
Kafka Streams – mehr als nur Producer und Consumer
Bietet Kafka mehr als nur die Producer und Consumer API?
Als Event-Streaming-Plattform wird Kafka von Anwendungen dafür genutzt, Events entkoppelt zu schreiben, zu persistieren und abzurufen. Im Zeitalter der allgegenwärtigen Datenströme (Ubiquitous Computing) bietet Kafka ein Mittel, effizient, robust und hochverfügbar große Datenvolumen zu speichern und allen beteiligten Anwendungen bereitzustellen.
Wie kann nun eine datenstromverarbeitende Anwendung, mit möglichen Echtzeitanforderungen, mit Kafka umgesetzt werden? Welche Alternativen werden unterstützt, um einfaches Stream-Processing oder gar Real-Time-Processing zu implementieren?
Dieser Artikel ist ein Teil einer Serie, mit der ein generelles Verständnis für das Kafka-Ökosystem geschaffen werden soll. Zusätzlich möchten wir aufzeigen, wie Kafka für verschiedene Herausforderungen genutzt werden kann.
Einführung
Anwendungen nutzen die Producer API, um Events in Kafka zu schreiben und zu persistieren. Die Consumer API wird verwendet, um diese wieder zu lesen. Jedoch bietet die Kafka API mehr als die Funktionen Produce und Consume. Mit Kafka Streams und ksqlDB erhalten Entwickler zwei mächtige Werkzeuge, um Anwendungen mit komplexem Event-Processing einfach zu implementieren.
Dieser Artikel befasst sich mit Kafka Streams.
Kafka Streams
Kafka Streams ist eine Programmbibliothek, mit welcher die Implementierung von Anwendungen zur Echtzeitverarbeitung von Datenströmen auf Kafka vereinfacht wird. Als Teil des offiziellen Apache Kafka Projekts, ist Kafka Streams ein fester Bestandteil der Distribution.
Kafka Streams ermöglicht das Design und die Implementierung von zustandsloser (stateless) und zustandsbehafteter (stateful) Datenstromverarbeitung. Dabei können einfache Filter bis hin zu komplexeren Operationen, zum Beispiel Join, Map oder Aggregationen, angewendet werden. Zusätzlich können beliebig komplexe Prozessierungstopologien definiert werden.
Die zunehmenden Anforderungen an Echtzeitdatenprozessierung führten zur Entwicklung der Kafka Streams API. Zuvor wurden meist Batch- oder batch-orientierte Herangehensweisen durch Stream-Processing-Frameworks angeboten, die Kafka-Datenströme in Blöcke einteilen und verarbeiten.
Was Kafka Streams auszeichnet, wird im folgenden Kapitel beschrieben.
Warum eine zusätzliche Stream-Processing-API?
Der Unterschied im Prozessierungsmodell
Vor dem Release der ersten Kafka Streams Version in Kafka 0.10.0 im Jahr 2016, gab es hauptsächlich zwei Optionen zur Datenstromverarbeitung auf Kafka:
- Nutzung der Consumer und Producer APIs
- Nutzung eines Stream-Processing-Frameworks, zum Beispiel Apache Spark (Spark Streaming) oder Apache Flink
Datenstromverarbeitende Applikationen, die sich ausschließlich der Consumer und der Producer API bedienen, werden schnell zu komplex, da komplexe Operationen (Joins, Aggregationen, Grouping) eigenhändig implementiert werden müssen. Robustheit, Hochverfügbarkeit und Ausfallsicherheit müssen zudem von Applikationsentwicklern bei der Implementierung bewältigt werden.
Bei Stream-Processing-Frameworks, wie Spark Streaming und Apache Flink, muss beachtet werden, dass diese eine batch-orientierte Herangehensweise wählen, um Daten aus Kafka Topics zu lesen und wieder zu schreiben. Auch wenn diese Frameworks zwischen Stream- und Batch-Processing unterscheiden, so erfolgt die Umsetzung technisch jedoch mittels Micro-Batching.
Micro-Batching ist eine Variante des traditionellen Batch Ansatzes, in der kleine Datenmengen in höheren Frequenzen verarbeitet werden, anstatt eine größere Datenmenge auf einmal zu prozessieren. Dieser Ansatz ist nachteilig bei Echtzeitanwendungen, in denen niedrige Latenzen und kurze Antwortzeiten auf geschäftsrelevante Fragen gefordert werden.
