
Tabula Rasa – Mit Chatbots Kundenkommunikation neu denken
Im letzten Artikel der Blogreihe zu Chatbots wurden die grundlegenden Konzepte und Vokabeln eines Chatbots im Allgemeinen erläutert. Anhand von vereinfachten Beispielen wurde die abstrakte Architektur eines Chatbots erklärt und die Funktionsweise verdeutlicht. In diesem Artikel wird das Rasa-Framework vorgestellt und mit den Konzepten des vorherigen Blogartikels verknüpft. Dabei werden insbesondere die Natural-Language-Understanding-Komponenten als auch die Implementation eines Dialogue Managers näher betrachtet. Zudem werden Best Practices und das Paradigma des "Conversation Driven Developments" (CDD) eingeführt und veranschaulicht, wie damit schnelle und präzise Iterationen ermöglicht werden.
Rasa – Überblick
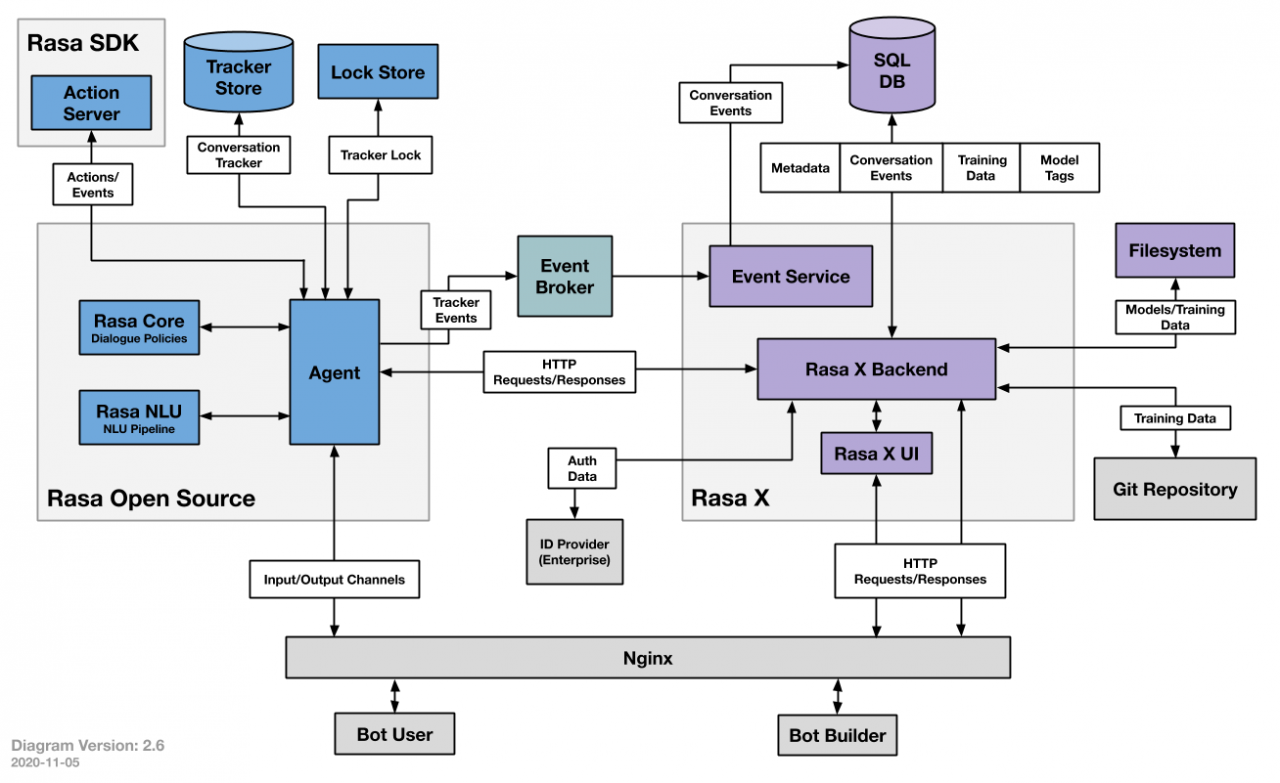
Rasa unterteilt sich in mehrere Module und Komponenten, welche im folgenden kurz erläutert werden. Das zentrale Modul ist Rasa Open Source, welches mit Rasa NLU und Rasa Core Möglichkeiten zum Verstehen von eingehenden Texten und dem Verwalten der Konversation (Dialogue Management) beeinhaltet. Mithilfe dieser Komponenten kann bereits ein Agent/Chatbot abgebildet werden. Um die Kontinuität während einer Konversation zwischen Nutzer und Chatbot beizubehalten, hat dieser zusätzlich Zugriff auf sogenannte Stores zur Persistierung des bisherigen Gesprächsverlaufs. Der Lock-Store beinhaltet dabei den sequentiellen Gesprächsablauf. Dabei wird gewährleistet, dass ein Nutzer mit einer beliebigen Instanz eines Rasa-Clusters sprechen kann, ohne dass vorhergegangene Daten verloren gehen. Der Tracker Store enthält bereits extrahierte Informationen in maschinenlesbarer Form. Dies sind zum einen Entities aus den Utterances des Nutzers und zum anderen durch den Chatbot gesetzte Informationen, welche Slots genannt werden. Diese werden durch den Chatbot-Entwickler im Voraus definiert, um die Interaktionen feingranularer steuern zu können und stellen das Gedächtnis des Chatbots dar.
