
Der Zoowärter braucht Unterstützung - Komplexität und Abhängigkeiten im Hadoop-Zoo
Hadoop-Cluster bilden eine komplexe Plattform. Dies wird anhand der Kette von Abhängigkeiten aller involvierter Services eines Hive-Jobs aufgezeigt. In diesem Blogartikel geben wir Tipps, an welchen Stellen ein Admin bzw. Zoowärter die Fehlersuche beginnen kann. Ebenso bietet es Anwendern einen detaillierteren Einblick und ein besseres Verständnis für die eigenen Jobs.
Die Biene schafft es nicht allein
In der Regel werden Hadoop-Cluster von Distributoren bezogen, denn diese verkaufen eine Zusammenstellung der Hadoop-Services inklusive Support und prüfen auf Kompatibilität. Die Cloudera Data Platform (CDP) oder Dataproc in der Google Cloud können an dieser Stelle genannt werden. Ein weiterer Vorteil sind die Cluster Manager, die eine grafische Benutzeroberfläche zur Verwaltung der einzelnen Services und Server ermöglichen. Cluster Manager sind jedoch nicht in allen Distributionen gleich ausgeprägt oder überhaupt implementiert.
Auf dem CDP-Test-Cluster, der für die Erstellung dieses Artikels genutzt wurde, sind folgende Hadoop-Services installiert: Apache HDFS, Apache ZooKeeper, Apache YARN, Apache Hive mit der Execution Engine Apache Tez, Apache Ranger und Apache Atlas. Die HDFS-Hochverfügbarkeit über ZooKeeper ist eingeschaltet und es wird Kerberos genutzt. Hive sowie YARN sind standardmäßig redundant aufgebaut, um eine gewisse Ausfallsicherheit und paralleles Arbeiten zu ermöglichen.
Folgende HiveQL-Befehle werden in einer Beeline-Shell ausgeführt. Die Abfrage gibt aus einem Klima-Datensatz die maximale Temperatur pro Wetterstation pro Tag der Aufzeichnung aus und sortiert diese absteigend nach dem Datum und aufsteigend nach der Station.
use climate; select o.observation_date, o.station_id, s.region, o.max_temperature from txt_observation_daily o join txt_station s on (o.station_id = s.station_id) order by observation_date desc, station_id;
Im Hintergrund passiert jedoch mehr als nur die Abfrage der Daten aus einem zentralen Ort, wie es bei relationalen Datenbanken der Fall ist. Die nachfolgende Abbildung zeigt die Kette an Abhängigkeiten, die bei einem solchen Hive Job existiert.
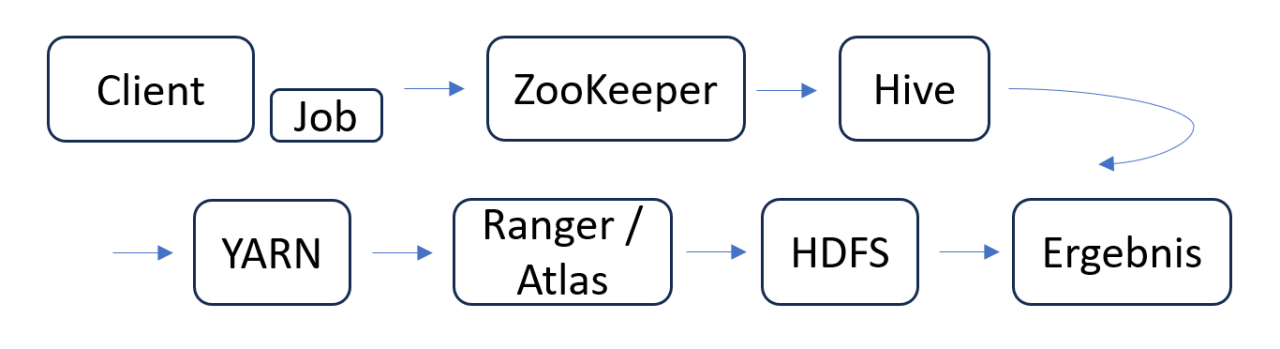
In einem Cluster mit Kerberos-Absicherung findet als Erstes die Authentifizierung des Benutzers per Keytab statt. Anschließend wird die Verbindung über Apache ZooKeeper mit Hive, dem Data Warehouse, hergestellt. ZooKeeper stellt Namensräume zur Verfügung, unter denen verschiedene Service-Gruppen angesprochen werden können. In der Service-Gruppe für den Hiveserver2 wird eine einzelne Instanz ausgewählt und die URL dem Client bzw. Job zurückgeliefert. In Hive wird anhand der HiveQL-Befehle ein Ausführungsplan erstellt und die benötigten Metadaten der Datenbank und der Tabellen beim Metastore abgefragt. Die HiveQL-Befehle werden anschließend mit den Metadaten auf syntaktische und semantische Fehler überprüft. Zusätzlich enthalten die Metadaten den Pfad der Daten im HDFS. Mit diesem Bündel an Daten und Informationen werden anschließend in YARN die im Job konfigurierten Ressourcen allokiert und alles zusammen in einer Applikation verpackt. Die Execution Engine Tez führt die eigentliche Bearbeitung der HiveQL-Befehle auf den verschiedenen Worker-Knoten aus, auf denen auch die Daten des HDFS gespeichert sind.
