
NiFi trifft MCP – wenn der KI-Agent den Flow übernimmt
Stellt euch vor, ihr könnt eure NiFi-Flows mit natürlicher Sprache erstellen, steuern und verwalten. Anstatt im Canvas zu klicken, sagt ihr einfach „Erklär mir den Flow in dieser Prozessgruppe” oder „Erstell eine Verbindung zwischen InvokeHTTP und PutS3“. Genau dies ermöglicht der NiFi-MCP-Server. Dieser Beitrag zeigt, wie das Ganze in der Praxis verwendet werden kann.
Im ersten Teil der Serie haben wir das Model Context Protocol (MCP) vorgestellt. Es ist ein Protokoll, welches KI-Agenten eine standardisierte Schnittstelle zu externen Tools bietet. Wer diesen Grundlagenartikel noch nicht gelesen hat, dem empfehlen wir, dort einzusteigen. Im zweiten Teil gehen wir einen Schritt weiter und schauen uns an, wie MCP konkret für Apache NiFi eingesetzt werden kann.
Was ist der NiFi-MCP-Server?
Apache NiFi ist eine Open-Source-Plattform der Apache Software Foundation zur Automatisierung, Verarbeitung und Verwaltung von Datenflüssen zwischen verschiedenen IT-Systemen. NiFi deckt ein breites Einsatzspektrum ab und macht das alles über eine visuelle, Drag-and-Drop-fähige Web-Oberfläche zugänglich.
Der NiFi-MCP-Server ist ein Open-Source-Projekt, das NiFi als MCP-Server verfügbar macht. Ein verbundenes KI-Modell, wie Claude in Claude Desktop oder Cursor, kann damit direkt mit einer NiFi-Instanz kommunizieren. Es übernimmt dabei verschiedene Aufgaben: unter anderem Flows erstellen, Prozessoren inspizieren oder Connections anlegen.
Das Projekt unterstützt NiFi ab der Version 2.0. Ältere Versionen werden direkt beim ersten Aufruf abgewiesen. Für Umgebungen auf Basis der Cloudera Data Platform (CDP) ist eine Knox-Authentifizierung implementiert. Für Standalone-Installationen existiert ein Fork des Projekts, der zusätzlich Basic Auth über HTTP unterstützt.
Read-Only vs. Write-Modus
Der MCP-Server bietet zwei Betriebsmodi und folgt somit einem wichtigen Sicherheitsprinzip. Standardmäßig startet der Server im Read-Only-Modus. Das bedeutet, ein KI-Modell kann Elemente aus NiFi beobachten, verstehen und erklären, hat aber keinen schreibenden Zugriff auf die Instanz. Nur wenn NIFI_READONLY=false explizit gesetzt wird, kann das KI-Modell schreibend auf NiFi zugreifen.
Im Read-Only-Modus stehen 26 Tools zur Verfügung, mit denen ein KI-Agent eine NiFi-Umgebung erkunden kann. Typische Beispiele sind hierbei:
get_flow_health_status– umfassender Gesundheitscheck: Prozessoren, Controller Services, Verbindungen, aktive Fehlercheck_connection_queue– Warteschlangengröße einer Verbindung abfragen (FlowFiles + Bytes)search_flow– Volltextsuche über alle Komponenten eines Flowsget_bulletins– aktuelle Warnmeldungen und Fehler aus NiFi abrufen
Dies kann bereits genutzt werden, um Flows erklärt zu bekommen, Fehler zu finden, Optimierungspotenziale zu identifizieren oder neue Entwickler:innen in bestehende Flows einzuführen.
Werden schreibende Zugriffe aktiviert, erhält man viele zusätzliche Operationen. Das Spektrum reicht von einfachen Aktionen wie start_processor oder stop_processor über die Konfiguration und Erstellung von Prozessoren bis hin zu komplexen Bulk-Operationen:
start_all_processors_in_group– startet alle Prozessoren einer Gruppe auf einmalstart_new_flow– Prozessgruppen werden angelegt und Best Practices durchgesetztcreate_parameter_context– vollständige Parameterverwaltung für umgebungsspezifische Konfiguration
Ein technisches Detail, das man kennen sollte: NiFi nutzt optimistisches Locking. Jede schreibende Operation benötigt die aktuelle Revision eines Objekts. Der Agent muss also zuerst den aktuellen Stand abrufen, bevor er eine Änderung vornehmen kann.
Setup und Konfiguration
Der Server lässt sich auf zwei Wegen einbinden. Die erste Option ist eine lokale Installation über stdio. Diese eignet sich für Clients wie Claude Desktop, die ausschließlich lokale Prozesse unterstützen. Die zweite Option ist der HTTP/SSE-Transport. Dabei läuft der Server als eigenständiger HTTP-Prozess und eignet sich für Clients wie Cursor oder VSCode mit GitHub Copilot.