User-Utterance: Alexa, spiele Cantina Band von John Williams.
Alexa: Spiele Cantina Band von John Williams.
User-Utterance: Alexa, spiel den selben Song nochmal!
Alexa: Spiele Cantina Band von John Williams.
Rasa X ergänzt diese grundlegenden Komponenten mit einem User Interface, welches eine zusätzliche Möglichkeit für das Trainieren von Modellen, Anlegen von Trainingsdaten und, besonders interessant, einer Möglichkeit die Oberfläche mit dem eigenen Team zu teilen um so auch nicht-technikaffinen Nutzern einen direkten Zugang für Tests zu schaffen. Durch die Option des "Interactive Learnings", also dem direkten Evaluieren und Korrigieren der gegebenen Antworten innerhalb einer Konversation, kann Einfluss auf die Entwicklung genommen werden.
Setup mit der Rasa CLI
Die bereits erwähnte CLI bietet die Möglichkeit, mit dem Befehl rasa init das Gerüst für ein vollständiges Projekt zu erstellen, inklusive kleiner Beispiele der einzelnen Komponenten. Dabei werden einige Ordner und yaml-Dateien erstellt, welche die Möglichkeit bieten, das Framework deklarativ nach den eigenen Anforderungen zu konfigurieren. Dies sind die zentralen Dateien, zugeordnet nach Aufgabenbereich:
- config.yml Konfiguration der NLU und Dialogue Manager Komponenten
- data/ Ablage für die NLU Trainingsdaten
- actions.py Eigener Code welcher die Funktionalität des Chatbots abbildet
- domain.yml Registry für Entities, Intents, Actions und Slots
Abbildung 2: Rasa-Ordnerstruktur
Im folgenden wird zunächst auf die Konfiguration der NLU Pipeline und des Dialogue Managers eingegangen.
Natural Language Understanding (NLU) Pipeline
Die Aufgabe des NLU ist es, die Absicht des Nutzers (Intent) und eventuell enthaltene Entitäten (Entities) aus der Nutzerinteraktion (Utterance) zu erkennen und zu extrahieren. Rasa stellt hierfür Abstraktionen für verschiedene gängige NLP-Methoden zur Verfügung, welche deklarativ in der config.yml angegeben werden. Weiterhin führt Rasa einen sehr aktiven Youtube-Channel, welcher eine Vielzahl an Videos und Playlists für fortgeschrittene Konzepte und Anwendungen enthält. Inbesondere für ein tieferes Verständnis der NLU Pipeline ist ein Blick in die Algorithm-Whiteboard-Playlist zu empfehlen.
Intent Classification
Grundlegende Basis für die Klassifizierung der Nutzerabsicht ist ein abstraktes Sprachmodell. Diese werden in der Regel mithilfe sogenannter Word Embeddings repräsentiert. Rasa bietet die Möglichkeit, bereits vortrainierte Embeddings anzubinden. Dazu zählen Sprachmodelle bekannter Libraries wie spaCy, Mitie oder HuggingFace. Zudem können eigens trainierte Embeddings eingebunden werden. Diese müssen auf der Basis von TensorFlow vorliegen. Mit der Wahl des Sprachmodells wird gleichzeitig auch die Wahl über die zu unterstützenden Sprachen getroffen. Bestimmte Modelle, wie beispielsweise das Multilingual BERT Embedding, ermöglichen eine Abstraktion über eine Vielzahl an Sprachen. Dabei ist jedoch immer ein möglicher Verlust an Präzision für eine spezifische Sprache im Vergleich zu einem speziell für diese Sprache trainierten Modell einzukalkulieren.
