
Pandas Profiler statt Excel für die Ermittlung des Data-Value
In den Daten so mancher Firma stecke ein größerer Wert, so liest man es immer wieder. Aber wie kann dieser Wert ermittelt werden? Ausgangspunkt sollte hier eine fundierte Betrachtung der Datenbestände sein. Mit der Open-Source Bibliothek „Pandas Profiling" können verfügbare Daten in Tabellenformat, einer effizienten Analyse unterzogen werden. Dies ist als erster Schritt wichtig, um kurz- und langfristige Ziele auf dem Weg der Wertschöpfung zu erreichen. Hohe Datenqualität eröffnet Zugang zu hohem Wert bei der Nutzung der Daten und schafft Vertrauen in die Daten. Ist die Qualität bekannt, können Maßnahmen zu deren Steigerung ergriffen werden, um kontinuierlich die Ergebnisse (Added Value) der Datennutzung zu vergrößern.
Ausgangspunkt Daten-Sammlung
Heutzutage werden Daten gesammelt, deren Quelle und Inhalt zumindest grundlegend bekannt sind. Sobald diese Daten genutzt werden sollen, entsteht Interesse an detaillierteren Informationen über deren Eigenschaften. Welche Datenfelder sind enthalten? Was ist deren Datentyp und wie sind deren Werteverteilungen? Der erste Arbeitsschritt wird im Bereich Data-Science als Explorative Daten Analyse (EDA) bezeichnet. Diese kann mit verschiedenen Werkzeugen durchgeführt werden. So können Daten beispielsweise in Excel geladen und mittels verschiedener Diagramme visualisiert werden. Wer diese Arbeit schon einmal durchgeführt hat, kennt den Wunsch nach weniger Handarbeit und einem einheitlichen Bericht. Hier kommt Pandas Profiling ins Spiel.

Python ist in aller Munde
Python ist eine plattformunabhängige Programmiersprache, die sich dadurch auszeichnet, leicht erlernbar zu sein und die außerdem viele Anwendungsgebiete abdeckt. Der einfachste Weg Python zu nutzen, um interaktiv mit Daten zu arbeiten, ist die Entwicklungsumgebung Jupyter Notebook. Es handelt sich dabei um eine Software, die nach dem Starten automatisch einen Browser, wie Firefox oder Chrome, öffnet, um darin zu arbeiten. Um in den Genuss der professionellen Datenverarbeitung in Python zu kommen, werden Python und Jupyter benötigt. Ein sehr guter Weg, einfach eine funktionsfähige Umgebung aus einer Hand zu installieren, ist Anaconda (https://docs.anaconda.com/anaconda/install/windows/). Mit Anaconda können später beliebige Python-Bibliotheken nachinstalliert werden. Hier benötigen wir das Paket namens Jupyter. Dazu öffnen wir den Paket-Manager von Anaconda. Dort lässt sich Jupyter auswählen und sehr leicht vollautomatisch einrichten. Sicherlich benötigt man etwas Geduld, um sich in diesen Themenbereich einzuarbeiten, es sind jedoch unzählige Tutorials zu den Themen im Netz verfügbar. Wie Sie ihr erstes Jupyter Notebook aufbauen, soll deshalb hier nicht näher beschrieben werden.
So viel sei jedoch gesagt: Nach dem Start von Jupyter findet sich im Kopf die Schaltfläche „New". Wird darauf geklickt, kann die Auswahl „Python 3" als Kernel getroffen werden und ein leeres Notebook öffnet sich, es kann losgehen.
Mit Daten arbeiten, Pandas statt Excel
Um mit Python Daten zu verarbeiten, wird die Bibliothek Pandas verwendet. Dadurch stehen Dataframes als Speicherstruktur zur Verfügung. Diese sind grundlegend Excel-Tabellen sehr ähnlich, jedoch sind die Daten nicht unmittelbar sichtbar. Das ist kein Nachteil, da die Daten nicht händisch bearbeitet werden sollen. Um Pandas nutzen zu können, installieren Sie das Python Paket „pandas" auf dem gleichen Weg, den Sie auch für Jupyter genutzt haben.