Kafka Streams hingegen verfolgt jedoch die Strategie „Event-At-A-Time“, bei der jedes Event direkt bei Ankunft verarbeitet wird. Dieser Ansatz ist dem Micro-Batching-Ansatz hinsichtlich von Latenzen und Antwortzeiten überlegen. Im Gegensatz zu anderen Streaming-Frameworks unterstützt Kafka Streams jedoch nur Stream-Processing und kein Batch-Processing. Dies wird auch als Kappa-Architektur bezeichnet, im Gegensatz zur Lambda-Architektur, die beide Ansätze unterstützt.
Unterschiede im Deployment Modell
Stream-Processing-Frameworks, wie Apache Spark oder Apache Flink, benötigen üblicherweise dedizierte Plattformen oder Processing-Cluster, um datenstromverarbeitende Anwendungen zu betreiben. Dies verursacht eine zusätzliche Komplexität und höhere Kosten.
Kafka Streams hingegen ist eine Java Bibliothek, für welche Anwendungen keine dedizierten Cluster benötigen. Um eine Streams-Anwendung zu bauen, ist nur das Einbinden der Kafka Streams API als Java Dependency notwendig. Dies kann einfach mit Gradle oder Maven umgesetzt werden.
Das Design-Ziel von Kafka Streams ist die Bereitstellung eines Streaming-Modells für Anwendungen, welches die Anforderungen an Skalierbarkeit, Zuverlässigkeit und Wartbarkeit erfüllt.
Ist das alles? Was bietet Kafka Streams noch?
Basierend auf den Kafka Client-Bibliotheken, vereinfacht Kafka Streams die Datenstromverarbeitung auf Kafka Topics. Um die Folgekapitel besser verstehen zu können, werden zunächst ein paar Begriffe erläutert:
Kafka Streams ist eine Client-Bibliothek, die von einer Stream-Processing-Anwendung genutzt wird, um Datenströme zu prozessieren.
Ein Stream steht in Kafka Streams für einen unbegrenzten, kontinuierlichen Datenstrom.
"Kafka Streams is a client library for processing and analyzing data stored in Kafka." (https://kafka.apache.org/10/documentation/streams/core-concepts.html)
Flows vereinfacht
Kafka Streams folgt dem Paradigma Dataflow Programming, welches Programme als gerichtete Graphen darstellt, die Folgen von Eingaben, Ausgaben und Prozessierungsebenen enthalten. Die Daten fließen dabei beliebig zwischen den Verarbeitungsknoten.
Die Prozessierungslogik einer Kafka Streams-Anwendung wird als Directed Acyclic Graph (kurz: DAG, deutsch: gerichteter azyklischer Graph) strukturiert, der den Datenfluss über die verschiedenen Schritte steuert. Diese Schritte, auch „Processors“ genannt, formen dabei eine Topologie.
Es gibt drei Typen von Prozessoren:
- Source Processor (Quellprozessoren): Sie repräsentieren den Dateneingang der Kafka Streams-Applikation und können verschiedene Ursprünge haben. Beispielsweise kann eine Quelle ein anderes Kafka Topic sein. Daten eines Source Processors können wiederum von mehreren Stream Processors verarbeitet werden.
- Stream Processor (Datenstromprozessor): Sie wenden Transformationslogik auf den Datenstrom an, die sich an Operatoren bedient, die durch die Kafka Streams API bereitgestellt werden.
- Sink Processor (Senkprozessoren): Sie repräsentieren den Datenausgang, für die zuvor angereicherten oder transformierten Daten. Prozessierte Daten (Records) können wieder in Kafka Topics geschrieben oder an andere externe Systeme via Kafka Connect gesendet werden.
Eine Processing-Topologie ist daher ein Directed Acyclic Graph (DAG), der aus konkreten Source-, Stream- und Sink-Processoren besteht. Die folgende Grafik zeigt ein Beispiel für eine Topologie bestehend aus mehreren Processoren.