Named Entity Recognition (NER)
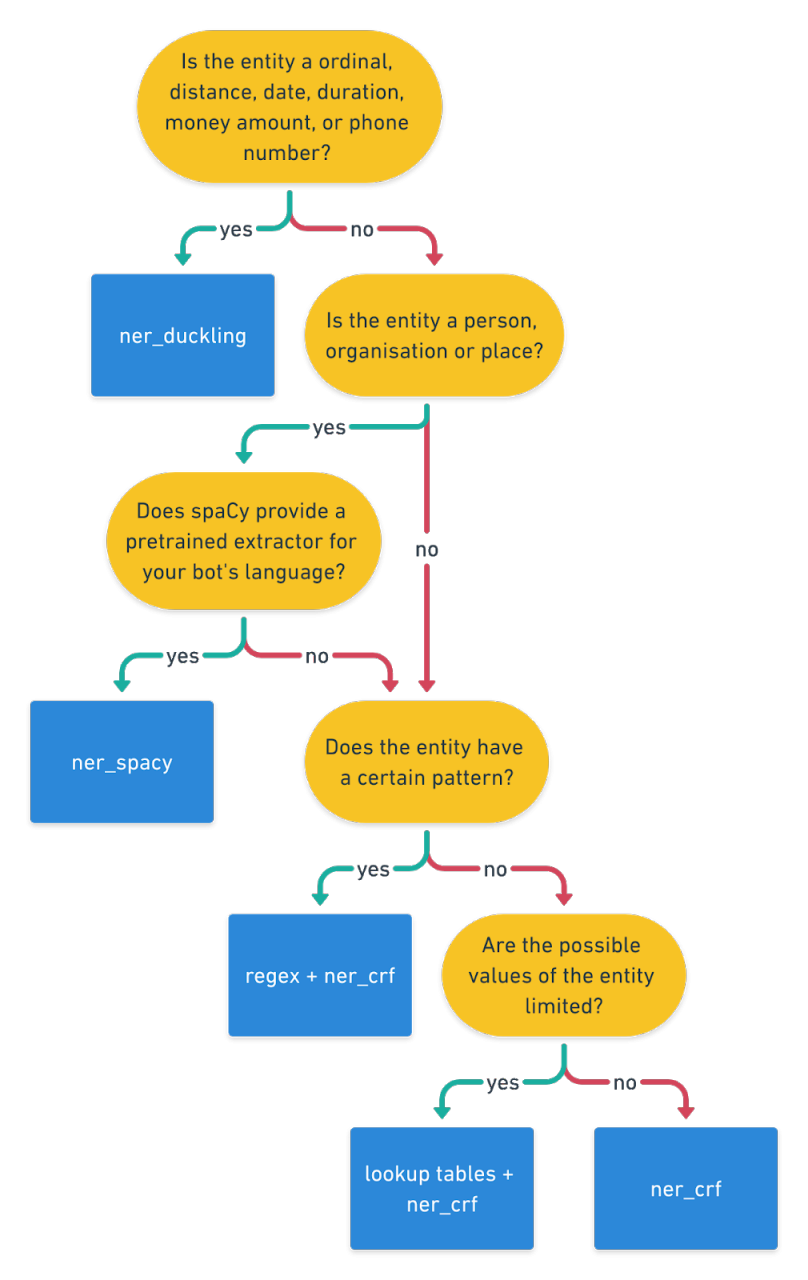
Auch zur Erkennung von Entities bietet Rasa eine Vielzahl an modularen und kombinierbaren Möglichkeiten. Die Entscheidung, welche Methode angewendet wird, sollte immer anhand der Art der zu extrahierenden Entities erfolgen. Handelt es sich um bekannte Personen, Orte oder Organisationen, bietet spaCy bereits vortrainierte NER-Modelle, die hierfür sehr gut funktionieren. Sollen numerische Werte, wie Geldbeträge, Daten, Distanzen oder Zeiträume und deren Einheiten erkannt werden, eignet sich Duckling hervorragend für diese Aufgabe. Sollen darüber hinaus eigene Entity-Typen erkannt werden, die durch diese Bibliotheken nicht abgedeckt werden, so sollte zwischen vollständig bekannten und nicht vollständig bekannten Entity-Typen unterschieden werden. Ist jede Ausprägung der Entity bekannt, kann quasi ein Wörterbuch hinterlegt werden, welches der entsprechenden Entity zugeordnet wird. In NER-Kreisen wird dabei häufig von einem Dictionary oder Gazetteer gesprochen. Ist nicht jede Ausprägung bekannt, oder existiert eine praktisch unendliche Menge an Ausprägungen, welche aber einem exakt definierbarem Muster folgen, kann ein simpler regulärer Ausdruck angegeben werden, welcher die Entity extrahiert. Ist das zugrunde liegende Muster jedoch nicht trivial durch einen regulären Ausdruck beschreibbar und die Menge an Ausprägungen nicht bekannt oder unendlich, kann ein eigener NER-Classifier mit Rasa hinterlegt und trainiert werden. Dadurch kann aufgrund der vorliegenden Trainingsdaten versucht werden, ein Muster zu generalisieren.
