
Trifacta Enterprise: Wrangeln bis der Arzt kommt
Die Datenverarbeitung wird mit der steigenden Menge der Daten unter Umständen zu einer großen Herausforderung. Besonders, wenn viele Datenquellen existieren und die enthaltenen Daten für die eigentliche Verarbeitung in einer suboptimalen Form vorhanden sind. Erst nachdem eine Vorverarbeitung durchgeführt wurde, kann die eigentliche Analyse und Verarbeitung beginnen, welche dann den Mehrwert mit sich bringt. Die Realisierung einer solchen Vorverarbeitung kann je nach Datenquelle und Datenstruktur sehr zeitaufwändig werden. Trifacta ist eine Applikation, welche genau das realisieren kann, und dafür sind noch nicht einmal Programmierkenntnisse erforderlich.
Einleitung
Dieser Blogartikel beschäftigt sich mit Trifacta in der Version 7.6, welche am 04.09.2020 veröffentlicht wurde. Während der Erstellung dieses Artikels ist dies die aktuelle Version.[1]
Zuerst wird auf das sogenannte Wrangling eingegangen. Dies ist ein von den Gründern von Trifacta eingeführter Begriff, welcher den Vorgang der Datenvorverarbeitung beschreibt.[2] Danach wird auf einen Auszug der Software-Komponenten eingegangen, aus denen Trifacta besteht, um einen kleinen Überblick über die Architektur zu bekommen.
Darüber hinaus können genauere Informationen über Trifacta Enterprise in (1) nachgeschlagen werden.
Trifacta Enterprise: Wrangling
- Connections
- Datasets
- Recipes
- Outputs
- Flows
Bevor eine Verarbeitung der Daten stattfinden kann, müssen die Verarbeitungsschritte definiert werden. Diese können auch als Transformationsschritte bezeichnet werden. Dies findet in sogenannten Recipes statt. In so einem Recipe können auf den Daten Operationen ausgeführt werden. Dafür wird die Wrangle Language verwendet, welche eine domänenspezifische Sprache ist, und extra für die Datentransformation entwickelt wurde. Dabei werden verschiedene Bereiche abgedeckt. Die Vielfalt reicht von mathematischen und trigonometrischen Funktionen über Aggregatfunktionen bis hin zu Funktionen, welche sich auf z.B. Strings und Timestamps beziehen. [2] Die Liste der verschiedenen Gruppen ist lang und das hier ist auch nur ein Auszug. Die definierten Schritte können entweder auf die Daten eines Datasets angewendet werden oder auf das Ergebnis eines anderen Recipes. Heißt also, dass z.B. mehrere Recipes in einer sequenziellen Kette verbunden werden können. Somit obliegt es dem Anwender, ob alles in einem Recipe definiert oder aber eine Verteilung der Transformationsschritte auf verschiedene Recipes vorgenommen werden soll, welche dann miteinander verbunden werden.
Nach der Durchführung der Verarbeitungsschritte soll das Ergebnis in der Regel persistiert werden. Dafür können die Outputs verwendet werden, welche direkt auf einem Recipe folgen. Dort wird festgelegt, wo das Ergebnis gespeichert werden soll. Dabei können die vorher besprochenen Connections verwendet werden, um z.B. eine Tabelle in MySQL, eine Datei im HDFS oder aber eine Tabelle in Hive zu definieren, in der die Daten dann gespeichert werden.
Über die Outputs kann die Verarbeitung manuell gestartet werden. Dann wird eine Jobgroup gestartet, welche i.d.R. 2 Jobs enthält. Der erste Job ist die Transformation und der zweite Job ist das Publishen in das in dem Output definierte Ziel. Darüber hinaus existieren noch ein Profile Job, welcher statistische Auswertungen von der Transformation erstellt, und ein Ingestion Job, der dafür sorgt, dass die Daten für die Verarbeitung zuerst in das verarbeitende System gebracht werden, bevor der Transformationsjob startet. Das Profiling kann durch den Anwender aktiviert werden und die Ingestion wird nur bei bestimmten Datenquellen gestartet. Als Beispiel sei z.B. MS SQL genannt. Neben der manuellen existiert noch die Möglichkeit einer zeitgesteuerten Ausführung, welche für den produktiven Betrieb einer Verarbeitung interessant ist.