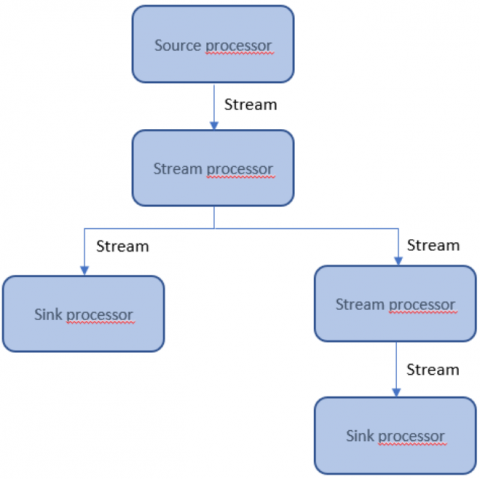
Eine einfache Topologie ist meist ein Triplet aus Input, Processing und Writing. Kafka Streams teilt eine Topologie in kleinere Subtopologien auf, die jeweils parallelisiert werden können. Die in Abbildung 1 dargestellte Topologie enthält eine Subtopologie (rechte Seite), die aus einem Stream und einem Sink Processor besteht.
Bei der tatsächlichen Prozessierung der Daten durchläuft Kafka Streams den DAG mittels einer Tiefensuche (Depth-First Search). So wird ein Record zunächst vollständig der Topologie nach verarbeitet, bevor der nächste Record gelesen wird.
In einer einfachen Topologie (ohne Subtopologien) wird also ein Record konsumiert, verarbeitet und gegebenenfalls geschrieben, bevor der nächste Record konsumiert wird.
Im Falle mehrerer Subtopologien wird die Depth-First Strategie, die einzelnen Subtopologien angewendet, welche die Records unabhängig voneinander verarbeiten. Die Regel Ein-Event-Gleichzeitig trifft nicht auf die gesamte Topologie, jedoch auf die einzelnen Subtopologien zu.
Datenströme abstrahiert: Streams und Tables
In Kafka Streams werden Daten auf zwei Arten modelliert: als Stream (auch Record Stream genannt) oder als Table (auch Changelog Stream genannt).
Ein Stream ist eine unveränderliche, unbegrenzte und geordnete Sequenz aus Records. Ein Record besteht vereinfacht aus einem Schlüssel-Wert-Paar (Key-Value-Pair). Damit entspricht der Stream einer Kafka Topic-Partition, welche die gleichen Eigenschaften erfüllt.
Eine Table hingegen repräsentiert einen Stream zu einem bestimmten Zeitpunkt – üblicherweise die Gegenwart. So kann eine Tabelle auch als kontinuierlich aktualisierte Sicht auf einen Stream betrachtet werden.
Zusammengefasst zeichnen Streams den Verlauf/die Historie auf und Tabellen repräsentieren den gegenwärtigen Status (siehe https://www.confluent.io/blog/kafka-streams-tables-part-1-event-streaming/).
Ferner erlaubt ein Stream nur das Konkatenieren neuer unveränderlicher Records, eine Table hingegen ist veränderlich, da einzelne Records eingefügt, aktualisiert oder gelöscht werden können.

Abbildung 2 veranschaulicht den Unterschied zwischen Stream und Table in der Zeitdomäne: User Interaktionen einer Webseite werden als Stream und als Table dargestellt. User Thomas löst ein Login-Event (siehe Offset 0) aus und zu einem späteren Zeitpunkt ein Logout-Event (siehe Offset 3). Der Stream enthält beide Events als Records in geordneter Reihenfolge. Die Tabelle hingegen enthält nur das Event, das als letztes verarbeitet wurde. Das zuvor verarbeitete Login-Event wurde also überschrieben.
Table und Stream können jeweils in die andere Struktur übertragen werden. Ein Stream kann zum Beispiel durch Aggregation oder Grouping zu einer Tabelle umgewandelt werden. Jede Veränderung eine Tabelle kann wiederum als Stream ausgegeben werden (Change-Data-Capture). Diese Austauschbarkeit wird auch als Stream-Table Duality bezeichnet.
Wenn Records in Kafka unveränderlich sind, wie können die Daten als Updates modelliert und in einer Table repräsentiert werden? Diese Frage wird im nächsten Kapitel beschrieben.
Stateless und Stateful Processing
Die Kafka Streams API kombiniert die zwei verschiedenen Datenmodelle Streams und Tables, um die Implementation zustandsloser (stateless) und zustandsbehafteter (stateful) Datenstromprozessierungen zu ermöglichen.
Beim Stateless Processing wird bei der Verarbeitung eines Records keine Kenntnis über vorherige Records benötigt. Ein Record wird daher gelesen, verarbeitet und vergessen.