Für viele dieser Entscheidungen hat Rasa in der Dokumentation und in diversen Blogeinträgen Flussdiagramme hinterlegt, mit denen schnell die passende Methode gefunden werden kann.
NLU Beispielkonfiguration
language: de_core_news_sm
pipeline:
- name: SpacyNLP
- name: SpacyTokenizer
- name: SpacyFeaturizer
- name: RegexEntityExtractor
case_sensitive: False
use_lookup_tables: True
use_regexes: True
- name: RegexFeaturizer
- name: "DucklingHTTPExtractor"
url: "http://duckling:9999"
dimensions: ["time"]
locale: "de_DE"
timezone: "Europe/Berlin"
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
- name: FallbackClassifier
threshold: 0.6
Die oben abgebildete Konfiguration für die NLU Pipeline ist ein mögliches Beispiel für einen deutschen Chatbot. Zunächst wird die Sprache bzw. der Name des zu verwendenden Embeddings im Attribut language angegeben. In der darauffolgenden Pipeline werden nun in absteigender Priorität die zu verwendenden Komponenten deklariert. Jede Komponente bietet wiederum eigene Möglichkeiten zur Konfiguration der bereitstehenden Parameter, welche in der Dokumentation ausführlich beschrieben werden. In der obigen Konfiguration ist als letzte Option zudem ein FallbackClassifier angegeben. Dies bietet die Möglichkeit, bei vermeintlich erkannten Nutzerabsichten mit einem Konfidenzwert, welcher den angegebenen Schwellwert unterschreitet, eine Standard-Behandlungsroutine zu hinterlegen.
Dialogue Manager
Der Dialogue Manager ordnet die Nutzeranfragen den zuvor definierten Aktionen zu. Dafür bietet Rasa mehrere Strategien, welche ebenfalls wie die Komponenten der NLU Pipeline kombinierbar und in ihrer auszuführenden Reihenfolge wechselbar sind. Diese Strategien werden in Rasa "Policies" genannt. Die erste dieser Policies ist die Memoization Policy. Diese vergleicht die aus den Nutzeranfragen erkannten Intents mit den Szenarien innerhalb der Trainingsdaten und folgt den dort definierten Pfaden, sofern diese exakt übereinstimmen. Dadurch wird eine gewisse Verlässlichkeit in der Behandlungsroutine des Chatbots für bekannte Pfade gewährleistet.
Eine erste Ergänzung dazu ist die Rule Policy. Diese macht Vorhersagen anhand zuvor fest definierter Regeln, im Stile von if-else-Statements:
Wenn erkannter Intent X
Dann Action Y
Dies ist besonders nützlich für starre Frage-Antwort-Szenarien, welche keinerlei Kontext aus vorhergegangenen Interaktionen benötigen.
Durch die schier unbegrenzten Möglichkeiten eine Anfrage zu formulieren, ist es jedoch nicht ohne weiteres möglich, diese über händisch formulierte Regeln und Beispiele abzudecken. Das heißt, es muss darüber hinaus eine Generalisierung stattfinden, um von den Trainingsdaten abweichende Formulierungen sinnvoll behandeln zu können. Dafür hat Rasa ein eigenes Modell namens Transformer Embedding Dialogue (TED) entwickelt, welches anhand der Trainingsdaten versucht, ähnliche Anfragen zuzuordnen.
