
Traue keiner Statistik, die du nicht selbst gefälscht hast: Ausführungspläne bei MySQL 8.0.18
Die Erstellung von Ausführungsplänen für SQL-Statements bei MySQL ist ein alter Hut. Anhand des Beispielschemas „sakila" wird hier im Folgenden für einen einfachen Join ein solcher Plan erstellt:
mysql> explain select title, last_name from film f, film_actor fa, actor a where f.film_id = fa.film_id and a.actor_id = fa.actor_id; +----+-------------+-------+------------+--------+------------------------+---------------------+---------+-------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+------------------------+---------------------+---------+-------------------+------+----------+-------------+ | 1 | SIMPLE | a | NULL | index | PRIMARY | idx_actor_last_name | 137 | NULL | 200 | 100.00 | Using index | | 1 | SIMPLE | fa | NULL | ref | PRIMARY,idx_fk_film_id | PRIMARY | 2 | sakila.a.actor_id | 27 | 100.00 | Using index | | 1 | SIMPLE | f | NULL | eq_ref | PRIMARY | PRIMARY | 2 | sakila.fa.film_id | 1 | 100.00 | NULL | +----+-------------+-------+------------+--------+------------------------+---------------------+---------+-------------------+------+----------+-------------+ 3 rows in set, 1 warning (0,00 sec)
Auch die Tatsache, dass sich Ausführungspläne mittlerweile in anderen Formaten (TREE & JSON) darstellen lassen, dürfte sich rumgesprochen haben:
mysql> explain format=json select title, last_name from film f, film_actor fa, actor a where f.film_id = fa.film_id and a.actor_id = fa.actor_id;
...
+----+-------------+-------+------------+--------+------------------------+---------------------+---------+-------------------+------+----------+-------------+
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "2529.43"
},
"nested_loop": [
{
"table": {
...
"rows_examined_per_scan": 200,
"rows_produced_per_join": 200,
"filtered": "100.00",
...
Bis zur Version 8.0.10 basieren die Informationen eines Ausführungsplans auf Schätzungen und stellen damit so etwas wie eine Prognose da. Natürlich werden vom Optimizer für diese Prognose zahlreiche vorhandene Daten und Statistiken herangezogen, um die Qualität der Vorhersage möglichst optimal zu gestalten.
Ist Messen besser als Schätzen?
Mit der aktuellen MySQL-Version 8.0.18 können nun zusätzlich Informationen generiert werden. Die Option „analyze" ermittelt nach der Ausführung (!) des Statements einige statistische Daten (man beachte die unterschiedliche Laufzeit zur Erstellung der Ausführungspläne: Plan 1 in 0,00 Sek; Plan 2 0,39 Sek.):
- die geschätzten (!) Kosten des Optimizers
- die geschätzten, zu liefernden Zeilen (Datensätze)
- die benötigte Zeit zur Lieferung der ersten Zeile
- die benötigte Zeit zur Lieferung aller Datensätze
- die Anzahl der Zeilen je Iterator
- die Anzahl der Schleifen (Loops)
Für das oben genutzte Statement sieht ein so erstellter Plan nun wie folgt aus:
mysql> explain analyze select title, last_name from film f, film_actor fa, actor a where f.film_id = fa.film_id and a.actor_id = fa.actor_id\G
*************************** 1. row ***************************
EXPLAIN: -> Nested loop inner join (cost=2529.43 rows=5462) (actual time=0.124..358.222 rows=5462 loops=1)
-> Nested loop inner join (cost=617.73 rows=5462) (actual time=0.093..120.718 rows=5462 loops=1)
-> Index scan on a using idx_actor_last_name (cost=20.25 rows=200) (actual time=0.049..2.368 rows=200 loops=1)
-> Index lookup on fa using PRIMARY (actor_id=a.actor_id) (cost=0.27 rows=27) (actual time=0.026..0.331 rows=27 loops=200)
-> Single-row index lookup on f using PRIMARY (film_id=fa.film_id) (cost=0.25 rows=1) (actual time=0.019..0.023 rows=1 loops=5462)
1 row in set (0,39 sec)
Pro Ausführungsschritt werden nun detaillierte Statistiken generiert. Im ersten Schritt erfolgt jeweils ein Zugriff auf die Tabellen „a" (Alias für „actor") und „fa" (Alias für „film_actor") über verfügbare Indices.