Das Stateful Processing hingegen benötigt Informationen über bereits verarbeitete Records. Dies ist üblicherweise notwendig bei Aggregationen, Joins oder Verarbeitungen in (Zeit-)Fenstern. Daher müssen Zwischenschritte bei den Berechnungen zugreifbar sein, um die Processing Topology zu durchlaufen.
Kafka Streams bietet diverse Operatoren für das Stateful und Stateless Processing an. Zu den zustandslosen Operatoren gehören u. a. Filter (Records exkludieren oder inkludieren), Map (Felder entfernen oder hinzufügen), Branching (Aufteilung von Streams) oder Merging (Zusammenführung von Streams). Zustandsbehaftete Operatoren umfassen u. a. Count (Zählen), Sum (Summieren) oder Joins (Verbund).
Verwendet eine Anwendung nur zustandslose Operatoren, ist diese selbst zustandslos. Wird mindestens ein zustandsbehafteter Operator verwendet, so ist die Anwendung zustandsbehaftet.
Rich time-based operations
Der Zeitbegriff und die Modellierung dessen ist ein zentraler Aspekt in Stream Processing Frameworks. Verschiedene Zeitbegriffe haben Auswirkungen auf die Durchführung und die Ergebnisse bestimmter Operatoren (z. B. Windowing).
In Kafka Streams existieren die Zeitbegriffe Wall-Clock-Time, Event-Time, Ingestion-Time und Processing-Time, die im Folgenden erläutert werden.
Die sogenannte Wall-Clock-Time ist die physische Zeit der Umgebung, des Producers oder des Kafka Brokers.
Die Event-Time bestimmt den Zeitpunkt der Erstellung eines Events an der Quelle. Üblicherweise wird dies durch den Producer festgelegt und – sofern nicht anders konfiguriert – entspricht dem Zeitpunkt des Instanziieren eines Records.
Die Ingestion-Time wird durch den Zeitpunkt des Speicherns eines Records in eine Topic-Partition durch einen Broker bestimmt. Der Definition nach findet dies immer nach der Event-Time statt. Üblicherweise entspricht die Ingestion-Time beim Speichervorgang der Wall-Clock-Time.
Die Processing-Time ist der Zeitpunkt der Verarbeitung eines Records durch eine Streaming-Anwendung. Dieser Zeitpunkt kann erklärtermaßen nur nach Event- und Ingestion-Time stattfinden.
Mit der Topic-Konfiguration message.timestamp.type kann beeinflusst werden, ob entweder der originale Zeitstempel der Erstellung (CreateTime) oder der Zeitstempel des Schreibens beim Broker (LogAppendTime) übernommen wird. Diese Konfiguration kann auch für den gesamten Cluster bestimmt werden. Die Option CreateTime ist der Standardwert und entspricht der Event-Time Semantik.
Um Records mit demselben Key zu aggregieren oder zu verbinden (Join), nutzt Kafka Streams das sogenannte Windowing. Dieses Konzept steht in der Kafka Streams DSL zur Verfügung.
Diese zusammengefassten Records werden als „Windows“ bezeichnet und werden über den Record Key erfasst. Zwischen den Records besteht ein zeitlicher Zusammenhang, der im Falle der Event-Time Semantik ein Zeitraum der Erstellung und im Falle der Process-Time Semantik, ein Zeitraum der Prozessierung ist.
Folgende Window-Typen stehen in Kafka Streams zur Verfügung:
- Tumbling Windows: Zeitfenster mit fixierter Größe, die nie überlappen. Die Größe des Windows entspricht dem Abstand zum nachfolgenden Window. Deshalb ist ein Record immer genau einem Window zugewiesen. Durch die Ausrichtung an Epoch (Zeit 0), haben Tumbling Windows vorhersagbare Intervalle.
- Hopping Windows: Zeitfenster mit fixierter Größe, die überlappen können. Der Abstand zum nächsten Window kann kleiner als die Größe sein, daher können Records in mehreren Windows enthalten sein. Durch die Ausrichtung an der Epoche (Zeit 0), haben Hopping Windows vorhersagbare Intervalle.
- Session Windows: Zeitfenster mit variabler Größe, die nie überlappen. Das Verhalten wird durch eine Inactivity Gap bestimmt. Records mit demselben Key, die innerhalb der Inactivity Gap eintreffen, werden einem Fenster zugeordnet und das Fenster wird vergrößert. Trifft kein neuer Record innerhalb der Inactivity Gap ein, wird ein neues Fenster eröffnet. Beispiel: beträgt die Inactivity Gap 5 Sekunden, zählt jeder Record, der nicht später als 5 Sekunden nach seinem Vorgänger eintrifft, zum Fenster. Trifft ein Record später ein, wird ein neues Fenster erstellt.
