
HBase Troubleshooting Guide
In der Welt von Big Data gibt es viele leistungsstarke Technologien, die uns helfen, große Datenmengen schnell und effizient zu verarbeiten. Eine dieser Technologien ist Apache HBase, ein verteiltes, spaltenorientiertes Datenbanksystem, das auf der Hadoop-Plattform aufsetzt. Apache HBase wurde entwickelt, um große Datenmengen schnell und effizient zu verarbeiten und ist besonders gut geeignet für Anwendungen mit hohen Anforderungen an die Skalierbarkeit.
In diesem Artikel wird HBase als Synonym für Apache HBase zur Verbesserung der Lesbarkeit verwendet.
Wie bei jedem verteilten System, kann es jedoch auch bei HBase zu Problemen kommen. Deshalb werden wir uns mit dem Troubleshooting von HBase befassen und uns speziell auf die Themen „Inconsistent Regions“, „Orphan Regions“ und das Tool HBCK2 konzentrieren. Wir werden einige Tipps und Tricks vorstellen, die Ihnen helfen können, diese häufig auftretenden Probleme zu lösen. Diese Tipps helfen uns bei unseren Kundenprojekten regelmäßig, einen ordnungsgemäßen Betrieb zu gewährleisten.
Also lassen Sie uns eintauchen in die Welt des HBase Troubleshooting!
HBase Regions - Was sind sie und warum sind sie fehleranfällig?
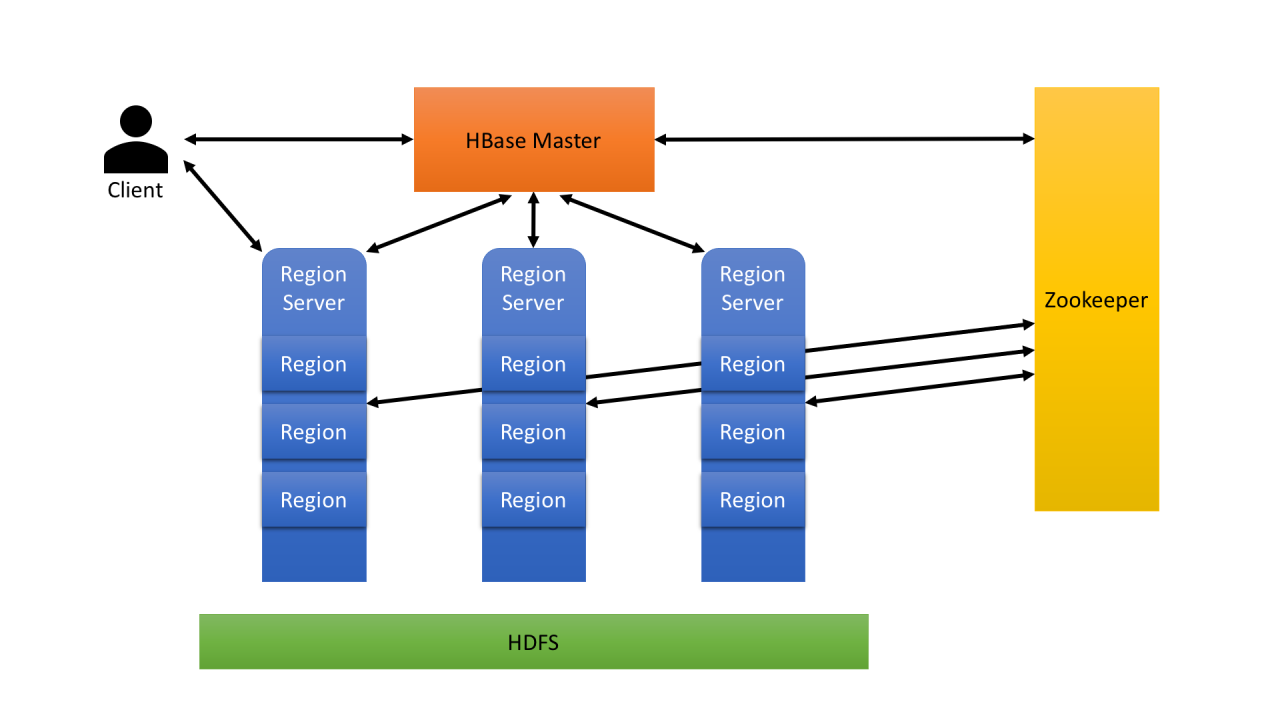
Bevor wir in die Probleme von HBase einsteigen, wollen wir kurz auf die allgemeine Architektur eingehen. Wie schon eingangs erwähnt, ist HBase ist ein verteiltes Datenbanksystem, das auf der Hadoop-Plattform aufsetzt. Es wurde entwickelt, um große Datenmengen schnell und effizient zu verarbeiten. Um dies zu erreichen, teilt HBase die Daten in sogenannte „Regions“ auf. Eine Region ist ein kontinuierlicher Bereich von Zeilen in einer Tabelle, der von einem RegionServer verwaltet wird.