Meistens wird ein Cluster von mehreren Abteilungen und internen Kunden parallel genutzt. Für Zugriffsbeschränkungen auf die Daten sind daher Ranger und Atlas im Einsatz. Ranger beinhaltet Regeln, die Benutzern den Zugriff auf Daten und/oder die Benutzung eines Services (z. B. YARN) ermöglichen. Für die Abfrage muss dem Benutzer die Berechtigung über das Select Statement für die Tabellen txt_observation_daily und txt_station in der Datenbank climate erteilt werden. Grundsätzlich arbeitet Ranger nach der standardmäßig-verbieten-Zugriffskontrolle, was ein Vorteil bei mehreren Anwendungsfällen ist. Apache Atlas ist für Data Governance gedacht und bietet unter anderem Möglichkeiten zur Klassifikation und Identifikation von Daten und deren Metadaten. In Kombination mit Ranger lassen sich somit zum Beispiel Daten innerhalb der Bearbeitung eines Jobs maskieren oder verändern, um Datenschutzrichtlinien einzuhalten. In diesem Szenario ist dem Benutzer das Tag bzw. Label „NRW" zugeordnet und daher erhält dieser in der Ausgabe der Abfrage lediglich die Wetterstationen in NRW. Während der Bearbeitung des Jobs sind mehrere Rückschritte zwischen Hive, YARN und dem HDFS nötig, um die gesamten Befehle abzuarbeiten und dem Client das Ergebnis zurückzuliefern.
Was kann dabei schon schiefgehen?
Nachfolgend sind Fehlermeldungen aufgelistet, die in der Vergangenheit in unseren Kundenprojekten bereits aufgetreten sind. Passende Lösungsansätze sind ebenfalls beigefügt.
Fehlermeldung 1
Connecting to jdbc:hive2://hadoop1.ordix.de:2181, hadoop2.ordix.de:2181,hadoop3.ordix.de:2181/; serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2 Timestamp [main]: INFO jdbc.HiveConnection: Connected to hadoop1.ordix.de:10001 Timestamp [main]: WARN jdbc.HiveConnection: Failed to connect to hadoop1.ordix.de:10001 Timestamp [main]: WARN jdbc.HiveConnection: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop1.ordix.de:10001/;serviceDiscoveryMode=zooKeeper;\ zooKeeperNamespace=hiveserver2: null Retrying 0 of 1 [...] Timestamp [main]: ERROR jdbc.Utils: Unable to read HiveServer2 configs from ZooKeeper
Lösungsansätze:
- ZooKeeper auf Fehler überprüfen
- Überprüfen, ob ein valides Kerberos Ticket existiert
Fehlermeldung 2
Timestamp [main]: INFO jdbc.HiveConnection: Could not connect to the server. Retrying one more time.
Timestamp INFO execchain.RetryExec: I/O exception (org.apache.http.NoHttpResponseException)
caught when processing request to {s}->https://hadoop1.ordix.de:10001: The target server failed to respond
Timestamp INFO execchain.RetryExec: Retrying request to {s}->https://hadoop1.ordix.de:10001
Lösungsansätze:
- Hiveserver2 auf Fehler überprüfen
- Überprüfen, welche YARN-Queue verwendet wird und ob Berechtigungen bestehen bzw. bei der „default“ Queue, ob diese aktiv ist
Fehlermeldung 3
Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Vertex failed, vertexName=Reducer 3, vertexId=vertex_id, diagnostics=[Task failed, taskId=task_id, diagnostics=[TaskAttempt 0 failed, info=[Error: Error while running task ( failure ) : java.lang.OutOfMemoryError: Java heap space
Lösungsansatz:
- Job Ressourcen für YARN bzw. Tez erhöhen
Fehlermeldung 4
Timestamp: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table or View not found: txt_observation_daily
Lösungsansätze:
- Überprüfen, ob die Tabelle existiert oder ein Tippfehler vorliegt
- Ranger prüfen, ob Berechtigungen korrekt gesetzt sind
Immer nach der Reihe
Grundsätzlich ist es im Fehlerfall ratsam, die Kette der Abhängigkeiten von vorne bis hinten zu überprüfen. Ein Cluster Manager, sofern einer existiert, führt regelmäßig sogenannte Service-Checks aus und prüft darin unter anderem, ob die Ports der Services erreichbar sind. Dies ermöglicht das Finden von Fehlern auf einen Blick und erspart Zeit. Denn wenn andere Services funktionieren, die dieselbe Basis (z. B. das HDFS oder ZooKeeper) teilen, liegt der Fehler vermutlich woanders. Trotzdem ist eine separate Prüfung der Services und Sichtung der Log-Dateien oft nicht vermeidbar. Weiterhin sollte auf eine Distribution einer Hadoop-Plattform zurückgegriffen werden, denn die Distributoren nehmen einem die Prüfung der grundsätzlichen Kompatibilität der Services ab, was einige Fehlerquellen ausschließt. Gerade wenn kein Cluster Manager existiert, unterstützt ein zusätzliches Monitoring über zum Beispiel Grafana/Prometheus die Fehlersuche enorm und oftmals lässt sich der Fehler so eingrenzen.
Zusammenfassend wird deutlich, wie komplex der Aufbau eines Hadoop-Clusters sein kann und welche Abhängigkeiten dabei bestehen. Die Fehleranalyse endet oft nicht beim ersten Glied der Kette, sondern irgendwo dahinter. Ebenso muss der Fehler bei einer Hive-Abfrage, wie oben gezeigt, nicht unbedingt an Hive selbst liegen.
Seminarempfehlungen
HADOOP GRUNDLAGEN HADOOP-01
ZUM SEMINARHADOOP ADMINISTRATION HADOOP-02
ZUM SEMINAR
Senior Consultant bei ORDIX
Kommentare