
Wettbewerb GermEval 2021 – "ein schöner VW Golf Diesel"
Die Aufgabe: automatisierte Detektoren für die Klassifikation von natürlicher Sprache
Als Teil der Bearbeitung meiner Bachelorarbeit nahm ich zusammen mit meinem betreuenden Professor und einem Doktoranden als Team „FHAC" am diesjährigen GermEval-2021-Wettbewerb teil, welcher im Rahmen der KONVENS (Konferenz zur Verarbeitung Natürlicher Sprache) stattfand. Die Motivation des Wettbewerbs GermEval 2021 war es, Moderator:innen von Social-Media-Seiten bei ihrer Arbeit zu unterstützen. Deren Aufgabe ist es unter anderen, die Kommentarsektion ihrer Seite zu kontrollieren und eine zivilisierte Diskussionskultur zu wahren. Der GermEval-Wettbewerb hat hierfür drei interessante Klassen an Kommentaren identifiziert: toxische oder diskussionsfördernde Kommentare und Tatsachenbehauptungen. Die Definition der toxischen Kommentare ist etwas weiter gefasst als die der sogenannten Hate Speech. In der Regel möchten Moderator:innen toxische Kommentare auf ihrer Social-Media-Seite blockieren oder die entsprechenden Benutzer sperren. Weiterhin zeichnen sich diskussionsfördernde Kommentare durch respektvolles Verhalten aus. Diese wollen die Moderator:innen wohlmöglich gesondert hervorheben. Zuletzt verwenden Tatsachenbehauptungen Informationen als wären es Fakten. Tatsachenbehauptungen müssen auf ihre Gültigkeit überprüft werden, um „Fake News" zu erkennen. Die Aufgabenstellung des GermEval-2021-Wettbewerbs war es daher, automatisierte Detektoren für diese drei Klassen an Kommentaren (die drei Subtasks) zu entwickeln.
Training der Dektoren
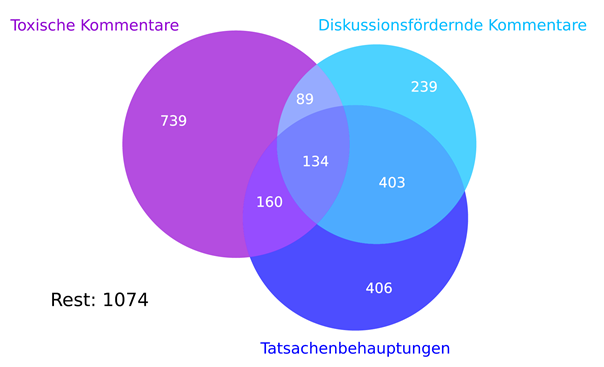
Zum Training der Detektoren wurde ein Trainingsdatensatz veröffentlicht, welcher 3244 Kommentare einer Facebook-Seite einer deutschsprachigen Fernsehsendung enthält. Alle Kommentare wurden von Menschen händisch in die drei bereits genannten Klassen an Kommentaren eingeordnet. Hierbei ist es wichtig, dass Kommentare auch zu mehreren Klassen gleichzeitig oder zu keiner einzigen Klasse gehören können (siehe Abbildung 1).
Mit diesem Trainingsdatensatz konnten beliebige Machine Learning Modelle trainiert und evaluiert werden. Zur Bewertung der teilnehmenden Teams wurde weiterhin ein Testdatensatz veröffentlicht, welcher nur Kommentare enthielt. Die Zuordnungen zu den drei Klassen war uns Teilnehmern demnach unbekannt. Nun sollten wir unsere trainierten Detektoren Vorhersagen für den Testdatensatz treffen lassen. Für jeden im Testdatensatz enthaltenen Kommentar sollte also dessen Zugehörigkeit zu den drei Klassen entschieden werden (die sogenannte Klassifikation). Jedes Team durfte anschließend maximal drei Vorhersagen für den Testdatensatz beim Wettbewerb abgeben. Anhand dieser Abgaben wurden die Teams schließlich miteinander verglichen.
Die Relevanz des Kontextes
Zwei erste Plätze beim GermEval Wettbewerb
Neben den eigentlichen Abgaben der Vorhersagen der Detektoren musste ein sogenanntes „Submission Paper" erstellt und eingereicht werden. Hier sollten die genutzten Techniken erklärt und die gewonnenen Erkenntnisse darstellt werden. Die Submission Paper jedes Teams wurden im Rahmen der „Proceedings of the GermEval 2021 Workshop" veröffentlicht. Zusätzlich ist das Submission Paper meines Teams FHAC bei Arxiv zu finden (siehe Referenzen).
Nach der Abgabe des Submission Papers wurde mein Team eingeladen einen Vortrag auf dem GermEval Workshop der KONVENS 2021 zu halten. Neben einer einminütigen Vorstellung unserer Abgaben im Rahmen der „One Minute Madness" berichteten wir in einem detaillierten Vortrag von unseren Ergebnissen. Am Tag des GermEval Workshops wartete dann zusätzlich noch die große Überraschung auf mein Team. In den drei Subtasks des Wettbewerbs belegten wir jeweils Platz 1, Platz 2 und Platz 1! Das Team FHAC konnte sich gegen mehrere deutsche und internationale Hochschulen (beispielsweise aus Österreich, der USA oder Indien) durchsetzen.
Ergebnisse und Erkenntnisse
In der Retroperspektive hat der GermEval Wettbewerb einige interessante Ergebnisse geliefert. Zum einen zeigte sich die Überlegenheit von Transformer-Modellen (neuronale Netzwerke) bei der Klassifikation von natürlicher Sprache. Weiterhin bestätigte sich die eingangs angesprochene These, dass sprachspezifische Lösungen den sprachunspezifischen Lösungen überlegen sind. Teams, welche deutschsprachige Transformer-Modelle verwendeten, schnitten meist besser ab. Zusätzlich stellte sich die Verwendung von Ensembles von Modellen als gewinnbringend heraus. Hierbei verwendet man mehrere unterschiedliche Modelle, welche jeweils eine Vorhersage treffen. Diese Vorhersagen kombiniert man anschließend (ganz nach dem Motto: „The Wisdom of the Crowd") zu einer finalen Vorhersage.
Habe ich mit diesem Artikel Ihr Interesse geweckt? In meinen nächsten Artikeln werde ich mich näher mit den Ergebnissen des GermEval Wettbewerbs befassen. Stay tuned!
Links zu dem Event
[1] Proceedings of the GermEval 2021 Workshop
[2] Submission Paper
[3] Pressemitteilung der FH Aachen

Consultant bei ORDIX.
Kommentare