Nun kann das neu erstellte Jupyter Notebook mit der erste Zeile Code beschrieben werden:
import pandas as pd
Daten beschaffen – Easy
Damit Sie einfach Daten zum Ausprobieren erhalten, können Sie das bekannte Iris-Dataset aus dem Netz herunterladen. Es wird gern für Data-Science-Experimente genutzt. Dazu muss die Web-Adresse und die Spaltenüberschriften definiert sein, um dann mit einem Kommando die Daten in einen Pandas Dataframe zu laden.
source_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" column_names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'species'] iris = pd.read_csv(source_url, names=column_names)
Alternativ können Sie auch mit Pandas-Mitteln einfach eine Excel Tabelle von Ihrer Festplatte laden.
Pandas gibt einen Überblick
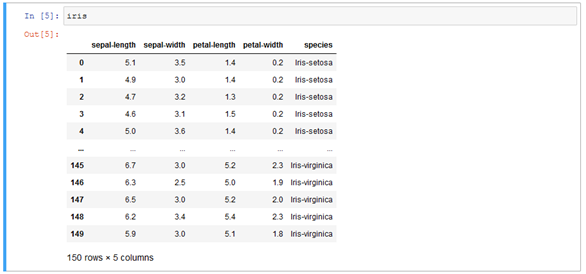
Um mit Pandas nun einen ersten Eindruck von den Daten zu bekommen, verwenden wir die verfügbaren Funktionen des Dataframes. Ein einfacher Aufruf des Dataframe Objekts mit seinem Namen „iris" führt zu einer tabellarischen Ausgabe.
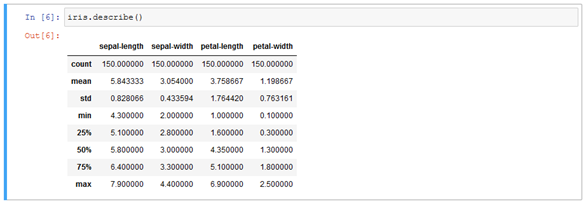
Pandas ermöglicht es, die wichtigsten, statistischen Kennzahlen der Daten zu erhalten. Dazu verfügt jeder Dataframe über die Funktion describe, die den Wertebereich und grundlegende statistische Informationen jeder Spalte ausgibt.
Pandas-Profiling ermöglicht genaue Einblicke
Mittels der Bibliothek pandas-profiling werden wesentlich aussagekräftigere Analysen zu einem umfassenden Bericht zusammengestellt. Nach dem Import der Bibliothek, wird der iris Dataframe zur Analyse an ProfileReport übergeben. Das Ergebnis ist ein Objekt, das bei Aufruf die Analyse durchführt und in Jupyter anzeigt. Eine Ausgabe in ein externes HTML-File ist ebenso möglich.
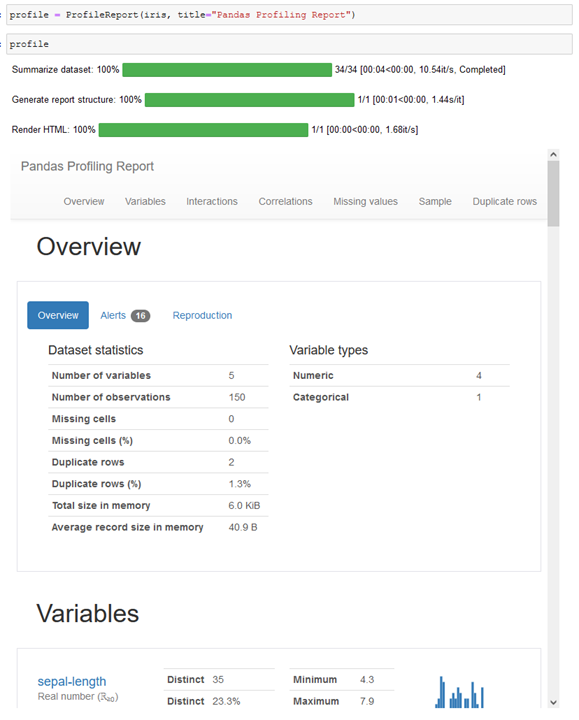
Pandas-Profiling Report
Die Ausgabe enthält alle relevanten Auswertungen, die für einen Datensatz in den meisten Fällen relevant sind. Der Report umfasst sieben Abschnitte, die im Kopf verlinkt sind. So können sich Domain-Experten über die Qualität der Daten informieren und gegebenenfalls Maßnahmen zur Verbesserung ergreifen. Data-Owner können sich über die Aussagekraft der Daten Gedanken machen, um eventuell weitere Parameter erfassen zu lassen. Data-Scientisten können mittels des Reports schnell die Möglichkeiten des Modellings ausloten und so klären, welche Fragestellungen mittels dieser Daten beantwortet werden können.
