
Künstliche Intelligenz in Produktion mit MLflow – Teil 1: Model Tracking
Der Einsatz von Künstlicher Intelligenz (KI) und Machine Learning (ML) ist auf dem Vormarsch. Dabei ergeben sich neue Herausforderungen im Vergleich zu klassischen Softwareentwicklungs-Projekten. In dieser Beitragsreihe beschreiben wir einige der technischen Herausforderungen bei der Inbetriebnahme von KI und stellen mit MLflow ein Tool vor, mit dem Prozesse vereinfacht werden.
Künstliche Intelligenz
Künstliche Intelligenz und maschinelles Lernen finden zunehmend Verbreitung in der deutschen Wirtschaft und immer mehr Unternehmen machen den Sprung von Prototypen und Machbarkeitsnachweisen zum eigentlichen Ziel: dem Einsatz von KI im produktiven Betrieb. Schließlich können sich die hohen Erwartungen an den Nutzen von Big Data erst erfüllen, wenn Werte mit KI-basierten Systemen aus den Daten extrahiert werden und als Produkte und Dienstleistungen den Kunden erreichen. Dabei zeigt sich häufig, auch nach unserer Erfahrung, dass die Inbetriebnahme von KI-Modellen mit beträchtlichen technischen Herausforderungen verbunden sein kann. Die gute Nachricht: Viele der über Jahrzehnte gewonnenen Erfahrungen und Methoden im Software Engineering sind übertragbar. Zusätzliche Herausforderungen ergeben sich, weil KI-Modelle nicht nur Abhängigkeiten bezüglich des Code, sondern auch bezüglich der Daten haben. Es gibt also mehr bewegliche Teile, die berücksichtigt werden müssen. In Anlehnung an DevOps treiben hier verschiedene Akteure unter den Schlagwörtern MLOps, ModelOps oder ML Lifecycle die Entwicklung voran. Dabei etablieren sich Tools wie MLflow, um den Herausforderungen in diesem Kontext zu begegnen.
MLflow
Das Open-Source-Tool MLflow (aktuell in Version 1.10.0., Releasedatum 20.07.2020) erleichtert das Protokollieren von Trainingsläufen sowie das Verwalten und Inbetriebnehmen von Modellen. Dafür werden einheitliche Datenstrukturen zum Speichern von Trainingsläufen und Experimenten zur Verfügung gestellt. Außerdem bietet das Tool ein Framework-unabhängiges Format zum Speichern von Modellen inklusive Abhängigkeiten. Die Funktionalität von MLflow ist in unabhängig verwendbare Module untergliedert, von denen zwei hier vorgestellt werden: MLflow Tracking und MLflow Models. Zur Bedienung werden Python-Bibliotheken und Command Line Interfaces (CLIs) bereitgestellt.
Problem 1: Model Tracking
Während der Entwicklungsphase suchen Data Science Teams nach guten Modellen für eine Problemstellung. Hier ist Flexibilität ein Schlüssel zum Erfolg. Verschiedene Bibliotheken und ML-Frameworks bieten Zugang zu aktuellen Entwicklungen. Daten werden aufbereitet, transformiert und angereichert. Dabei geht leicht der Überblick verloren: Wann wurde welches Modell trainiert? Mit welchen Daten? Welche Hyperparameter wurden gewählt? Wie war die Genauigkeit des Modells? Wo lag die benötigte Trainingszeit? Wie war die Latenz bei der Vorhersage? Jeder Trainingslauf ist also mit einem Set an Parametern und Metriken assoziiert, die zentral gespeichert werden müssen.
MLflow Tracking
Zu diesem Zweck kann das MLflow Tracking Modul verwendet werden. Der zentrale Bestandteil des Moduls ist der MLflow Tracking Server. Der Tracking Server ist ein HTTP-Server mit zwei Storage-Komponenten: Ein Backend Store und ein Artifact Store. Im Backend Store werden die Metriken und Parameter der Trainingsläufe gespeichert. Hier können Datenbankserver verwendet werden. Unterstützte Dialekte sind mysql, mssql, sqlite, and postgresql. Der Artifact Store speichert Artefakte, die beim Training der Modelle entstehen. Das sind in der Regel die Modelle selbst, können aber auch beispielsweise Datensätze mit Zwischenergebnissen sein. Neben dem lokalen Dateisystem werden eine Reihe von verteilten und cloud-basierten Speicheroptionen wie S3, Azure Blob Storage, HDFS oder FTP Server unterstützt. Der Tracking Server wird über ein CLI gestartet. Im Beispiel wird eine lokale sqlite Datenbank (mlflow.db) als Backend Store und das lokale Dateisystem als Artifact Store verwendet. Der Server horcht auf der URL http://0.0.0.0:8000.
