
Meine zweite Praxisphase bei der ORDIX AG: Apache Kafka Self-Service für OpenShift Deployment
Hallo zusammen, ich bin Simon, ein dualer Student bei der ORDIX AG. Ich studiere im vierten Semester Informatik. In den letzten drei Monaten habe ich einen Self-Service entwickelt. Dieser kann auf OpenShift ein Apache Kafka Cluster erstellen.
Arbeitsalltag
Mein Arbeitsalltag in den letzten Monaten war sehr angenehm. Für jedes Projekt bei der ORDIX AG wird einem mindestens ein Ansprechpartner zugeteilt. Dieser fungiert gleichzeitig als Betreuer und bei Rückfragen steht er immer zur Verfügung. Ich empfand es als sehr positiv, dass bei der ORDIX AG viel Wert auf eigenständiges Arbeiten gelegt wird. Auch die Arbeitsatmosphäre war sehr angenehm und persönlich, aber gleichzeitig professionell.
Tools
Für die Umsetzung meines Projektes habe ich mich mit einigen Tools auseinandergesetzt. Hierbei waren Docker und OpenShift am wichtigsten. Docker ist eine Containertechnologie und OpenShift eine Orchestrierungsplattform. Des Weiteren habe ich mich mit Java als Programmiersprache und dem Framework Spring Boot beschäftigt. Während der Entwicklung bin ich auf einige Probleme gestoßen. Aus diesem Grund habe ich mich zusätzlich noch mit SSL-Verschlüsselung und OpenShift-Routen beschäftigt. Auch habe ich mich ausführlich mit Apache ZooKeeper und Apache Kafka auseinandergesetzt: was diese beiden Anwendungen an Software benötigen, wie sie konfiguriert werden und vieles mehr.
Apache ZooKeeper ist ein verteiltes System. Es verwaltet die Meta-Informationen anderer verteilter Systeme. ZooKeeper hilft bei der Synchronisierung und Konfiguration der einzelnen Knoten des verteilten Systems.
Apache Kafka ist ein verteiltes, hochverfügbares Nachrichtensystem. Kafka kann genutzt werden, um Nachrichten zuverlässig zu übermitteln. Hierfür bietet Kafka ein Producing und Consuming System an. Nachrichten werden von den Producern in Topics produziert. Topics sind spezifische Themeneinheiten. Consumer folgen bestimmten Topics und empfangen deren neue Nachrichten. Apache Kafka benötigt Apache ZooKeeper um lauffähig zu sein.
Self-Service
Die Erstellung der Test-Infrastruktur von verteilten Systemen ist zeitaufwändig. Automatisierung ist hierfür eine interessante Lösung. Verteilte Systeme könnten hierbei mit wenig Wartezeit und Aufwand erstellt werden. Ein Self-Service, der dies bietet, ist für heutige agile Entwicklungsteams sehr wertvoll. Deshalb erhielt ich den Auftrag, einen Self-Service für das Erstellen eines Apache Kafka Clusters zu entwickeln.
Den Self-Service habe ich in Form eines Backends entwickelt. Programmiert wurde dieses in Java mit dem Framework Spring Boot. Die Anforderung lautete, ein skalierbares und konfigurierbares Apache Kafka Cluster auf OpenShift zu erstellen. Die Anzahl der Kafka- und ZooKeeper-Knoten und die Konfiguration beider Systeme sollte zudem anpassbar sein. Zusätzlich sollte eine bei der Erstellung mitgegebene Liste von Topics automatisch auf dem Kafka Cluster erstellt werden können. Des Weiteren sollte ich die Container, die auf der OpenShift-Plattform genutzt werden, selbst erstellen. Die OpenShift-Plattform stand bereits zur Verfügung.
Als erstes habe ich mir das Buch "Kafka: The Definitive Guide" über Apache Kafka durchgelesen. Hiernach habe ich schrittweise die Installation und Einrichtung in Containern umgesetzt. Nach vielen Tests und Problemen hatte ich drei fertige Container für beide Tools. Um dem Entwickler mehrere Auswahlmöglichkeiten bereitzustellen, wurden die beiden Applikationen auf drei unterschiedlichen Betriebssystemen aufgesetzt. Somit hat man mehr Spielraum für zusätzliche Programme wie beispielsweise kafkacat.