Overview
Der Bereich Overview stellt die wichtigsten Kennzahlen zur Verfügung, von der Anzahl der Spalten, über fehlende Werte und Duplikate, bis hin zum Speicherverbrauch des Dataframes. Außerdem stehen Alerts zur Verfügung, die zum Beispiel auf eine hohe Korrelation zwischen Spalten hinweisen.
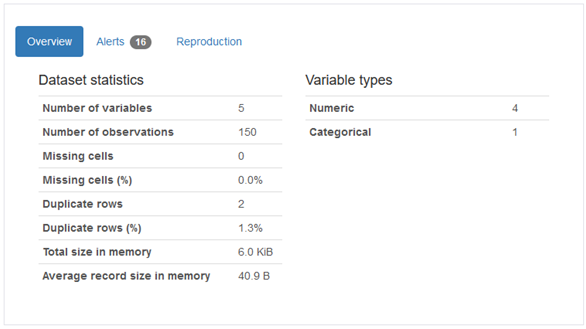
Variables
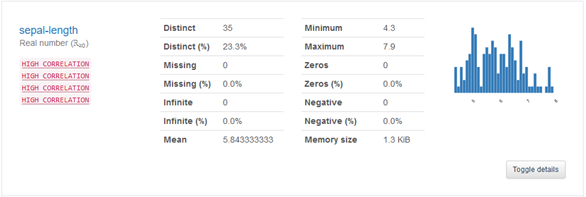
In diesem Abschnitt wird jede Spalte im Datensatz separat beschrieben. Neben den statistischen Kennzahlen ist bei numerischen Spalten ein Histogramm enthalten.
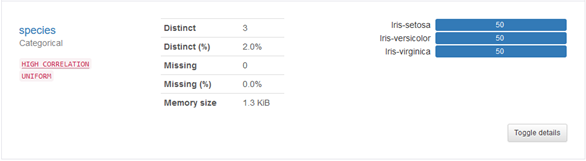
Die Analyse von kategorischen Daten zeigt die Häufigkeit der auftretenden Werte mittels eines Barcharts. Weiter unten wird auf die Box „Toggle Details" eingegangen.
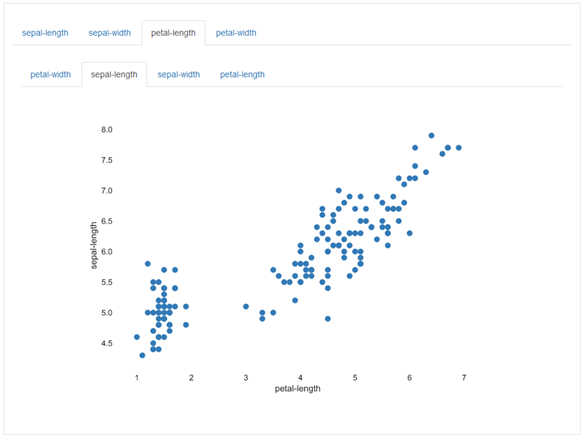
Interactions
In diesem Bereich können Zusammenhänge, also mögliche Korrelationen zwischen Spalten visuell untersucht werden. Dazu können mittels der Reiter, die X- und Y-Achsen des Plots ausgewählt werden. Hier sieht man einen möglichen Zusammenhang zwischen zwei Werten.