Eine Konfiguration könnte beispielsweise so aussehen:
policies:
- name: RulePolicy
core_fallback_threshold: 0.4
core_fallback_action_name: "action_default_fallback"
enable_fallback_prediction: True
- name: MemoizationPolicy
- name: TEDPolicy
max_history: 8
epochs: 200
constrain_similarities: true
split_entities_by_comma: true
Diese Policies können zudem unterschiedlich priorisiert werden. Im Falle, dass mehrere Policies ein unterschiedliches Ergebnis mit einem gleich hohen Konfidenzwert ausgeben, kann so bestimmt werden, welche Policy Vorrang hat. Die Standard-Prioritäten sehen wie folgt aus:
6 - RulePolicy
3 - MemoizationPolicy or AugmentedMemoizationPolicy
1 - TEDPolicy
Auch hierzu bietet Rasa wiederum detaillierte Informationen in der dazugehörigen Dokumentation.
Eine weitere Möglichkeit, um den Gesprächsfluss zu steuern, ist, den bisherigen Verlauf der Konversation in die Entscheidungsfindung mit einzubeziehen. Dies kann mit Rasa in recht granularer Art und Weise realisiert werden mithilfe der bereits erwähnten Slots. So kann für jeden Slot entschieden werden, ob dieser Einfluss auf die Konversation hat. Diese Konfiguration findet ebenfalls in der Domain.yml statt:
...
slots:
seminars:
type: text
influence_conversation: true
...
Training Data & Tests
Rasa spaltet die Menge an benötigten Trainingsdaten in drei verschiedene Arten auf. NLU, Rules und Stories, welche im folgenden näher beschrieben werden.
NLU
Die NLU-Trainingsdaten enthalten alle Intents und die dazu modellierten Phrasen und ihre Entities. Das bedeutet, dass für jeden Intent eine beliebige Menge an Beispielen hinterlegt werden kann, wobei eine gewisse Mindestanzahl (15-20 Stk.) vorhanden sein sollte, um dem Machine-Learning-Modell die Gelegenheit zu geben, ausreichend generalisieren zu können. Diese Phrasen können zudem Entities enthalten, welche mit einer speziellen Syntax gekennzeichnet werden.
- intent: seminar_details
examples:
- Ich möchte mehr Informationen zu [Einführung in Maschinelles Lernen](seminar).
Ebenfalls können hier reguläre Ausdrücke und Entity-Dictionaries hinterlegt werden, welche dann von der entsprechenden Komponente in der NLU Pipeline berücksichtig werden.
Rules
Die bereits im Abschnitt zum Dialogue Manager eingeführten Rules werden hier hinterlegt. Wie bereits erwähnt, sollten diese zum Modellieren von Szenarien verwendet werden, welche nur einen Konversationszyklus benötigen und auf keinen vorhergehenden Kontext zugreifen.
Stories
Im Gegensatz dazu eignen sich Stories für flexiblere Szenarien, deren Aktionen von den vorhergehenden Interaktionen abhängig sind und mehrerer Zyklen bedürfen. Hier können zudem weitere Bedingungen gesetzt werden für das Erreichen eines gewissen Pfades, wie beispielsweise ein bereits gesetzter Slot mit einer gewissen Ausprägung. Folgendes Beispiel zeigt eine mögliche Interaktion, in der ein Nutzer Informationen zu den ORDIX Seminaren erfragt, wobei ein "Drilldown" anhand der bereits extrahierten Informationen erfolgt.
stories:
- story: seminar_drilldown
steps:
- intent: seminar_categories
- action: seminar_categories
- slot_was_set:
- category: SQL
- action: category_seminars
- intent: seminar_details
- slot_was_set:
- seminar: true
- action: seminar_details
Während des Trainierens der Modelle wird zudem eine Augmentierung der Trainingsdaten auf Grundlage der Stories durchgeführt, um für eine bessere Generalisierung zu sorgen. Dabei werden Teile von Stories vertauscht und vermischt, um Overfitting zu vermeiden. Diese Option lässt sich abschalten, um die Gefahr zu minimieren, eventuell ähnliche Pfade zu verwechseln.
Rasa bietet zudem auch eine Visualisierung der Entscheidungspfade mit dem Kommando rasa visualize an, welche im interaktiven Testmodus (rasa interactive) live aktualisiert werden, um das Debugging zu vereinfachen.