Option 1: Claude Desktop
Klonen des GitHub Repositories und Installation der nötigen Pakete:
git clone https://github.com/janis-ax/NiFi-MCP-Server.git cd NiFi-MCP-Server python3 -m venv .venv && source .venv/bin/activate pip install -e .
Anschließend kann die Konfigurationsdatei für Claude Desktop ergänzt werden.
{
"mcpServers": {
"nifi-mcp-server": {
"command": "/PFAD/ZUM/REPO/.venv/bin/python",
"args": ["-m", "nifi_mcp_server.server"],
"env": {
"MCP_TRANSPORT": "stdio",
"NIFI_API_BASE": "https://nifi.example.com:8443/nifi-api",
"NIFI_USER": "nifi_admin",
"NIFI_PASSWORD": "geheimes_passwort",
"NIFI_READONLY": "true"
}
}
}
}
Option 2: HTTP/SSE-Transport
Für Clients wie Cursor oder VSCode kann der Server als eigenständiger HTTP-Prozess gestartet werden.
MCP_TRANSPORT=http FASTMCP_PORT=3030 \ NIFI_API_BASE=https://nifi:8443/nifi-api \ NIFI_USER=nifi NIFI_PASSWORD=passwort \ uv run run-server
Der Client kann sich dann über den SSE-Endpunkt http://127.0.0.1:3030/sse mit dem MCP-Server verbinden.
Sicherheit: was ihr beachten solltet
Der MCP-Server für NiFi ist je nach Konfiguration nicht nur ein reines Beobachtungswerkzeug. Er kann einen Flow starten, stoppen oder sogar löschen. Die/der NiFi-Benutzer:in, welche:r sich mit dem Server verbindet, sollte nur die Rechte besitzen, welche auch tatsächlich benötigt werden. Destruktive Aktionen wie das Löschen von Elementen oder das Leeren von Warteschlangen sollten nur nach expliziter Aufforderung eine:r Nutzer:in geschehen. Claude Desktop zeigt Aufrufe vor der Ausführung an und gibt die Möglichkeit, diese zu prüfen und zu genehmigen. Der MCP-Server bietet zudem die Möglichkeit, verschiedene Loglevel zu definieren, um später alle Tool-Aufrufe nachvollziehen zu können.
Erfahrungen aus der Praxis
Im Rahmen eines Evaluationsprojekts wurden drei konkrete Use-Cases getestet.
Use-Case 1: Flow per Sprache erstellen
Die Aufgabe: „Erstelle mir einen Flow in NiFi: Aus der API https://dummyjson.com/users sollen Daten ausgelesen werden. Alle Relationships, außer NoRetry, Retry und Response, sollen in ein Funnel terminiert werden.”
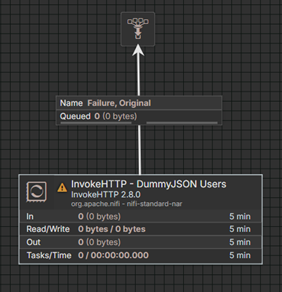
Das Ergebnis: Der Agent hat eigenständig einen InvokeHTTP-Prozessor angelegt, die URL konfiguriert und alle nicht benötigten Relationships korrekt in einen Funnel geleitet, ohne einen einzigen Klick im Canvas. Was sonst mehrere Minuten manueller Arbeit bedeutet, war in Sekunden erledigt.
Use-Case 2: Bestehenden Flow erklären lassen
Die Aufgabe: „Was macht der Flow in der Prozessgruppe ‚User Data Pipeline'? Fasse mir das in maximal zwei Sätzen zusammen.”
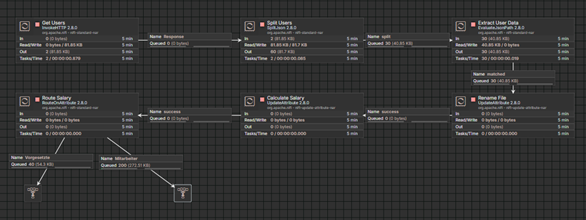
Die Antwort des Agenten war präzise und vollständig: „Der Flow ruft eine User-Liste per HTTP ab, splittet sie in einzelne User, extrahiert Felder wie id und role, berechnet daraus ein userSalary, routet nach Gehaltsklasse und benennt die Dateien nach user_id plus Zeitstempel um. Ergebnis: getrennte Ausgaben für Mitarbeiter:innen und Vorgesetzte mit konsistentem Dateinamen.”
Dieser Use-Case zeigt besonders gut, wie hilfreich der Read-Only-Modus bereits ist – etwa beim Onboarding neuer Teammitglieder oder bei der Dokumentation gewachsener Flows.
