
Joins über mehrere Datenbanksysteme - Was kann Apache NiFis LookUp-Prozessor?
Datenquellen wachsen und vermehren sich ständig, egal ob im Internet oder im eigenen Unternehmen. Daten fallen an verschiedenen Stellen und in verschiedenen Formaten an. Um diese Daten sinnvoll zu nutzen, müssen sie oftmals an zentralen Stellen (z.B. in Data Warehouses) zusammengeführt werden.
Doch wie führt man die Daten aus vielen verschiedenen Datenbanken und Datenbanksystemen, egal ob relational oder NoSQL, in eine einzige Data-Warehouse-Datenbank zusammen?
Eine Lösung liefert die Software „Apache NiFi", dessen Haupteinsatzzweck das Automatisieren von Daten-Strömen zwischen Systemen ist. Im Folgenden gehen wir auf einen NiFi-Workflow zum Übertragen von Daten ein. Einen besonderen Fokus legen wir dabei auf den LookUp-Prozessor, der Joins über mehrere Datenbanksysteme ermöglicht und das obenstehende Problem lösen kann.
NiFi-Flow
Um die Funktionsweise des LookUp-Prozessors zu veranschaulichen, haben wir den folgenden Use Case beispielhaft aufgebaut: Ziel soll es sein, zwei MySQL-Tabellen mit einer MongoDB (NoSQL Datenbank) zu vereinen. Die verbundenen, angereicherten Datensätze sollen dann in eine zusätzliche MySQL Tabelle geschrieben werden.
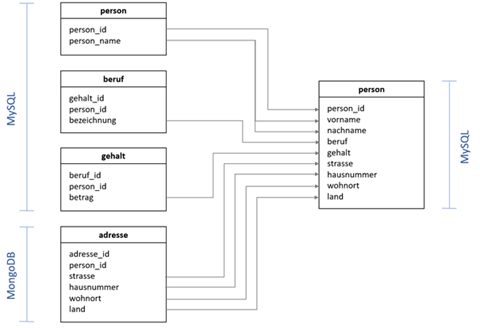
In der MySQL Datenbank gibt es drei Tabellen "person", "beruf" und "gehalt". Die MongoDB enthält die Collection "adresse". Eine Collection entspricht bei MongoDB in etwa einer Tabelle eines klassischen RDBMS (relationales Datenbankmanagementsystem).
Diese Datensätze sollen anhand der Spalte "person_id" verknüpft und als eine Tabelle "person", in einer anderen MySQL-DB geschrieben werden.
Der folgende NiFi-Flow soll die Daten transformieren:
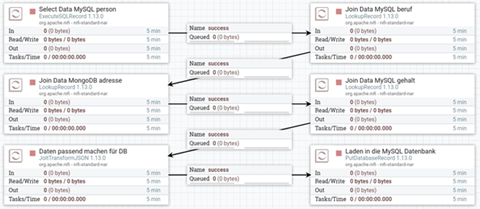
Zu Beginn selektieren wir die Personendaten aus der MySQL-Quelldatenbank. Die entstandenen FlowFiles werden nacheinander, an die nächsten drei Prozessoren, die "LookUpRecord"-Prozessoren, weitergegeben. Jeder LookUpRecord fügt eine Zeile zu den FlowFiles hinzu, so dass pro Prozessor die FlowFiles, um eine Datenbankzeile (also jeweils den passenden Eintrag, in dem sich die Attribute "person_id" gleichen) ergänzt werden. Das bedeutet: Der erste LookUp-Prozessor fügt den Personendaten noch den Beruf hinzu.
Mittels einer Jolt-Transformation werden die JSON-Daten formatiert. Ein Jolt-Prozessor kann Daten im JSON-Format konvertieren und verändern. In unserem Fall dient dies dem einfacheren Abspeichern der Daten.
LookUp-Prozessor
Der Lookup-Prozessor ermöglicht es uns, Daten aus weiteren Tabellen oder Dokumenten, mit unseren vorhandenen Daten aus dem vorigen Prozessor zu vereinen. Dies kann man sich ähnlich vorstellen, wie eine "Join" in relationalen Datenbanken, nur eben über beliebige kompatible Datenbanksysteme.
In unserem Fall werden anhand der Spalte "person_id" (unser Primärschlüssel, durch den die Tabellen "gehalt", "beruf" und "adresse" mit "person" verknüpft werden) die Ergebnisse zusammengeführt.
Schauen wir uns die Konfiguration an (hier für das Zusammenfassen von MySQL und MongoDB-Tabellen):
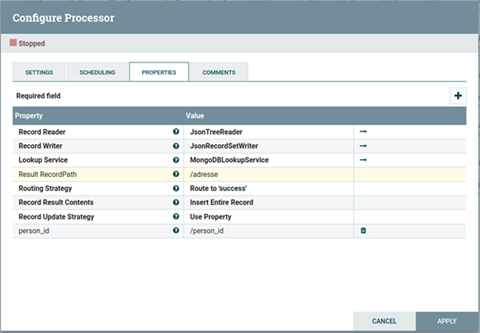
Zuerst geben wir "Record Reader" und -"Writer" an. Diese können den Inhalt der FlowFiles lesen und wieder neu schreiben. In diesem Fall nutzen wir JSON als Format.
Dank der LookUp-Services können wir eine Verbindung zur MongoDB herstellen.
Durch die "Propery Result RecordPath" können wir die Tabelle bzw. die Collection einstellen, die wir zu den bestehenden Datensätzen hinzufügen wollen. In diesem Fall sprechen wir die Collection "adresse" an.
Die Quelldaten kommen aus der MySQL-Datenbank und wurden bereits durch vorherige Prozessoren in NiFi geladen. Jede Zeile findet sich in einem FlowFile wieder.
Der LookUp-Prozessor kann mithilfe des JsonTreeReaders auf den Inhalt der FlowFiles zugreifen und dadurch das Attribut "person_id" im Content des FlowFiles lesen.
Es wird nun die Collection "adresse" durchsucht. Gibt es dort einen Eintrag mit der gleichen "person_id", wie im FlowFile, werden die Daten zusammengeführt.
Zusammenfassung
Wie wir gesehen haben, lassen sich mithilfe des LookUp-Prozessors, Tabellen verschiedenster Datenbanksysteme, anhand eines Primärschlüssels vereinen. Man kann also von Join-Abfragen über mehrere Datenbankmanagementsysteme sprechen. Wir können dadurch Tabellen so zusammenfassen, dass sich die Daten je nach Wunsch bestmöglich analysieren lassen.
Haben Sie weitere Fragen zu LookUp Prozessoren und Apache NiFi? Sprechen Sie uns an, oder nehmen Sie an unserem kostenlosen Webinar teil.
APACHE NiFi KOSTENLOSES WEBINAR - W-NIFI-01
Zum Seminar
MeetUp: Apache NiFi Germany
Tipp: Für den fachlichen Austausch empfehlen wir außerdem die MeetUp-Gruppe „Apache NiFi Germany“:

Student bei ORDIX
Kommentare