Stellen Sie sich vor, Sie haben eine HBase-Tabelle mit Kundeninformationen. Die Tabelle enthält Millionen von Zeilen, wobei jede Zeile die Informationen eines Kunden enthält. Um diese große Datenmenge effizient zu verarbeiten, teilt HBase die Tabelle in mehrere Regions auf.
Jede Region enthält einen kontinuierlichen Bereich von Zeilen aus der Tabelle. Zum Beispiel könnte eine Region die Zeilen 1 bis 1.000.000 enthalten, während eine andere Region die Zeilen 1.000.001 bis 2.000.000 enthält. Jede Region wird von einem eigenen RegionServer verwaltet.
Durch die Aufteilung der Tabelle in mehrere Regions kann HBase die Daten auf mehrere Server verteilen und so die Skalierbarkeit des Systems erhöhen. Wenn ein Benutzer beispielsweise eine Abfrage ausführt, die nur Kunden aus einer bestimmten Region betrifft, muss nur der entsprechende RegionServer die Anfrage bearbeiten.
Allerdings sind Regions auch fehleranfällig. Es kann beispielsweise vorkommen, dass eine Region inkonsistent wird oder verwaist (orphan), was zu Problemen bei der Datenintegrität und -verfügbarkeit führen kann.
In den folgenden Abschnitten werden wir uns näher mit diesen Themen befassen und einige Tipps und Tricks vorstellen, die Ihnen helfen können, diese häufig auftretenden Probleme zu lösen.
HBase-Architektur
"Inconsistent Regions" - Warum sie auftreten und wie man das Problem erkennt und behebt
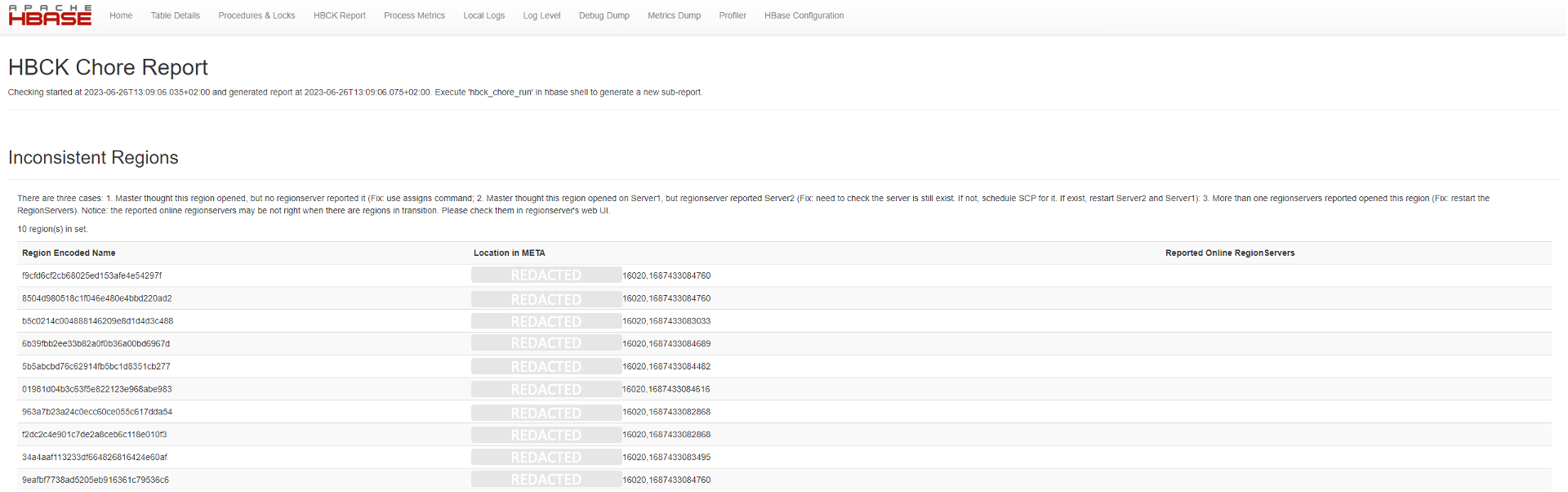
"Inconsistent Regions" treten auf, wenn die Metadaten einer Region nicht mit den tatsächlichen Daten übereinstimmen. Dies kann verschiedene Ursachen haben, wie zum Beispiel Netzwerkprobleme oder Hardwareausfälle. "Inconsistent Regions" können dazu führen, dass Daten nicht korrekt gelesen oder geschrieben werden.