Use-Case 3: Code in einen NiFi-Flow übersetzen
Der interessanteste Test: Ein bestehendes Java-Programm – ein Kafka-Consumer, der Nachrichten in eine PostgreSQL-Datenbank schreibt – sowie das zugehörige SQL-Create-Statement wurden dem Agenten vorgelegt. Die Anfrage lautete schlicht: „Übersetz mir den Code in einen NiFi-Flow.”
package com.example.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.time.Instant;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaToDatabase {
public static void main(String[] args) throws Exception {
String topic = System.getenv().getOrDefault("KAFKA_TOPIC", "test-topic");
String bootstrap = System.getenv().getOrDefault("KAFKA_BOOTSTRAP", "localhost:9092");
String dbUrl = System.getenv().getOrDefault("DB_URL", "jdbc:postgresql://localhost:5432/kafka");
String dbUser = System.getenv().getOrDefault("DB_USER", "postgres");
String dbPassword = System.getenv().getOrDefault("DB_PASSWORD", "postgres");
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrap);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "kafka-db-consumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic));
Connection connection = DriverManager.getConnection(dbUrl, dbUser, dbPassword);
String insertSql = "INSERT INTO kafka_messages(message, created_at) VALUES (?, ?)";
PreparedStatement statement = connection.prepareStatement(insertSql);
System.out.println("Consumer gestartet...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
String message = record.value();
Instant timestamp = Instant.now();
statement.setString(1, message);
statement.setObject(2, timestamp);
statement.executeUpdate();
System.out.println("Gespeichert: " + message + " @ " + timestamp);
}
}
}
}
Der Agent hat die Aufgabe des Codes analysiert und daraus eigenständig einen funktionalen Flow gebaut: ConsumeKafka → BuildJson (via ReplaceText) → PutDatabaseRecord. Alle Prozessoren wurden korrekt verbunden und die Struktur des Originals sinnvoll auf NiFi-Komponenten abgebildet.

Möglichkeiten und Grenzen
Der NiFi-MCP-Server eröffnet eine Reihe von Einsatzmöglichkeiten, die den Arbeitsalltag mit NiFi spürbar vereinfachen können, bringt aber auch Einschränkungen mit, die man kennen sollte.
Was möglich ist:
Bereits vorhandene Workflows können analysiert, verständlich erläutert und in ihrem Ablauf transparent dargestellt werden. Das spart Zeit beim Onboarding und bei der Dokumentation. Neue Automatisierungen lassen sich durch Eingabe in natürlicher Sprache generieren, ohne manuelles Klicken im Canvas. Vorhandene Abläufe können zudem überprüft, optimiert und bei Bedarf erweitert werden.
Die Lösung lässt sich flexibel in verschiedene MCP-kompatible Chat-Plattformen einbinden. Von Claude Desktop über Cursor bis hin zu eigenen Anwendungen kann prinzipiell jeder MCP-kompatible Client verwendet werden. Dabei unterstützt der Server unterschiedliche Large Language Models (LLM), sodass das am besten geeignete Modell je nach Anforderung frei gewählt werden kann. Da das Projekt Open-Source ist, lassen sich fehlende Funktionen oder individuelle Anforderungen zudem problemlos als eigene Tools ergänzen.
Wo die Grenzen liegen:
Die Qualität der Ergebnisse hängt direkt vom eingesetzten LLM und dem verwendeten Chat-Tool ab. Komplexe Flow-Operationen erfordern Modelle mit Reasoning-Fähigkeiten, was sich jedoch schnell auf die Kosten auswirkt: Reasoning-Modelle verbrauchen deutlich mehr Tokens als einfache Completion-Modelle. Bei intensiver Nutzung oder komplexen Workflows können die Betriebskosten dadurch spürbar steigen. Wer den NiFi-MCP-Server produktiv einsetzen möchte, sollte die Token-Kosten daher frühzeitig in die Planung einbeziehen.
Fazit
Der NiFi-MCP-Server zeigt, wohin die Reise geht: weg vom manuellen Canvas-Klicken, hin zur natürlichsprachlichen Steuerung von Datenflüssen. Gerade für Teams, die NiFi produktiv einsetzen, lohnt sich ein genauer Blick. Schon der Read-Only-Modus bietet echten Mehrwert bei der Fehlersuche, beim Onboarding und bei der Dokumentation bestehender Flows. Das Projekt ist Open Source und auf GitHub frei verfügbar. Probiert es aus und überzeugt euch selbst, wie weit die KI-gestützte Flow-Steuerung bereits heute reicht.
Seminarempfehlungen
KI IN DER SOFTWAREENTWICKLUNG – ÜBERBLICK, EINORDNUNG, PERSPEKTIVEN [KI-SOFTWE]
Mehr erfahrenAPACHE NIFI GRUNDLAGEN [DB-BIG-07]
Mehr erfahrenNIFI ADVANCED WORKSHOP [DB-BIG-08]
Mehr erfahrenStudent
Kommentare