Nachdem meine Container fertig waren, setzte ich mich mit OpenShift auseinander. Ich fand relativ schnell ein gutes Tutorial wie Apache ZooKeeper in Kubernetes aufgesetzt wird. Apache Kafka war hier etwas schwieriger. Ähnlich dem Vorgehen beim ZooKeeper Cluster habe ich mit Anpassungen ein Kafka Cluster erstellen können. Im Laufe des Erstellungsprozesses sind mir noch weitere Fehler bei den "fertigen" Containern aufgefallen. Diese musste ich dann wiederholt verbessern.
Am Ende gab es ein großes Problem mit dem externen Traffic von Apache Kafka. Da Apache Kafka ein binäres Protokoll, basierend auf TCP, für den Datenaustausch nutzt, kam es hier zu Problemen mit den OpenShift-Routen-Objekten. Diese Routen funktionieren nämlich nur mit den HTTP-, HTTPS- und SSL-Protokollen. Nach einiger Zeit konnte ich das Problem mit der SSL-Verschlüsselung von Kafka lösen. Umgesetzt habe ich die Lösung mit jeweils einem Service und einer Route pro Container und Subject Alternative Names im SSL-Zertifikat.
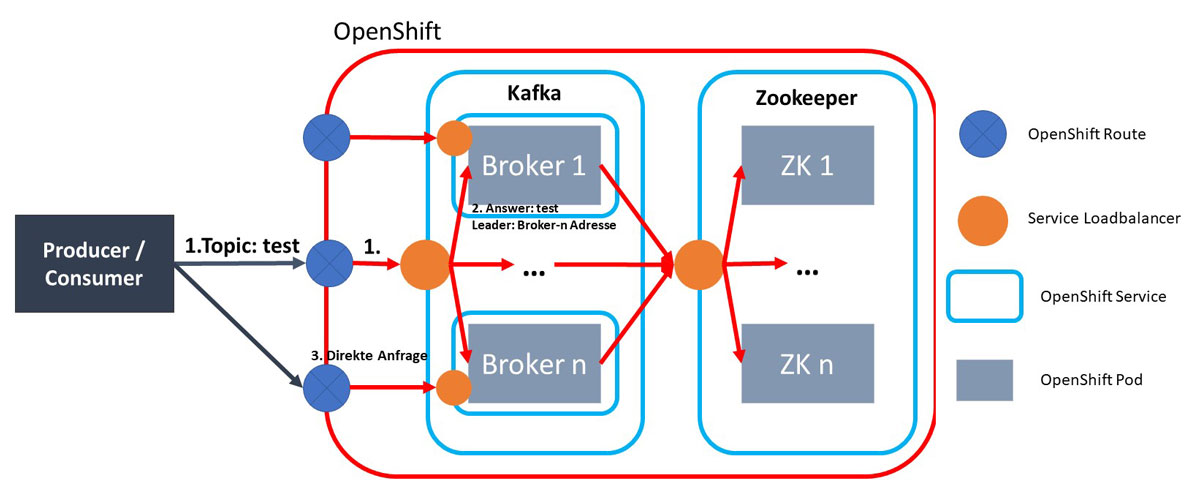
Als die manuelle Erstellung der Cluster beendet war, startete ich mit der Automatisierung. Ich suchte mir die benötigten OpenShift-Objekte zusammen und erstellte diese als Datentransferobjekte. Im Anschluss suchte ich mir die Variablen raus, die eine Anpassung benötigten. Für die Anpassungen und die Erstellung der Objekte schrieb ich Funktionen. Diese Funktionen haben die meiste Zeit in Anspruch genommen. Die Problematik hierbei war, dass die Funktionen jeweils nur kleine Teile des Erstellungsprozesses umsetzen. Dadurch war es schwer, den Überblick zu behalten.
Inzwischen funktioniert mein Self-Service aber ziemlich gut. Die Cluster führen zum Beispiel bei einer Konfigurationsänderung einen Rolling Restart durch. Das ist sehr praktisch, da das Cluster hierbei die ganze Zeit erreichbar bleibt. Auch haben mein Betreuer und ich noch viele weitere Ideen für interessante Funktionen. Beispielsweise automatisierte Producing-/Consuming Tests oder eine spezifizierbare Broker ID. Jedoch konnten diese leider nicht mehr umgesetzt werden.
Abschließend kann ich sagen, dass ich fachlich viele neue Dinge gelernt und zusätzlich auch viele praktische Erfahrungen gesammelt habe – beispielsweise vieles über SSL-Verschlüsselung mit mehreren Domain-Einträgen.
Kommentare