
Variablen? Parameter? Was denn nun? Wie ein Dataflow in Apache NiFi parametrisiert wird
Wie in jeder Programmiersprache ergibt es auch in Apache NiFi Sinn, einen Dataflow zu parametrisieren. Allerdings gibt es in NiFi zwei Möglichkeiten: Variablen und die relativ neuen Parameter.
Was die Unterschiede und Vorteile sind und warum Parameter genutzt werden sollten, klären wir in diesem Blogartikel.
Wie in jeder Programmiersprache und generell in der IT, ist es auch in Apache NiFi sinnvoll, einen Dataflow zu parametrisieren. Daher verwundert es nicht, dass es schon seit den ersten Versionen von NiFi die Möglichkeit gibt, Variablen zu nutzen.
Diese bringen bekannte Vorteile mit sich. So muss ein Wert nur an einer Stelle definiert werden, kann aber von beliebig vielen Prozessoren genutzt werden. Weiterhin stehen die Werte während eines Flow Rollouts in eine andere Umgebung (z.B. von Dev nach Prod) nicht „hard-coded" in einem Prozessor.
Wird auch das NiFi Versionierungstool "NiFi Registry" verwendet, ist die Nutzung von Variablen eigentlich unverzichtbar.
Ändert sich der Wert einer Variable, wie z.B. ein Datenbankname, bringt diese Änderung keine neue Flow-Version mit sich, da lediglich der referenzierte Variablenwert verändert wird und nicht der Wert im Prozessor.
Also alles gut?
Um das zu beantworten, schauen wir uns zunächst die Eigenschaften von Variablen näher an.
Variablen haben einen bestimmten "Scope". Sie sind auf der Ebene, auf der sie angelegt wurden und allen darunter liegenden Ebenen verfügbar. Das bedeutet sie werden an Kind-Prozessgruppen vererbt. Wird in einer Kind-Prozessgruppe eine Variable mit dem gleichen Namen angelegt, so wird dieser Wert genutzt und der Wert, der darüber liegenden Prozessgruppe wird überschrieben.
In einem Prozessor können wir eine Variable nutzen, sofern dieser das VariableRegistry unterstützt.
Soll der Prozessor auf eine Variable zugreifen, kann auf diese mit ${var-name} referenziert werden.
Es gilt also die gleiche Schreibweise, wie wenn auf ein FlowFile-Attribut zugegriffen werden soll.
Good to know: Gibt es ein FlowFile-Attribut und eine Variable mit dem gleichen Namen, nutzt ein Prozessor immer das FlowFile-Attribut
Zunächst scheinen Variablen allen gängigen Anforderungen gerecht zu werden. Es wird allerdings problematisch, sobald Passwörter verwaltet werden sollen. Variablen speichern Werte im Klartext ab. Das bedeutet, dass in Variablen auf keinen Fall Passwörter gespeichert werden sollten.
Parameter, die besseren Variablen?
Mit der Version 1.10.0 wurde erstmals die Funktion eines Parameter Contexts eingeführt. Dieser Context hat es sich zu Aufgabe gemacht, die Schwächen von Variablen zu beseitigen. Insbesondere die Klartextdarstellung von Passwörtern passte nicht ins Bild des sonst auf Sicherheit bedachten Apache Projektes.
Ein Parameter Context benötigt zunächst einen eigenen Namen und zusätzlich kann eine Beschreibung hinzugefügt werden. Hier sollten hilfreiche Informationen hinterlegt sein:- Wo wird dieser Context genutzt?
- Wen kann man bei Problemen kontaktieren?
- Welche Informationen enthält der Context?
- …
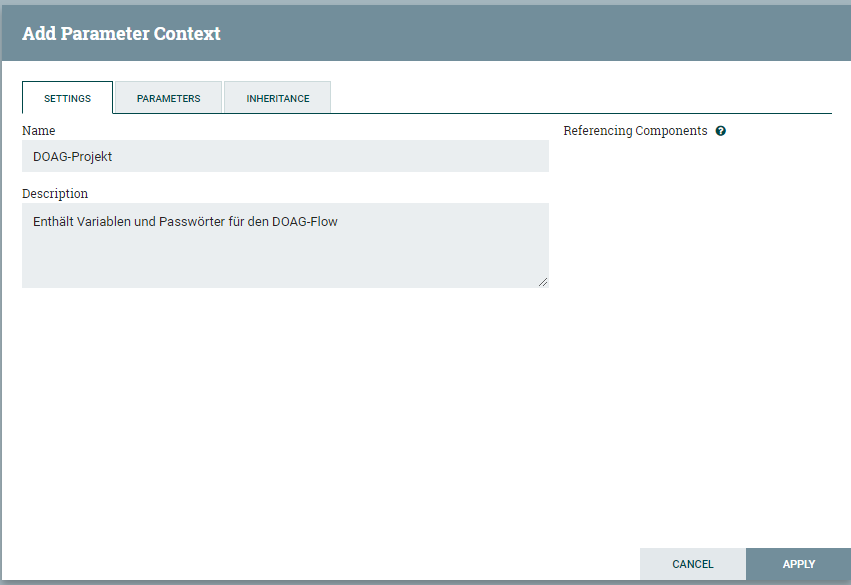
Wurde ein Parameter Context angelegt, können Parameter hinzugefügt werden. Diese unterscheiden sich in zwei Kategorien: Sensitive und nicht-sensitive Parameter.
Die sensitiven Parameter enthalten typischerweise sensitive Werte, wie Passwörter und können nur in Feldern genutzt werden, in denen ein sensitiver Wert erwartet wird! Umgekehrt enthalten nicht-sensitive Parameter unkritische Werte wie Datenbank- oder Tabellennamen. Diese ersetzen die eigentlichen Variablen. Die nicht-sensitiven Parameter können auch nur in nicht-sensitiven Feldern genutzt werden.