Forms
Um das Erfragen von nötigen Informationen innerhalb von definierten Pfaden zu vereinfachen, bietet Rasa sogenannte Forms, welche als Action aus Stories oder Rules heraus aufgerufen werden kann. Dabei werden die zu erfragenden Entities und Slots in der Form definiert und anhand von zuvor definierten Utterances vom Nutzer erfragt. Diese Utterances folgen dabei diesem Schema zur korrekten Zuordnung: utter_ask_<form_name>_<slot_name>
Diese Abfragen können zudem in einer Schleife ausgeführt werden, bis alle benötigten Slots gesetzt wurden. Hier sollte jedoch bedacht werden, dass auch eine Möglichkeit zum Abbruch der Anfragen im jeweiligen Pfad deklariert wird. Damit kann dem Nutzer die Gelegenheit gegeben werden, seine Anfragen umzuformulieren, falls der Chatbot aufgrund von Fehlinterpretationen einen nicht gewünschten Pfad erreicht hat.
Tests
Eine weitere Funktionalität von Rasa ist das Testen des Chatbots anhand vordefinierter Szenarien, die es auf jeden Fall abzudecken gilt. Dabei können mehrere Dateien angelegt werden, welche um Nutzeranfragen ergänzte Stories enthalten, die rasa test durchlaufen und auf Korrektheit geprüft werden. Sollte der Chatbot von den deklarierten Pfaden abweichen, wird die jeweilige Story als fehlerhaft ausgegeben, um diese genauer überprüfen zu können.
Testdateien müssen das Präfix test_ im Namen enthalten und sind wieder im .yml-Format anzulegen. Ein mögliches Beispiel könnte wie folgt aussehen:
stories:
- story: Simple test story for seminar drilldown
steps:
- user: |
Guten Tag
intent: greet
- action: utter_ask_howcanihelp
- user: |
Welche Seminare bietet ihr an?
intent: seminar_overview
- action: utter_seminar_overview
- user: |
Ich interessiere mich für das Seminar "Einführung in maschinelles Lernen".
intent: seminar_details
slot_was_set:
seminar: true
- action: seminar_details
Abbildung 4: Pfad Visualisierung
Custom Actions
Um einem Chatbot sinnvolle Funktionalität mitzugeben, ist es nötig, eigenen Code in den Chatbot einbetten zu können. Dies kann in Rasa mittels sogenannten Custom Actions realisiert werden. Dafür stellt Rasa wie eingangs erwähnt eine eigene SDK für Python zur Verfügung, es ist jedoch grundsätzlich möglich, diesen in einer beliebigen Sprache umzusetzen. In der eigenen Dokumentation finden sich hierzu mehr Informationen.
Die Definition einer Action benötigt minimalen Boilerplate und kann von der Action-Klasse der Rasa-SDK abgeleitet werden:
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
from rasa_sdk.events import SlotSet
from typing import Any, Text, Dict, List
class MyCustomAction(Action):
def name(self) -> Text:
return "action_name"
async def run(
self, dispatcher, tracker: Tracker, domain: Dict[Text, Any],
) -> List[Dict[Text, Any]]:
# ... eigener Code
return [SlotSet("slot_name", value)]
Dabei muss lediglich der Name der Klasse angegeben werden, welcher als solcher auch in der Domain.yml registrierten werden muss. Die run-Funktion erlaubt anschließend das Ausführen von beliebigem Code, sei es Datenbankanfragen, Berechnungen oder statische Ausgaben. Über das Tracker-Object kann auf Entities, Slots und vorhergegangene Intents zugegriffen werden. Die SlotSet-Methode dagegen erlaubt es, Slots zu befüllen. Mit dem Dispatcher-Objekt können Antworten des Chatbots gesetzt werden, wobei die Art der Ausgabe von den Möglichkeiten des gewählten Channels abhängt.
Deployment & Channels
Rasa bietet eine Vielzahl von Konnektoren zu bekannten Messengern und anderen Channeln. Darunter Slack, Facebook Messenger, Telegram, Microsoft Teams und Google Hangouts. Um diese zu nutzen, müssen lediglich in der durch rasa init generierten credentials.yml die nötigen Zugangsinformationen hinterlegt und die Einstellungen im jeweiligen Nachrichtendienst beachtet werden. Es können auch eigene Konnektoren entwickelt werden, welche eine Anbindung an andere Services realisieren. Es lohnt sich eine eigene Google-Recherche dazu, ob für den gewünschten Service bereits ein Konnektor durch die sehr aktive Open-Source-Community um Rasa bereitgestellt wurde. Zudem kann über die REST-API jede beliebige Anwendung angebunden werden. So kann beispielsweise ein bereits bestehender Livechat auf der eigenen Webseite einfach um einen Chatbot ergänzt werden.