Correlations
Für die Berechnung von Zusammenhängen zwischen Parametern existieren verschiedene Maße. Ein sehr bekanntes Maß ist der Spearman's-Rho Wert. Auf die verschiedenen Maße soll hier nicht im Einzelnen eingegangen werden, da das den Rahmen des Blogs sprengen würde.
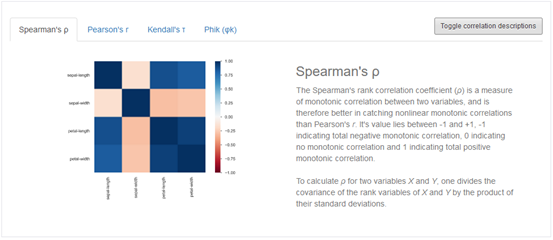
Deutlich erkennbar, an der dunkel blauen Färbung der ersten Fläche links oben in der Heatmap ist, dass die Breite eines Blütenblattes (petal-width), einen starken Zusammenhang zu deren Länge (petal-length) aufweist.
Missing values
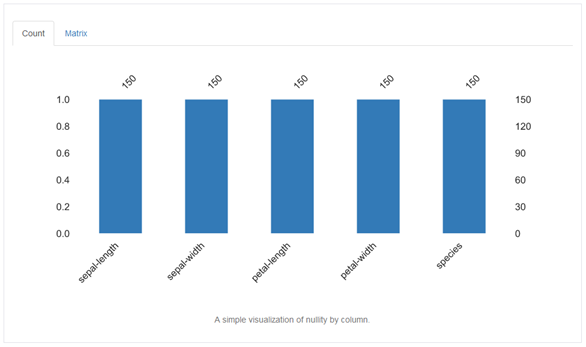
Das Fehlen von Werten stellt ein häufig auftretendes Problem bei der Datenverarbeitung, insbesondere beim Machine-Learning dar. Existieren zu bestimmten Zeilen einer Datensammlung einzelne Messwerte nicht, so müssen Maßnahmen ergriffen werden, um diese abzuschätzen oder die gesamte Zeile zu verwerfen. Deshalb ist diese Begutachtung besonders wichtig. Ist die Anzahl der leeren Zellen zu hoch, kann der gesamte Datensatz weniger zuverlässig Fragen beantworten. Im Falle des Iris-Datensatzes, den wir hier untersuchen, sind alle Datenpunkte vollständig.
Sample
Dieser Bereich ist dem Output des Iris-Dataframes (s.o.) gleich. Es werden die ersten und letzten Zeilen ausgegeben, sodass hier aus Platzgründen darauf verzichtet wird ihn abzubilden.
Duplicate rows
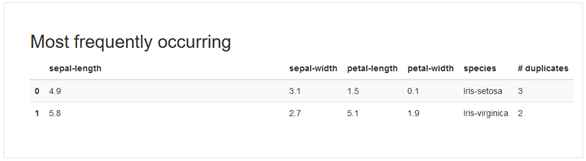
Die Dubletten in einem Datensatz können, je nach Aufgabenstellung, einen hohen Einfluss auf die Qualität der Ergebnisse haben. Soll mit den Daten beispielsweise ein KI-Modell trainiert werden, so können mehrfach auftretende Zeilen, das Model stärker in eine bestimmte Richtung beeinflussen. Dies kann zu unerwünschten Nebeneffekten führen. In vielen Fällen stellen Dubletten den Normalfall dar. Es muss entschieden werden, diese gegebenenfalls zu entfernen oder gegen einen robusten Ersatzwert auszutauschen. Bei den Schwertliliendaten Iris gibt es zwei Fälle von Mehrfachnennungen mit den gleichen Werten. Die Häufigkeit wird als letzte Spalte ausgegeben.
Variable Details
Wie oben beschrieben, können weitere Details bezüglich einzelner Variablen, in dem Report genutzt werden, um ein tieferes Verständnis für die Daten zu erlagen. Je Variable können durch den Button „Toggle Details" folgende Ansichten geöffnet werden.