- Sliding Windows: Zeitfenster mit fixer Größe, die überlappend, an den Timestamps der Records ausgerichtet werden und sich kontinuierlich fortbewegen. Zwei Records zählen zu einem Fenster, wenn die Differenz der Timestamps kleiner (<) der Window Size entspricht. Wird ein Record hinzugefügt oder entfernt, wird ein neues Window erstellt. Das Intervall eines Sliding Windows ist inklusiv.
Eine Grace Period (Deutsch: Gnadenfrist) definiert, wann Records als out-of-order deklariert und nicht in einem Fenster verarbeitet werden.
Im Falle zeitbasierter Operationen, verwendet Kafka Streams das Interface TimestampExtractor, um die Timestamps der Records zu erhalten. Das Standardverhalten ist die Verwendung des Timestamps, der durch den Producer (Event-Time) oder den Broker (Ingestion-Time) festgelegt wird. Ein eigener TimestampExtractor kann implementiert werden, um beispielsweise den Zeitstempel aus dem Value des Records zu extrahieren.
Vereinfachte und flexible Programmiermodelle
Es gibt zwei Wege, um in Kafka Streams Topologien zu definieren: die Kafka Streams DSL (domain-specific language) und die Processor API.
Die Streams DSL ist eine High-Level API, welche die Low-Level Processor API abstrahiert. Durch funktionale und deklarative Programmierung lassen sich in Java oder Scala Anwendungen zur Datenstromprozessierung implementieren. Die Abstraktionen für Streams (KStream) und Tabellen (KTable, GlobalKTable) erlauben zustandslose und zustandsbehaftete Transformationen und Windowing.
Die Processor API ist eine Low-Level API, die einen imperativen Ansatz verfolgt und mehr Flexibilität und Kontrolle beim Datenzugriff und dem Applikationszustand ermöglicht. Zusätzlich ist die Kontrolle über bestimmte, zeitbasierte Operationen feingranularer. Somit erlaubt die Processor API die Erstellung angepasster Prozessoren und Zugriff auf State Stores.
Das folgende Programmierbeispiel zeigt ein Hello World mit Kafka Streams DSL:
// the builder is used to construct the topology
StreamsBuilder builder = new StreamsBuilder();
// read from the source topic, "users"
KStream<Void, String> stream = builder.stream("users");
// for each record that appears in the source topic,
// print the value
stream.foreach(
(key, value) -> {
System.out.println("(DSL) Hello, " + value);
});
// you can also print using the `print` operator
// stream.print(Printed.<String, String>toSysOut().withLabel("source"));
// build the topology and start streaming
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
Für die Entwicklung eigener Prozessoren kann die entsprechende Schnittstelle implementiert werden, wie folgendes Beispiel zeigt:
// the builder is used to construct the topology
Topology topology = new Topology();
topology.addSource("UserSource", "users");
topology.addProcessor("SayHello", SayHelloProcessor::new, "UserSource");
// build the topology and start streaming!
KafkaStreams streams = new KafkaStreams(topology, config);
System.out.println("Starting streams");
streams.start();
public class SayHelloProcessor implements Processor<Void, String, Void, Void> {
@Override
public void init(ProcessorContext<Void, Void> context) {
// no special initialization needed in this example
}
@Override
public void process(Record<Void, String> record) {
System.out.println("(Processor API) Hello, " + record.value());
}
@Override
public void close() {
// no special clean up needed in this example
}
}
Fazit
Mit der Dataflow-Herangehensweise und Programmiermodellen zielt Kafka Streams auf die Vereinfachung von Anwendungen zur Datenstromverarbeitung. Dieser Artikel hat einen Überblick über Streaming, Kafka Streaming und die Konzepte dahinter verschafft. Der nächste Artikel dieser Reihe wird sich mit ksqlDB, einer Query Language für Kafka, beschäftigen.
Seminare zu den Themen Kafka, Kafka Streams oder ksqlDB finden Sie auf seminare.ordix.de.
Seminarempfehlungen
Apache Kafka Grundlagen
Zum SeminarApache Kafka eine Einführung - kostenloses Webinar
Zum SeminarSenior Chief Consultant bei ORDIX
Kommentare