerhalb des SQL-Servers durchführen.
Azure Data Factory
Die Azure Data Factory (ADF) ist ein PaaS-Produkt in der Microsoft Azure Cloud, das es ermöglicht, auf dem ETL-Prinzip-basierende Datenstrecken grafisch zu konstruieren.
Hierfür unterstützt ADF nativ zwei Prozessebenen:
- Pipelines
- Datenflüsse
Pipelines sind Workspaces, in denen verschiedene Aktivitätsblöcke aneinandergereiht werden, wobei diese Aktivitäten grob in drei Kategorien eingeteilt werden können:
- Die Kopier-Aktivität
- Flusskontroll-Aktivitäten (Variablen, Schleifen, Bedingungen)
- Transformationsaktivitäten
Datenflüsse gehören hingegen zu den Transformationsaktivitäten und werden von einer Pipeline aus aufgerufen, nachdem sie in einer eigenen Übersicht in der Data Factory erstellt worden sind. Durch die rechenintensive Natur von Datentransformationen, stellt Azure eigene Rechencluster zur Verfügung, die separat in Rechnung gestellt werden.
Angelehnt ist die Struktur eines Datenflusses an SQL-Abfragen, wobei fast jede Komponente (intern auch „Transformation“ genannt) einem Schlüsselwort entspricht. Zu beachten ist hier die Reihenfolge der Blöcke: Ein Datenfluss wird nicht auf dieselbe Weise auf wie ein Skript aufgebaut, sondern es ist ein wenig Umdenken im Aufbau nötig, wie man in der folgenden Abbildung sieht.
Debugging von Datenflüssen
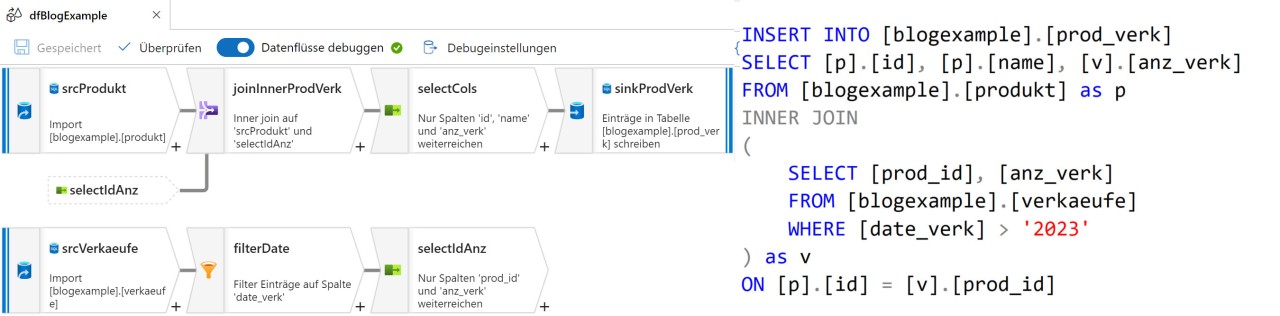
Für die Objekte einer an ein Versionskontrollsystem (entweder Azure DevOps oder Github) angeschlossene ADF-Instanz gibt es drei mögliche Zustände:
- Ungespeichert: Änderungen existieren nur im Cache, und werden beim Schließen des Fensters gelöscht
- Gespeichert: Änderungen wurden auf einen vorher gewählten Branch abgelegt
- Veröffentlicht: Änderungen wurden gespeichert und auf dem Branch adf_publish abgelegt
Jedes Repository kann nur einen Veröffentlichungs-Branch besitzen und die dort abgelegte Version wird für die Pipeline-Ausführung im täglichen Betrieb benutzt. Möchte man nur gespeicherte Pipelines testen, benutzt man die Debug-Ausführung, welche jedoch den Nachteil hat, dass nur das sequenzielle Abarbeiten von Schleifen möglich ist. Grundsätzlich benötigen Datenflüsse Rechencluster, die eigens hochgefahren werden müssen. Um die damit verbundenen Wartezeiten möglichst zu verkürzen, existieren für Datenflüsse eigene Debug-Umgebungen.