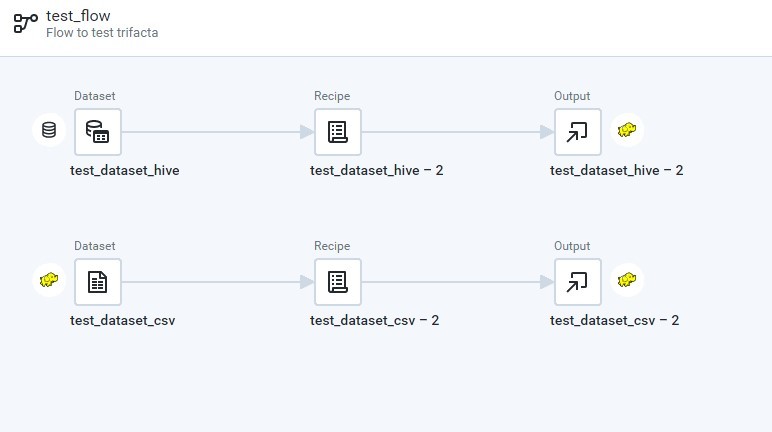
Damit Recipes und Outputs erstellt werden können, werden Flows benötigt. Man kann einen Flow wie einen Container verstehen, welcher Datasets, Recipes und Outputs zusammen gruppiert. Somit muss erst ein Flow erstellt werden, damit darin dann die Datasets hinzugefügt, die Recipes definiert und die Outputs erstellt werden können. Als Beispiel sei auf Abbildung 1 verwiesen. Diese enthält zwei Verarbeitungsketten, welche jeweils aus einem Dataset, einem Recipe und einem Output bestehen. Dabei wird einmal eine CSV-Datei im HDFS als Dataset verwendet und einmal eine Hive-Tabelle. Das Ergebnis soll dann jeweils in eine CSV-Datei im HDFS publiziert werden.
Bevor jetzt der Eindruck entsteht, dass Wrangle Language und Funktionen stark an Programmierung erinnern, kann ich hier mitteilen, dass diese Transformationsschritte komplett über das User Interface definiert werden können, sodass eine klassische Programmierung über ein leeres Textfeld bzw. eine leere Datei nicht nötig ist. Einen Eindruck über das User Interface vermittelt Abbildung 2. Dort ist die Transformation Page zu sehen, welche betrachtet werden kann, wenn ein Recipe geöffnet wird. Dort wird dann ein Auszug der Daten angezeigt, welcher durch sogenannte Samples definiert wird. Jeder hinzugefügte Transformationsschritt wird sofort auf das Sample angewendet und das Ergebnis dem Anwender präsentiert. Es können auch neue Samples nach bestimmten Kriterien neu zusammengestellt werden, sodass die Transformationsschritte optimal auf Basis der Daten geprüft werden können.
Somit schafft Trifacta die Möglichkeit, einfach ganze Transformationsprozesse zu definieren und dann auch noch diese auszuführen. Der Anwender benötigt nur einen Webbrowser, um sich mit Trifacta Enterprise zu verbinden. Dabei werden Chrome und Firefox unterstützt.[3]
Architektur
- Webapp Service
- Data Service
- Photon
- Spark Job Runner
- Optimizer Service
Zusammenfassung
In diesem Blogartikel sollte ein kleiner Einblick gegeben werden, wozu Trifacta verwendet werden kann und wie einfach Verarbeitungsschritte definiert werden können. Damit eignet sich diese Applikation auch für Personen, welche nicht programmieren können und trotzdem schnell Verarbeitungsstrecken realisieren wollen. Darüber hinaus ist die Architektur von Trifacta so gewählt, dass Probleme einfach mit den jeweiligen Logdateien analysiert und über die Dienstaufteilung einfacher eingegrenzt werden können. Somit ist Trifacta auch für Administratoren angenehm zu betreiben.
Abbildungen
Kommentare