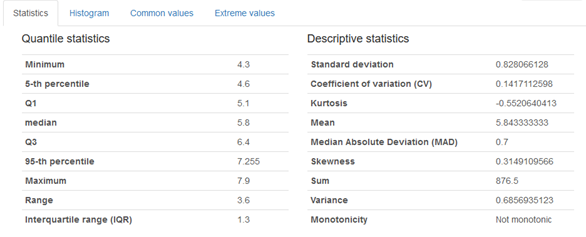
Während es sich bei den Quantil-Statistiken um bekannte Größen der Werteverteilung handelt, soll hier kurz auf einige der deskriptiven Statistikwerte eingegangen werden.
Standard deviation (Standardabweichung)
Die Standardabweichung beschreibt, wie stark die Werte des Datensatzes von dessen Mittelwert abweichen. Der Wertebereich liegt hier bei größer oder gleich Null. Zu beachten ist, dass die Standardabweichung mit der gleichen Einheit, wie die Werte selbst, behaftet ist.
Coefficient of variation, CV (Variationskoeffizient, Streuungskoeffizient)
Auch relative Standardabweichung genannt. Wird in Prozent (%) angegeben. Sie ist frei von der Einheit und der Größe des untersuchten Wertes, sodass die Abweichungen vom Mittelwert verschiedener Datensätze vergleichbar werden.
Kurtosis (Kurtosis, Wölbung)
Beschreibt wie steil der Verlauf innerhalb der Häufigkeitsverteilung ausgeprägt ist. Bei einer geringen Kurtosis (< 3) liegt eine breite Verteilung vor, die Streuung der Werte ist gleichmäßig. Bei einer hohen Kurtosis (> 3) handelt es sich im Vergleich zur Normalverteilung um eine steile, bzw. spitze Verteilung.
Mean (Mittelwert)
Der arithmetische Mittelwert, in Abgrenzung zum geometrischen und harmonischen Mittelwert, wird durch die Division der Summe aller Werte, mit deren Anzahl berechnet.
Median Absolute Deviation, MAD (Mittlere absolute Median-Abweichung)
Der MAD gibt an, wie stark die Werte im arithmetischen Mittel vom Median abweichen. Aufgrund der Robustheit des Medians gegen den Einfluss von Ausreißern, ist der MAD ein wertvolles Maß.
Skewness (Schiefe)
Die Schiefe der Werteverteilung beschreibt, inwiefern sich die vorliegende Verteilung, betrachtet in einem Histogramm, von der Normalverteilung durch eine Links- (Schiefe < 0) oder eine Rechts- (Schiefe > 0) Schieflage auszeichnet.
Sum (Summe)
Es werden alle Werte addiert und als Summe angezeigt.
Variance (Varianz)
Es handelt sich um die gewichtete, quadratische Abweichung der untersuchten Werte vom Mittelwert.
Monotonicity (Monotonie)
Ist ein Werteverlauf stetig ansteigend oder absteigend, so weist er eine Monotonie auf.
Fazit
Selbst, wenn Sie noch keine AI-Projekte mit ihren Daten planen, lohnt es sich die wenigen Minuten zu investieren, um statt mit Excel, einmal auf anderem Wege Kontakt mit Ihren Daten aufzunehmen.
Pandas Profiling liegt derzeit in der Version 3.1.0 vor. Es handelt sich um ein sehr nützliches Werkzeug für die Begutachtung von Datensätzen. Dabei kann der Anwendungsfall zwischen qualitätsbezogenen Aspekten der Datenerhebung oder denen des Dateneinkaufs variieren. Zur Nutzung der Daten, um Fragestellungen mittels AI/ML zu beantworten, stellt das Paket eine effiziente Lösung für den ersten vorgelagerten Schritt dar.
Seminarempfehlungen
MACHINE LEARNING BASICS DB-AI-01
Zum SeminarPYTHON PROGRAMMIERUNG FÜR FORTGESCHRITTENE P-PYTH-02
Zum Seminar
Kommentare