mlflow server \ --backend-store-uri sqlite:////path/to/mlflow.db \ --default-artifact-root /path/to/directory \ --host 0.0.0.0 \ --port 8000
Die Adresse des Tracking Servers wird über eine Umgebungsvariable gesetzt.
export MLFLOW_TRACKING_URI='http://0.0.0.0:8000'
Jetzt kann über das CLI ein Experiment erstellt werden, dem Trainingsläufe zugeordnet werden. Wenn hier ein Pfad für den Artifact Store gesetzt wird, wird der Default des Servers ignoriert.
mlflow experiments create --experiment-name my_experiment --artifact-location /path/to/directory
Nun kann MLflow in Python-Scripten aufgerufen werden, um Metriken und Parameter aus Trainingsläufen über den Tracking Server zu speichern. Im Beispiel verwenden wir das Iris Flower Datenset. Das Datenset enthält Abmessungen von Stengeln und Blütenblättern verschiedener Unterarten der Schwertlilie. Aus den Abmessungen (=Features) wird die Unterart (=Target) vorhergesagt. Dafür wird als Modell ein Entscheidungsbaum trainiert. Genauigkeit und Art des Modells werden als Metrik bzw. Parameter in Key-Value Paaren gespeichert.
df = pd.read_csv("iris.data")
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:, [0,1,2,3]],df.iloc[ : ,[4]])
clf = DecisionTreeClassifier()
with mlflow.start_run() as run:
fitted_model = clf.fit(X_train, y_train)
acc = accuracy_score(fitted_model.predict(X_test), y_test)
mlflow.log_metric("accuracy", acc)
mlflow.log_param("classifier", clf)
Jeder Run ist über eine ID identifizierbar. Die Ergebnisse der Runs können entweder über direkte Queries an die Datenbank oder über den Tracking Server abgefragt werden. Für Abfragen über den Tracking Server wird eine REST-Schnittstelle sowie das Python-Modul mlflow.tracking bereitgestellt. Zusätzlich bietet der Tracking Server eine Web UI zum Explorieren der Ergebnisse, (siehe Abbildung 1).
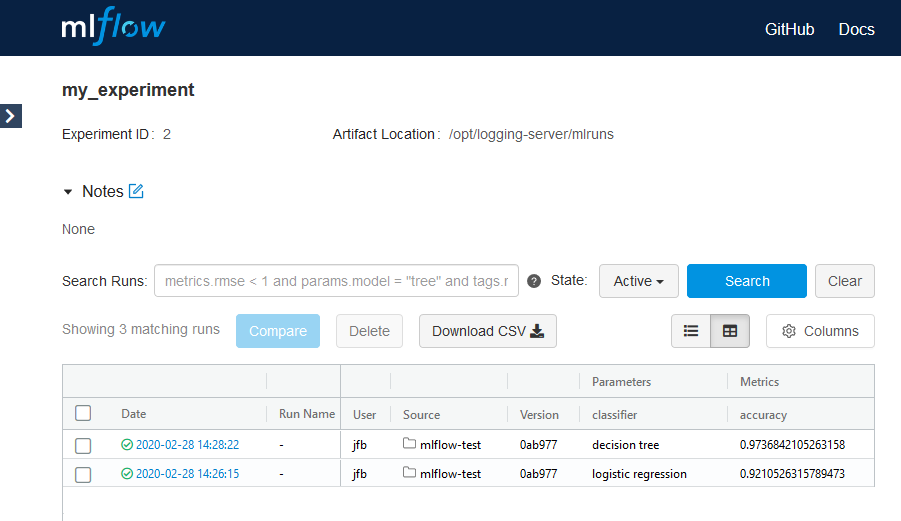
Links
Lesen Sie auch Teil 2: Model Management und Teil 3: Model Serving.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Big Data? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren
Kommentare