Um "Inconsistent Regions" zu erkennen, können Sie das Tool HBCK2 verwenden. Dieses Tool überprüft die Integrität von HBase-Clustern und kann "Inconsistent Regions" identifizieren. HBCK2 ist Teil einer Sammlung von offiziellen HBase Tools, die man auf GitHub finden kann. Der Link dazu befindet sich am Ende des Artikels. Sie können auch die HBase UI verwenden, um den Status Ihrer Regions zu überwachen.
Sobald Sie eine "Inconsistent Region" identifiziert haben, können Sie das Problem beheben, indem Sie die betroffene Region reparieren oder neu erstellen. Hier sind einige Schritte zur Fehlerbehebung bei "Inconsistent Regions":
- Überprüfen Sie, ob es "not deployed" Regions gibt.
- Weisen Sie die oben genannten Regions zu. Wenn das Problem weiterhin besteht, starten Sie HBase neu.
- Weisen Sie die verbleibenden Regions zu. Wenn das Problem weiterhin besteht, starten Sie den aktiven Master neu.
- Lassen Sie HBase für etwa 12-24 Stunden laufen, um einen gesunden Status zu erreichen.
Es ist wichtig, regelmäßig Überprüfungen durchzuführen, um „Inconsistent Regions" frühzeitig zu erkennen und zu beheben. Auf diese Weise können Sie sicherstellen, dass Ihr HBase-Cluster stabil und zuverlässig läuft.
"Orphan Regions" - Was sind sie und wie erkennt und behebt man das Problem?
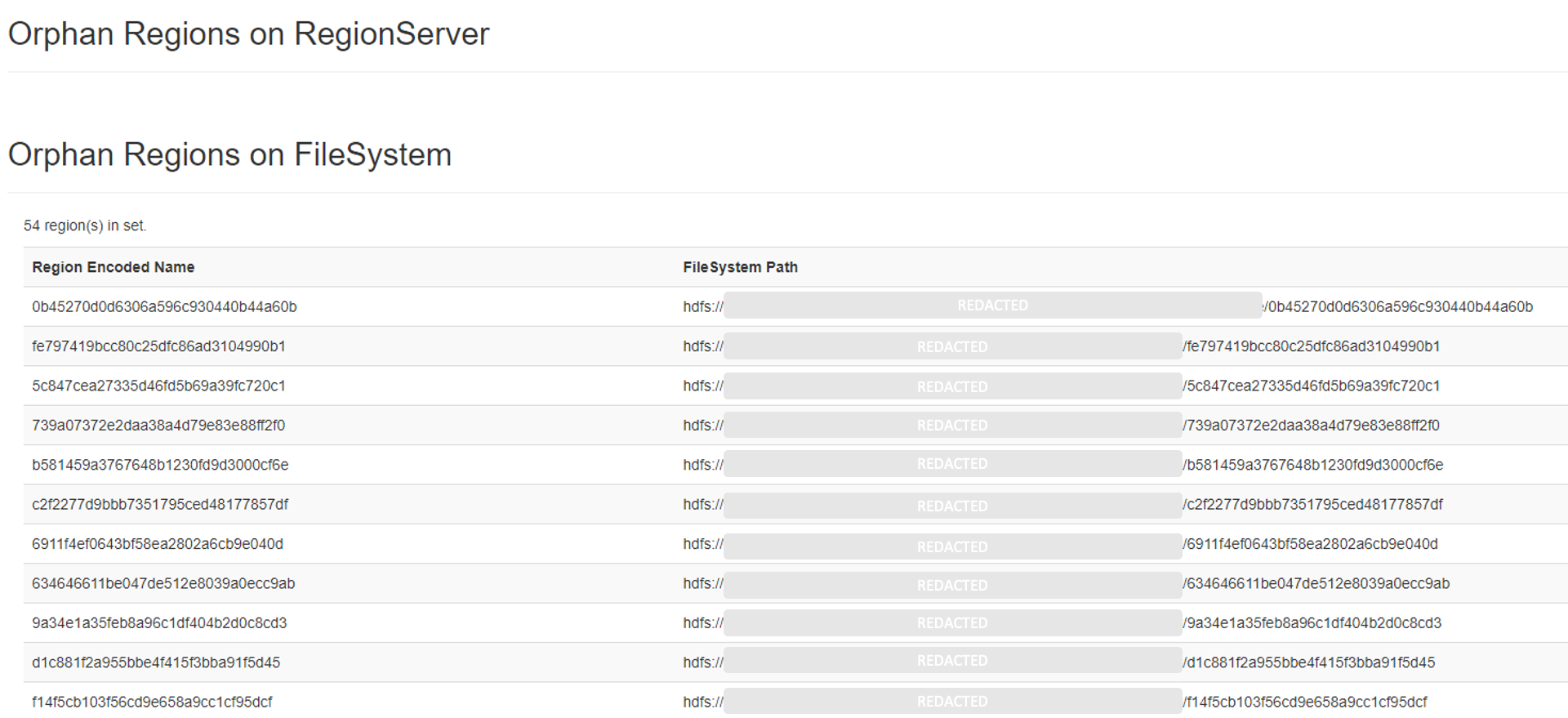
"Orphan Regions" sind Regionen, die in den Metadaten vorhanden sind, aber keinen zugehörigen Server haben. Dies kann verschiedene Ursachen haben, wie zum Beispiel Netzwerkprobleme oder Hardwareausfälle. "Orphan Regions" können zu Problemen bei der Datenverfügbarkeit führen, da Daten teilweise nicht korrekt gelesen oder geschrieben werden können.
Um "Orphan Regions" zu erkennen, können Sie ebenfalls HBCK2 verwenden. Dieses Tool überprüft die Integrität von HBase-Clustern und kann "Orphan Regions" identifizieren. Sobald Sie eine "Orphan Region" identifiziert haben, können Sie das Problem beheben.