Nachdem ein Cluster hochgefahren wurde, bleibt er aktiv, bis er manuell heruntergefahren wird oder der Cluster für eine gewisse Zeit inaktiv ist. Währenddessen kann, wie in Abb. 2 zu sehen, für jede einzelne Transformation innerhalb eines Datenflusses eine Vorschau angezeigt werden, wobei hier nur eine begrenzte Anzahl an Records angezeigt werden kann. Die Grundeinstellung liegt bei 1000 Records, der Wert ist jedoch konfigurierbar.
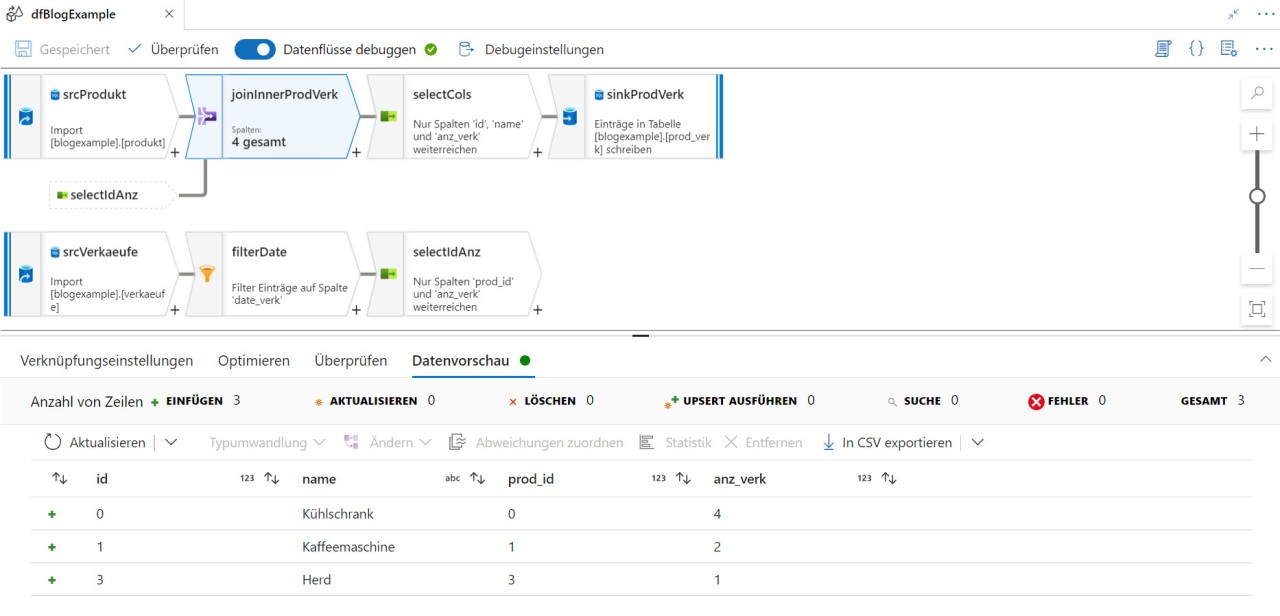
Azure Aktivitäten
Microsoft Data Factory v2 eignet sich hervorragend für alle gängigen Anforderungen im ETL-Umfeld. Neben den hier vorgestellten, grundlegenden Funktionalitäten, bietet die Data Factory v2 zahlreiche weitere Funktionalitäten. Die Kategorie der Transformations-Aktivitäten wurde bereits benannt, allerdings fällt darunter deutlich mehr, als nur die Datenflüsse. Als Service innerhalb der Microsoft Azure Cloud erlaubt die Azure Data Factory auch das Ausführen einer Reihe von anderen Azure-Diensten, wie beispielsweise Machine-Learning-Pipelines, Databricks-Skripten oder Synapse-Notebooks, solange sie bereits in ihren eigenen Azure-Ressourcen erstellt worden sind.
Eine ausführliche Liste der unterstützten Dienste finden Sie hier.
Ressourcenzugriff
Ein häufiges Problem bei rechenintensiven Operationen ist die Verwaltung der benötigten Ressourcen. Cloud-Umgebungen wie Azure vereinfachen das Ganze, indem sie Ressourcen dynamisch zur Verfügung stellen.
Zugrunde liegen den allokierten Ressourcen zwei mögliche Arten der sogenannten Integration Runtime (IR), welche definieren, wo die Ressourcen herkommen:
- Azure Integration Runtime
- Self-Hosted Integration Runtime
Wird eine Azure-IR benutzt, dann stellt Azure die Compute-Ressourcen zur Verfügung, während bei der Self-Hosted-IR die Aktionen auf einer vorbereiteten On-Premises Umgebung durchgeführt werden. Self-Hosted-IRs verursachen entsprechend deutlich geringere Kosten auf Azure, da die Datenflüsse nicht auf Azure Hardware ausgeführt werden.