Schaut man sich die beiden Indexzugriffe (Index scan… und Index lookup…) an, so lässt sich erkennen, dass der erste Satz der Tabelle „a" bereits nach 0.049 Millisekunden geliefert wurde.
„Die Lieferung" aller 200 Sätze hat hingegen 2.368 Millisekunden gedauert. Mit den ermittelten 200 Indexwerten dieser Tabellen wurde dann über eine Schleife (Nested Loop) auf die Tabelle „fa" (Alias für film_actor) zugegriffen. Die gesamte Laufzeit dafür betrug 0,331 Millisekunden (der erste Wert wurde bereits nach 0,026 Millisekunden geliefert). Der Plan kann so von unten nach oben gelesen werden.
Im letzten Schritt (der obersten Zeile) wird letztendlich die Gesamtlaufzeit präsentiert. In Summe wurden 5.462 Zeilen in 358 Millisekunden oder 0,36 Sekunden geliefert. Aber stimmt dies auch?
Über eine Schleife wurde für das oben stehende Statement abwechselnd der Zeitwert des Ausführungsplans und die Zeit der tatsächlichen Ausführung ermittelt. Die Ergebnisse für ein eher kurz laufendes SELECT waren leider eher ernüchternd:
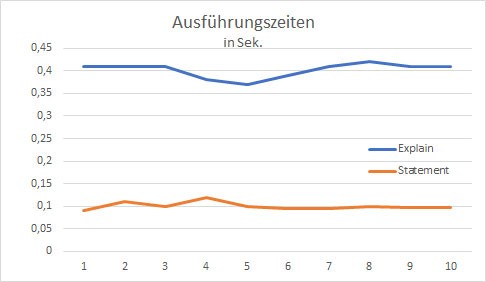
Die vom Ausführungsplan ermittelten Zeiten waren in dieser kleinen Messreihe deutlich (ca. Faktor 3) größer als die tatsächlichen Ausführungszeiten. Diese Abweichungen ließen sich auch mit weiteren Statements noch gravierender reproduzieren:
mysql> select * from actor; ... | 199 | JULIA | FAWCETT | 2006-02-15 04:34:33 | | 200 | THORA | TEMPLE | 2006-02-15 04:34:33 | +----------+-------------+--------------+---------------------+ 200 rows in set (0,00 sec) mysql> explain analyze select * from actor; +--------------------------------------------------------------------------------------------+ | EXPLAIN | +--------------------------------------------------------------------------------------------+ | -> Table scan on actor (cost=20.25 rows=200) (actual time=0.094..1.1541 rows=200 loops=1) | +--------------------------------------------------------------------------------------------+ 1 row in set (0,01 sec)
Hier liegt die Differenz zwischen der Ausführungszeit von gerundeten 0,00 Sekunden (oben) und fast 1,2 Sekunden (unten) die über den Ausführungsplan ermittelt worden.
Fazit: Traue keiner Statistik, die du nicht selbst überprüft hast!
Das neue "Feature" ist mit Vorsicht zu genießen. Mehr Informationen sind immer gut, wenn man auf der Suche nach Performanceproblemen ist. Leider nützt es nichts, wenn man sich auf die Daten nicht verlassen kann. Es bleibt zu hoffen, dass es hier in den nächsten Versionen zu Verbesserungen und/oder zumindest zu Erklärungen für dieses Verhalten kommt.
Sie haben Fragen rund um das Thema von Datenbank-Performance? Dann sprechen Sie mit uns.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema MySQL? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren MySQL Seminaren
Principal Consultant bei ORDIX
Kommentare