Für die Fehlerbehebung bei "Orphan Regions" müssen sie alle aufgelisteten HDFS-Verzeichnisse prüfen:
- Wenn das Verzeichnis leer ist, können Sie das Verzeichnis sicher löschen.
- Wenn das Verzeichnis nicht leer ist, müssen Sie alle Änderungen (recovered.edits) "wiederherstellen" (Replay).
- Kopieren Sie alle Dateien in ein anderes Verzeichnis und stellen Sie sicher, dass der Dateiname das Format AAAA.BBBB hat (siehe hier).
- Führen Sie den WALPlayer für jede Datei aus.
Beispiel
hbase hbck -details > hbck_ouput_20221031.txt cat hbck_ouput_20221031.txt | grep "Orphan region in HDFS" | cut -d' ' -f16 | sed 's/!//' | sed 's/hdfs.//' | sort > orphaned_regions_20221031.txt hdfs dfs -mkdir /tmp/orphan_region_move/ hdfs dfs -cp /apps/hbase/data/data/<NAMESPACE>/<TABLE_NAME>/<REGION_Dir> /tmp/orphan_region_move/ hdfs dfs -mv /apps/hbase/data/data/<NAMESPACE>/<TABLE_NAME>/<REGION_Dir>/recovered.edits/0000000000000361724 /apps/hbase/data/data/<NAMESPACE>/<TABLE_NAME>/<REGION_Dir>/recovered.edits/0000000000000361724.0 hbase org.apache.hadoop.hbase.mapreduce.WALPlayer /apps/hbase/data/data/<NAMESPACE>/<TABLE_NAME>/<REGION_Dir>/recovered.edits/0000000000000361724.0 <TABLE_NAME>
Zunächst wird der Befehl hbase hbck -details ausgeführt und die Ausgabe in eine Datei namens hbck_ouput_20221031.txt umgeleitet. Dann wird die Ausgabe nach dem Text „Orphan region in HDFS“ durchsucht und die 16. Spalte der Ergebnisse extrahiert. Die extrahierten Ergebnisse werden dann von unnötigen Zeichen bereinigt und in eine Datei namens orphaned_regions_20221031.txt sortiert. Ein temporäres Verzeichnis namens /tmp/orphan_region_move/ wird erstellt. Die betroffene Region wird in das temporäre Verzeichnis kopiert. Die Datei recovered.edits/0000000000000361724 wird umbenannt in recovered.edits/0000000000000361724.0. Schließlich wird der Befehl hbase org.apache.hadoop.hbase.mapreduce.WALPlayer ausgeführt, um die umbenannte Datei auf die angegebene Tabelle anzuwenden.