Datenflüsse sollen in der Regel komplexe Datentransformationen durchführen. Die allokierte Rechenleistung ist nicht statisch, sondern kann in der Azure Integration Runtime dynamisch konfiguriert werden. Die zur Verfügung stehende Rechenleistung wird in Prozessorkernen angegeben und mögliche Compute-Größen können von 8 bis 272 Kernen konfiguriert werden. Zusätzlich bestimmt die Anzahl der Kerne auch die Größe des zugewiesenen RAM-Speichers.
Pipeline-Überwachung
Die Nachverfolgung von benutzten Ressourcen und die Erhebung von Metadaten zu Pipeline-Ausführungen ist bei ELT-Verfahren oftmals kompliziert. Die verwendete Rechenkapazität geht häufig in der generellen Benutzung unter und Informationen zu einzelnen Tasks werden entweder gar nicht erhoben oder können nur durch eine gesonderte Implementierung sichtbar gemacht werden. In der Azure Data Factory v2 ist eine entsprechende Funktion direkt integriert.
Um einen Überblick darüber zu erhalten, was während der Ausführung einer Pipeline passiert, kann die Monitor-Übersicht verwendet werden. Hier wird auf oberster Ebene eine Liste aller Ausführungen der letzten sechs Wochen, mitsamt ihrer Start- und Endzeit, ihrer Dauer und den verbrauchten Ressourcen, gespeichert. Möchte man sich eine Pipeline-Ausführung detaillierter anschauen, erhält man dieselben Informationen über einzelne Aktivitäten innerhalb dieser Pipeline.
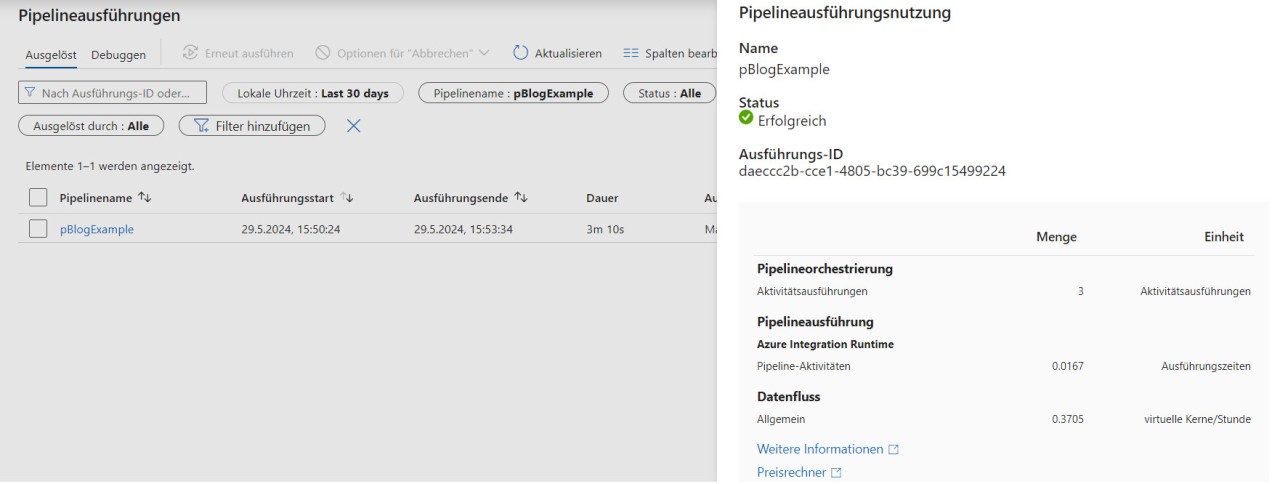
Nachdem dieser Artikel einen ersten Einblick in die Welt von Pipelines und Datenflüssen der Azure Data Factory gegeben hat, werden wir uns im zweiten Teil mit den daraus entstehenden Kosten beschäftigen.
Seminarempfehlung
CLOUD COMPUTING ESSENTIALS CLOUD-COMP
Mehr erfahrenWerkstudent
Kommentare