Zusätzlich zu dem Parameternamen, dem Wert und der Einstellung, ob es sich um einen sensitiven oder nicht-sensitiven Wert handelt, kann jedem Parameter eine zusätzliche Beschreibung hinzugefügt werden. So kann bei einem Passwort die Information hinzugefügt werden, wann es abläuft oder für welche Umgebung es genutzt werden kann.
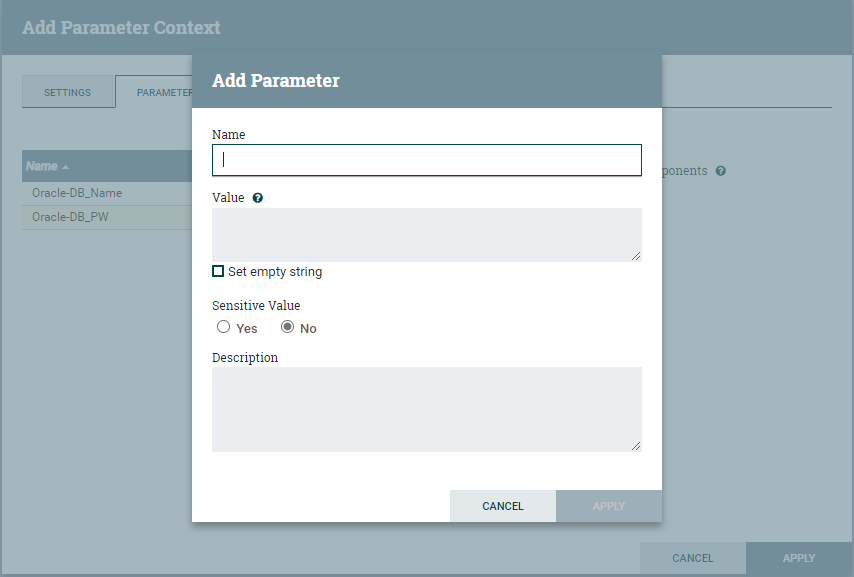
Wurde ein Parameter Context mit den gewünschten Parametern erstellt, so kann dieser einer oder mehreren Prozessgruppen zugewiesen werden. Das geschieht über die Einstellungen der jeweiligen Prozessgruppe.
Hier gab es lange zwei große Probleme:- Eine Prozessgruppe kann nur einen Parameter Context besitzen!
- Ein Parameter Context wird nicht an die Kind-Prozessgruppen vererbt.
Zugriff! Parameter nutzen
Auf Parameter kann in allen Feldern zugegriffen werden, in denen die NiFi Expression Language unterstützt wird. Dies ist eine bedeutend höhere Zahl als die Anzahl der Felder, die auf das Variable Registry zugreifen können.
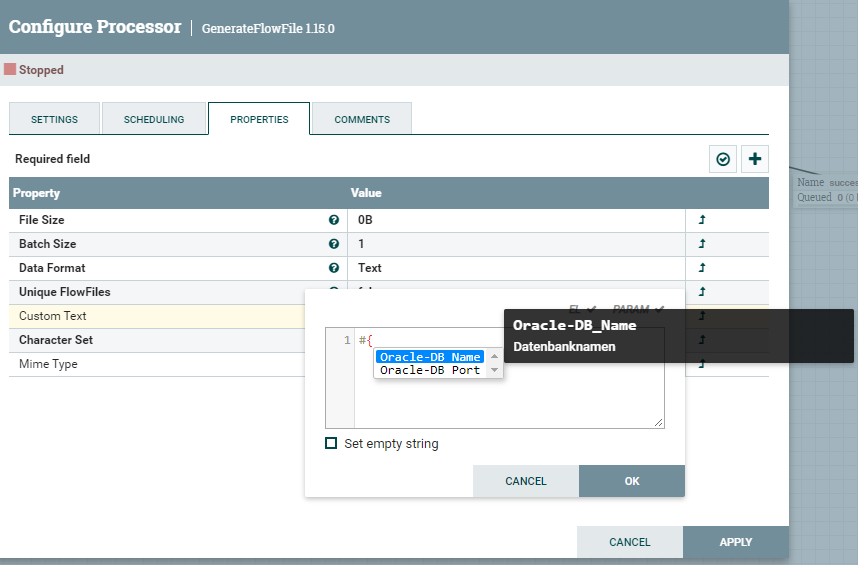
Soll ein Prozessor auf einen Wert zugreifen, so geschieht dies mit dem Ausdruck #{param-name} .
NiFi unterstützt bei Parametern auto-complete. Als Entwickler eines DataFlows erleichtert dies die Arbeit ungemein und Tippfehler bei "Variablen" gehören der Vergangenheit an.
Die folgende Abbildung zeigt die Verwendung der Parameter. Mit Strg + Space lässt sich die auto-complete Funktion nutzen.
Und jetzt?
Spätestens mit der NiFi Version 1.15.0 ist es Zeit, sich von Variablen zu verabschieden und Parameter Contexts zu nutzen!
Es verwundert daher auch nicht, dass seit Erscheinen des Parameter Contexts in der Dokumentation folgender Satz zu finden ist:
Variables (...) are still supported for compatibility purposes but do not have the same power as Parameters such as support for sensitive properties (...).
https://nifi.apache.org/docs/nifi-docs/html/user-guide.html#Variables
Haben Sie Apache NiFi bereits im Einsatz, oder planen es? Sprechen Sie uns gerne an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren

MeetUp: Apache NiFi Germany
Tipp: Für den fachlichen Austausch empfehlen wir außerdem die MeetUp-Gruppe „Apache NiFi Germany“:
Senior Consultant bei ORDIX
Kommentare