Dieser Prozess behebt das Problem der „Orphan Regions“ in HBase.
Ähnlich wie bei „Inconsistent Regions“ ist es auch bei „Orphan Regions“ wichtig, dass regelmäßig geprüft wird, ob eben jenes Problem auftritt. Dadurch kann weiterhin sichergestellt werden, dass das HBase-Cluster stabil und zuverlässig läuft.
HBCK2
HBCK2 ist ein Tool, das von Apache HBase bereitgestellt wird, um häufige Probleme mit HBase-Clustern zu lösen. Es kann verwendet werden, um inkonsistente Regionen zu reparieren, verwaiste Regionen zuzuweisen und andere Probleme zu beheben. Hier sind einige Beispiele für die Verwendung von HBCK2:
Bypass Procedure
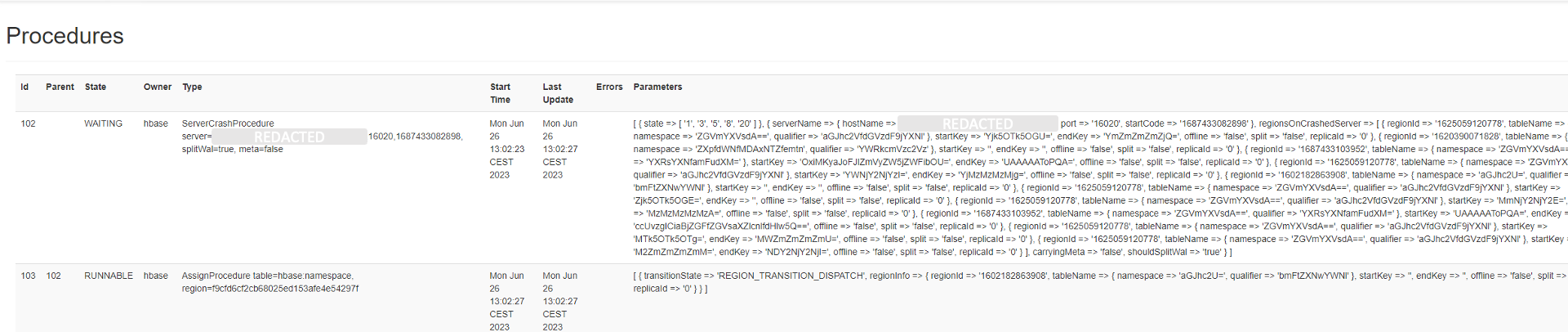
Bestimmte Prozesse von HBase werden als sogenannte Prozeduren durchgeführt und sind auch in der Weboberfläche von HBase im Tab „Procedures & Locks“ aufgelistet. Im obigen Beispiel sind gerade zwei Prozeduren in der Warteschlange: Eine „ServerCrashProcedure“, die nach jedem unerwarteten Neustart eines HBase RegionServers durchgeführt wird. Im Hintergrund werden dann nötige Aufräumarbeiten für den jeweiligen Server durchgeführt. Die „AssignProcedure“ dient dazu, eine Region einem RegionServer zuzuordnen. In diesem Fall war die betroffene Region vorher dem fehlerhaften RegionServer zugeordnet. Deshalb wird auch auf den Abschluss der „ServerCrashProcedure“ gewartet.
In Ausnahmefällen können die „ServerCrashProzedures“ nicht abgeschlossen werden und blockieren damit alle weiteren Prozeduren. Mit HBCK2 können Sie eine bestimmte Prozedur umgehen.
Bei den obigen Schritten der Region-Reparatur kann es zu Problemen kommen, die nicht ohne „Bypass“ behoben werden können:
hbase hbck -j hbase-HBCK2-1.1.0-SNAPSHOT.jar/hbase-HBCK2-1.1.0-SNAPSHOT.jar bypass -o -r [PROCEDURE_ID]
Bei der Ausführung kann mit der Option „-o“ die Ausführung erzwungen werden und mit der Option „-r“ alle darunterliegenden Prozeduren rekursiv zu beenden.