Best Practices
Die Entwicklung eines Chatbots ist quasi nie abgeschlossen, da er immer weiter verbessert und um zusätzliche Funktionalität erweitert werden kann. Um dennoch möglichst schnell eine robuste Kernfunktionalität zu entwickeln, sollten einige Best Practices beherzigt werden.
Rasa formuliert diese als Conversation Driven Development (CDD) in folgenden Schritten:
- Share Frühest mögliches Teilen mit (Test-)Nutzern des Chatbots
- Review Regelmäßige Betrachtung echter Konversationen
- Annotate Labeln von Nachrichten zur Datengenerierung
- Test Durchführung von Tests, um Funktionalität zu gewährleisten
- Track Fehler loggen und so Performanceschwankungen ausfindig machen
- Fix Korrektur von Verhalten welches zu nicht erfolgreichen Nutzerinteraktionen führt
Einige dieser Schritte sind auch aus der gängigen Softwareentwicklung bekannt und können dort vielfach mit Konzepten der Continuous Integration (CI) und des Continous Deployments (CD) angegangen werden. Diese können jedoch auch größtenteils in die Entwicklung von Chatbots überführt werden.
Beispielsweise lassen sich Tests automatisiert durchführen, wann immer Änderungen am Code (oder an den Daten) in ein beliebiges Versionsverwaltungssystem eingecheckt werden. Sofern diese Tests erfolgreich sind, kann dann ein Deployment ausgerollt werden um die Änderungen den Nutzern zur Verfügung zu stellen. Dies ist im Kontext von Chatbots insofern besonders nützlich, da somit die Feedback-Loop zwischen Entwickler und Anwender die größtmögliche Anzahl an Iterationen liefert. Das heißt die Änderungen werden nach initialer Prüfung direkt von echten Nutzern getestet und etwaige Fehler können ebenso schnell behoben werden.
Mit wachsendem Umfang des Chatbots wird auch die Menge an Daten entsprechend skalieren. Um hier den Überblick nicht zu verlieren, sollte bereits zu Beginn des Projekts darauf geachtet werden, Domänen und Funktionalitäten zu kapseln und in eigene Dateien auszulagern. Rasa bietet die einfache Möglichkeit innerhalb der mit rasa init vorgegebenen Ordnerstruktur Unterordner und -Dateien anzulegen um die Ordnung zu wahren.
Rasa X
Rasa X dient als visuelle Ergänzung zur zugrunde liegenden Funktionalität von Rasa. Mithilfe dieser UI ist es einfach möglich, Kundeninteraktionen mit dem Chatbot zu bewerten und zu labeln, gänzlich neue Trainingsdaten und Szenarien zu generieren und eine interaktive Testumgebung zu starten. Das eignet sich insbesondere zur Einbeziehung von Domänenexperten, welche nicht aus einem technischen Umfeld stammen. Besonders in Bereichen wie dem Kundensupport, Vertrieb oder Verwaltungsangelegenheiten ist dies ein hilfreiches Mittel, um den fachlichen Experten eine Möglichkeit zu geben, aktiv an der Entwicklung teilzuhaben. Mögliche Lücken und Fehler des Chatbots können so bereits schon in den ersten Iterationen effizient erkannt und ausgebessert werden. Wie eingangs bereits erwähnt, können so auch erste innerbetriebliche Testdaten gesammelt werden, bevor der Chatbot produktiv geschaltet wird.
Fazit
In dieser Artikelreihe wurden grundlegende Konzepte und Begriffe im Chatbot-Umfeld näher beleuchtet und die Architektur moderner Chatbots vorgestellt. Anhand des Frameworks Rasa wurden die theoretischen Grundlagen mit einer praktischen Implementation verknüpft. Die vorgestellten Best Practices ermöglichen eine schnelle und iterative Entwicklung.
Chatbots bieten somit eine interessante Möglichkeit wiederkehrende Kundenanfragen zu automatisieren, um eine hochverfügbare und effiziente Kommunikationsplattform zu entwickeln.
Falls Ihr Interesse geweckt wurde zögern Sie nicht uns zu kontaktieren, denn am liebsten sprechen wir natürlich immer noch persönlich mit Ihnen! ;-)
Kommentare