Assign Region
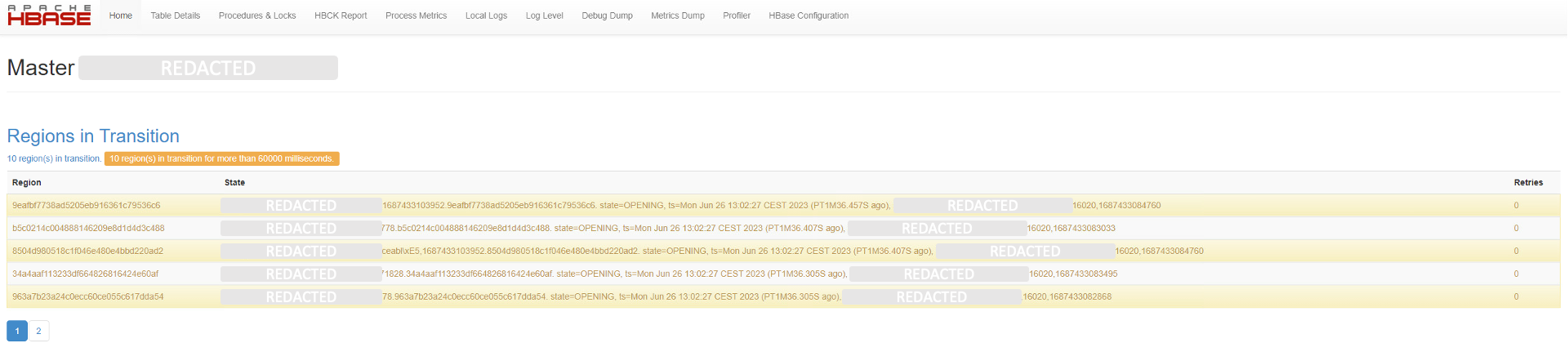
Sie können mit HBCK2 eine bestimmte Region zuweisen. Dies kann nützlich sein, wenn eine Region nicht automatisch zugewiesen wird oder wenn sie manuell verschoben werden muss:
hbase hbck -j hbase-HBCK2-1.1.0-SNAPSHOT.jar/hbase-HBCK2-1.1.0-SNAPSHOT.jar assigns -o [REGION_ID]
WALPlayer
HBase schreibt jede Änderung in sogenannte Write-Ahead-Logs (kurz WAL). Im Normalfall werden diese Dateien nie benötigt, da die Änderungen in kurzer Zeit festgeschrieben werden. Bei einem Ausfall eines Region-Servers kann es aber zu einer Diskrepanz kommen, weshalb die WAL-Datei meistens automatische wieder eingespielt wird. Bei größeren Ausfällen geschieht dieses Einspielen jedoch nicht. Um dies manuell zu erledigen, kann ebenfalls der bereitgestellte WALPlayer genutzt werden:
hbase org.apache.hadoop.hbase.mapreduce.WALPlayer /apps/hbase/data/data/<NAMESPACE>/<TABLE_NAME>/<REGION_Dir> /recovered.edits/0000000000000361724.0 <TABLE_NAME>
Weitere Informationen und Beispiele finden Sie auf der GitHub-Seite von HBCK2.
Fazit
In diesem Artikel haben wir uns mit dem Troubleshooting von HBase befasst und uns speziell auf die Themen „Inconsistent Regions“, „Orphan Regions“ und das Tool HBCK2 konzentriert. Wir haben gesehen, dass die beschriebenen Probleme verschiedene Ursachen haben können und dass es wichtig ist, regelmäßig Überprüfungen durchzuführen, um sie frühzeitig zu erkennen und zu beheben.
Wenn Sie mehr über HBase und das Troubleshooting erfahren möchten, empfehlen wir Ihnen, an einem unserer Hadoop Grundlagen & Administration Seminare teilzunehmen. In diesen Seminaren lernen Sie die Grundlagen von Hadoop und HBase kennen und erhalten praktische Tipps und Tricks zur Fehlerbehebung. Besuchen Sie unsere Website für weitere Informationen und zur Anmeldung.
Wir hoffen, dass Ihnen dieser Artikel geholfen hat, mehr über HBase Troubleshooting zu erfahren. Wenn Sie weitere Fragen haben oder Unterstützung benötigen, zögern Sie nicht, uns zu kontaktieren.
Links
[2] https://my.cloudera.com/knowledge/quot-ERROR-org-apache-hadoop-hbase-PleaseHoldException?id=286306
[3] https://my.cloudera.com/knowledge/HBase-table-orphan-region-issue?id=315316
[5] https://github.com/apache/hbase-operator-tools/tree/master/hbase-HBCK2
Seminarempfehlung
HADOOP GRUNDLAGEN HADOOP-01
ZUM SEMINAR
Kommentare